本文主要是介绍中国城镇化时空分异及影响因素数据集(2010-2020),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
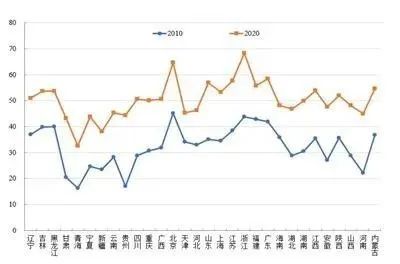
基于《中国统计年鉴》、各省份统计年鉴及EPS全球统计数据库等相关统计数据,从人居生活、人文环境、人城关系等维度界定了城镇化内涵框架与指标体系,利用改进的熵值法计算综合评价指数,并运用泰尔指数、方差分解及地理探测器等方法,研发得到中国城镇化时空分异及影响因素数据集。该数据集内容包括2010-2020年间的以下数据:(1)中国城镇化演变趋势;(2)中国30个省区城镇化及分维度得分;(3)中国城镇化泰尔指数及分解;(4)中国城镇化区域差异的贡献率变化;(5)中国城镇化空间分异的直接作用力;(6)中国城镇化空间分异的间接作用力。该数据集存储为.xlsx格式,1个数据文件,数据量为28 KB。该数据集的分析研究成果拟发表在《地理学报》2023年78卷第4期。
作者:李汝资、黄晓玲、刘耀彬
机构:南昌大学中国中部经济社会发展研究中心
南昌大学经济管理学院
中国地质大学(武汉)经济管理学院
数据引用方式:
李汝资, 黄晓玲, 刘耀彬*. 中国城镇化时空分异及影响因素数据集(2010-2020)[J/DB/OL]. 全球变化数据仓储电子杂志(中英文), 2023. https://doi.org/10.3974/geodb.2023.03.03.V1.
原文链接:【数据分享】中国城镇化时空分异及影响因素数据集(2010-2020)#1数据摘要基于《中国统计年鉴》、各省份统计年鉴及EPS全球统计数据库等相关统计数据,从人居生活、人文环境、![]() https://mp.weixin.qq.com/s?__biz=MzU0MDQ3MDk3NA==&mid=2247566282&idx=2&sn=95857f5bb3833da48fdf64c767cd46af&chksm=fb3b381bcc4cb10df1053a3ab1908c4c3a663759910e8c4c85d533c7e6c19288f1fabbee952c&token=2102588993&lang=zh_CN#rd
https://mp.weixin.qq.com/s?__biz=MzU0MDQ3MDk3NA==&mid=2247566282&idx=2&sn=95857f5bb3833da48fdf64c767cd46af&chksm=fb3b381bcc4cb10df1053a3ab1908c4c3a663759910e8c4c85d533c7e6c19288f1fabbee952c&token=2102588993&lang=zh_CN#rd
这篇关于中国城镇化时空分异及影响因素数据集(2010-2020)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






