本文主要是介绍DPDK 无锁环形队列(Ring)详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
DPDK 无锁环形队列(Ring)

此篇文章主要用来学习和记录DPDK中无锁环形队列相关内容,结合了官方文档说明和源码中的实现,供大家交流和学习。
- Author : Toney
- Email : vip_13031075266@163.com
- Date : 2020.11.8
- Copyright : 未经同意不得转载!!!
- version : dpdk-2.2.0
文章目录
- DPDK 无锁环形队列(Ring)
- @[TOC]
- 1. DPDK中的环形数据结构
- 2. 环形队列:单生产者/单消费者模式
- 2.1 生产者--入队
- 2.2 消费者--出队
- 3. 环形队列:多生产者/多消费者模式
- 3.1 多生产者--入队
- 3.2 多消费者--出队
- 参考文献:
文章目录
- DPDK 无锁环形队列(Ring)
- @[TOC]
- 1. DPDK中的环形数据结构
- 2. 环形队列:单生产者/单消费者模式
- 2.1 生产者--入队
- 2.2 消费者--出队
- 3. 环形队列:多生产者/多消费者模式
- 3.1 多生产者--入队
- 3.2 多消费者--出队
- 参考文献:
1. DPDK中的环形数据结构
DPDK中的环形结构经常用于队列管理,因此又称为环形队列。它不同于大小可灵活变化的链表,它的空间大小是固定的。
-
DPDK中的rte_ring拥有如下特性:
-
它是一种FIFO(First In First Out)类型的数据结构;
-
无锁;
-
多消费者、单消费者出队;
-
多生产者、单生产者入队;
-
批量出队;
-
批量入队;
-
全部出队;
-
全部入队;
-
rte_ring环形队列与基于链表的队列相比,拥有如下优点:
-
速度更快,效率更高;
- rte_ring只需要一个CAS指令,而普通的链表队列则需要多个双重CAS指令
-
相对于普通无锁队列,实现更加简洁高效
-
支持批量入队和出队;
- 批量出队并不会像链氏队列一样,产生很多的Cache Miss
- 此外批量出队和单独出队在花费上相差无几
-
rte_ring环形队列与基于链表的队列相比,缺点如下:
-
rte_ring环形队列大小固定;
-
rte_ring需要提前开辟空间,在未使用的情况下更容易造成内存的浪费;
-
rte_ring的应用场景主要包括两类:
-
DPDK应用之间进行通讯
-
内存池分配
-
rte_ring环形队列描述:
-
环形队列可以简单的用下图来描述:
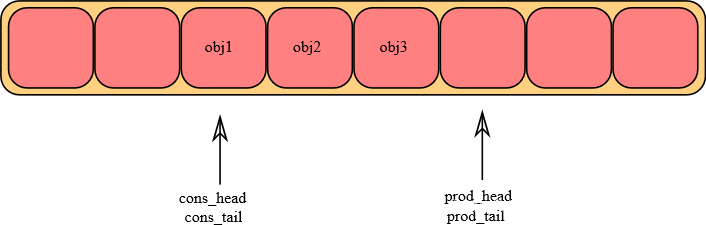
- DKDP源码中的环形队列数据结构如下:
struct rte_ring {char name[RTE_RING_NAMESIZE]; /**< Name of the ring. */int flags; /**< Flags supplied at creation. */const struct rte_memzone *memzone;/**< Memzone, if any, containing the rte_ring *//** Ring producer status. */struct prod {uint32_t watermark; /**< Maximum items before EDQUOT. */uint32_t sp_enqueue; /**< True, if single producer. */uint32_t size; /**< Size of ring. */uint32_t mask; /**< Mask (size-1) of ring. */volatile uint32_t head; /**< Producer head. */volatile uint32_t tail; /**< Producer tail. */} prod __rte_cache_aligned;/** Ring consumer status. */struct cons {uint32_t sc_dequeue; /**< True, if single consumer. */uint32_t size; /**< Size of the ring. */uint32_t mask; /**< Mask (size-1) of ring. */volatile uint32_t head; /**< Consumer head. */volatile uint32_t tail; /**< Consumer tail. */} cons __rte_cache_aligned;void * ring[0] __rte_cache_aligned; /**< Memory space of ring starts here.* not volatile so need to be careful* about compiler re-ordering */
};
每一个环形数据结构都包含两对(head,tail)指针:一对用于生产者(prod),另一队用于消费者(cons)。文章后面通过prod_head, prod_tail, cons_head, cons_tail来分别表示这四个指针。
head,tail的范围都是0~2^32;,它恰恰是利用了unsigned int 溢出的性质。
在DPDK实现中,rte_ring是通过**“name”**字段来唯一标识的,我们可以通过rte_ring_create()来创建环形队列,他可以保证创建的队列name的唯一性。
2. 环形队列:单生产者/单消费者模式
本节内容主要为单生产者下的入队操作以及单消费者下的出队操作。
为了方便后续表达和理解,这里有必要统一一下描述:
| 序号 | 变量名称 | 含义 |
|---|---|---|
| 1 | g_prod_head | 环形队列中生产者head |
| 2 | g_prod_tail | 环形队列中生产者tail |
| 3 | g_cons_head | 环形队列中消费者head |
| 4 | g_cons_tail | 环形队列中消费者tail |
| 5 | l_prod_head | 临时变量中生产者head |
| 6 | l_prod_tail | 临时变量中生产者tail |
| 7 | l_cons_head | 临时变量中消费者head |
| 8 | l_cons_tail | 临时变量中生产者head |
| 9 | l_prod_next | 临时变量中prod_next |
关于临时变量可以这样理解:每一个CPU都有独占cache, 这些临时变量l_xxx_xxx则是相应CPU存储在本地cache中尚未更新到全局环形队列上的值。而g_xxx_xxx则表示存储中的共享的环形队列值。
2.1 生产者–入队
入队操作只会修改生产者的head和tail指针(即prod_head, prod_tail)。在初始状态时,prod_head和prod_tail指向相同的内存空间。
下面举一个例子:只有一个生产者的入队操作。
- 入队操作第①步
将环形队列的g_prod_head、g_cons_tail存储在临时变量l_prod_head、l_cons_tail中记录位置;临时变量l_prod_next则根据插入对象的个数移动了相应的位置。如果没有足够的空间来执行入队操作,则返回错误。

- 入队操作第②步
将环形队列的g_prod_head移动到l_prod_next的位置;然后将对象添加到环形缓冲区中。
注: l_prod_next:用来提前预定位置,g_prod_head则是真正改变环形队列指针,占用位置生效。

- 入队操作第③步
一旦对象被添加到环形队列中,g_prod_tail将会被修改,指向g_prod_head的位置。
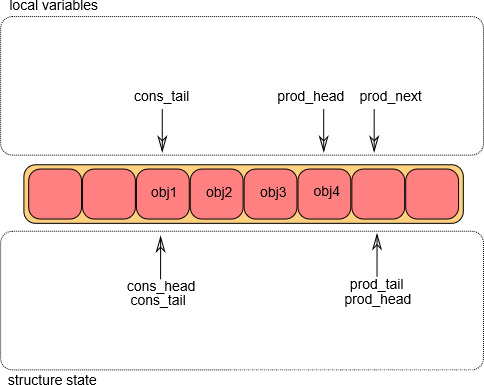
至此,入队操作完成。
说实话,只看到这段描述,是在看不出所以然,以及它的特点。下面我们通过查看源码来加深对入队操作的理解。(文字言简意赅,读不懂;代码深奥,看不懂。O(∩_∩)O哈哈~)
static inline int __attribute__((always_inline))
__rte_ring_sp_do_enqueue(struct rte_ring *r, void * const *obj_table,unsigned n, enum rte_ring_queue_behavior behavior)
{uint32_t prod_head, cons_tail;uint32_t prod_next, free_entries;unsigned i;uint32_t mask = r->prod.mask;int ret;prod_head = r->prod.head;cons_tail = r->cons.tail;/* The subtraction is done between two unsigned 32bits value* (the result is always modulo 32 bits even if we have* prod_head > cons_tail). So 'free_entries' is always between 0* and size(ring)-1. */free_entries = mask + cons_tail - prod_head;/* check that we have enough room in ring */if (unlikely(n > free_entries)) {if (behavior == RTE_RING_QUEUE_FIXED) {__RING_STAT_ADD(r, enq_fail, n);return -ENOBUFS;}else {/* No free entry available */if (unlikely(free_entries == 0)) {__RING_STAT_ADD(r, enq_fail, n);return 0;}n = free_entries;}}prod_next = prod_head + n;r->prod.head = prod_next;/* write entries in ring */ENQUEUE_PTRS();rte_smp_wmb();/* if we exceed the watermark */if (unlikely(((mask + 1) - free_entries + n) > r->prod.watermark)) {ret = (behavior == RTE_RING_QUEUE_FIXED) ? -EDQUOT :(int)(n | RTE_RING_QUOT_EXCEED);__RING_STAT_ADD(r, enq_quota, n);}else {ret = (behavior == RTE_RING_QUEUE_FIXED) ? 0 : n;__RING_STAT_ADD(r, enq_success, n);}r->prod.tail = prod_next;return ret;
}
我们依然按照刚才的三步走来说明代码:
- 入队操作第①步
第9、10行:用来保存prod_head, cons_tail变量。它的目的嘛,准备开房。
第13~34行,确定丽晶大酒店是否还有剩余房间可供咱们开!(确保环形队列剩余空间足够入队操作,如果空间不足,则提示相应信息并返回错误码)。
第36行:打电话(使用临时变量l_prod_next)预定丽晶大酒店房间的位置。
- 入队操作第②步
第37行:房间已经预定成功,可以直接开车去订好的房间(l_prod_next)。
第40行:将对象(object)拉进房间中办事
第41行:等事情办完(内存屏障)再走
- 入队操作第③步
第54行:事情已经办完,对象仍在房间回味呢,我收拾干净移步到下一个房间,继续等待另一个对象(object)的到来。
到此为止,单生产者入队完毕。我特么怀疑我自己讲了一个特别有内涵的段子,我太有才了O(∩_∩)O。
2.2 消费者–出队
本节介绍一个消费者出队操作在环形队列中如何实现的。在这个例子中,只有消费者的head、tail(即cons_head、cons_tail)会被修改。在初始状态时,cons_head和cons_tail指向相同的内存空间。
下面举一个例子:只有一个消费者的出队操作。
- 出队操作第①步
将环形队列的g_prod_head、g_cons_tail存储在临时变量l_prod_head、l_cons_tail中记录位置;临时变量l_cons_next则根据出队对象的个数移动了相应的位置。如果没有足够的对象来执行出队操作,则返回错误。

- 出队操作第②步
将环形队列的g_cons_head移动到l_cons_next的位置;然后将对象添加到环形缓冲区中。
注: l_cons_next:用来提前预定位置,g_cons_head则是真正改变环形队列指针,占用位置生效。
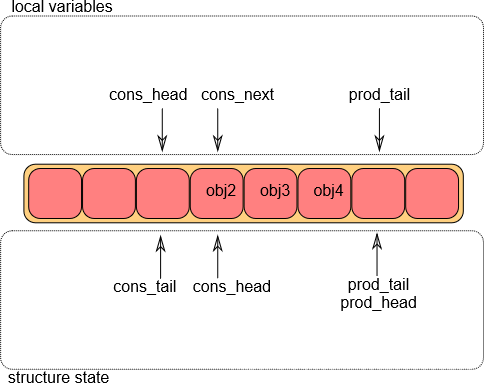
- 出队操作第③步
出队完成后,g_cons_tail将会被修改,指向g_prod_head的位置。
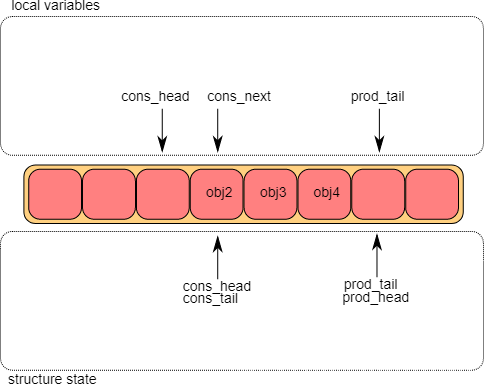
至此,但消费者的出队操作便完成了。
那接下来我们继续讲解我的小段子:
static inline int __attribute__((always_inline))
__rte_ring_sc_do_dequeue(struct rte_ring *r, void **obj_table,unsigned n, enum rte_ring_queue_behavior behavior)
{uint32_t cons_head, prod_tail;uint32_t cons_next, entries;unsigned i;uint32_t mask = r->prod.mask;cons_head = r->cons.head;prod_tail = r->prod.tail;/* The subtraction is done between two unsigned 32bits value* (the result is always modulo 32 bits even if we have* cons_head > prod_tail). So 'entries' is always between 0* and size(ring)-1. */entries = prod_tail - cons_head;if (n > entries) {if (behavior == RTE_RING_QUEUE_FIXED) {__RING_STAT_ADD(r, deq_fail, n);return -ENOENT;}else {if (unlikely(entries == 0)){__RING_STAT_ADD(r, deq_fail, n);return 0;}n = entries;}}cons_next = cons_head + n;r->cons.head = cons_next;/* copy in table */DEQUEUE_PTRS();rte_smp_rmb();__RING_STAT_ADD(r, deq_success, n);r->cons.tail = cons_next;return behavior == RTE_RING_QUEUE_FIXED ? 0 : n;
}
我们依然按照刚才的三步走来说明代码:
- 出队操作第①步
第9、10行:用来保存prod_head, cons_tail变量。它的目的嘛,事都办完了,准备退房。
第16~31行,确定丽晶大酒店开了几间房,不能多退(出队个数检查,不得超过缓冲缓冲区中存储的个数)。
第33行:打电话通知前台,准备要退的房间(使用临时变量l_cons_next记录)
- 出队操作第②步
第34行:上一个房间已退,还好我叫了好几个对象,我可以准备去下一个对象的房间(l_prod_next)。
第37行:上一个房间里的对象收拾好行李,神清气爽、精神饱满、幸福感十足的走出房间。
第38行:等这个对象真的走远,真的走远了才能行动(内存屏蔽)。
- 出队操作第③步
第41行:确认完毕方才对象真的走了,我开心的进入了下一个对象房间。
到此为止,小故事已经讲完,单消费者出队操作完毕。
3. 环形队列:多生产者/多消费者模式
关于变量命名规则可以参见第2章节。
3.1 多生产者–入队
本节将介绍两个生产者同时执行入队在环形缓冲区是如何操作的。 在这个例子中,只有一个生产者的head、tail(即cons_head、cons_tail)会被修改。在初始状态时,cons_head和cons_tail指向相同的内存空间。
- 入队操作第①步
在两个CPU上,环形队列的g_prod_head、 g_cons_tail同时被两个核存储在本地临时变量中。并同时将l_prod_next根据入队个数预定位置,并指向预留好的位置后面。

- 入队操作第②步
修改g_prod_head指向l_prod_next位置,这部分操作完成后则说明环形队列允许入队操作。该操作是通过CAS指令来完成,它和内存屏蔽是无锁环形队列的核心和关键。这个操作一次只能在其中一个core上完成(假设CPU1上成功执行了CAS操作)。而CPU2跳转到第①步从头开始执行。等CPU2执行完毕第二步时,结果如下图所示
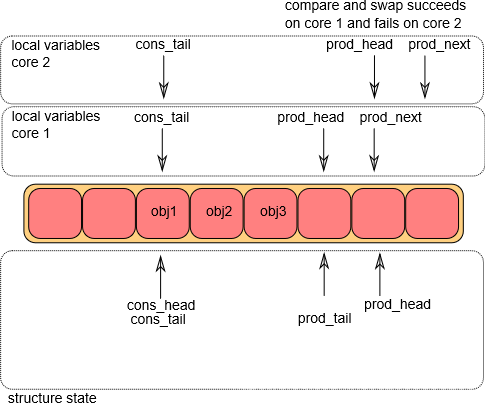
-
入队操作第③步
CPU2上CAS执行成功,CPU1和CPU2开始进行真正的入队操作,分别将对象添加到队列中。
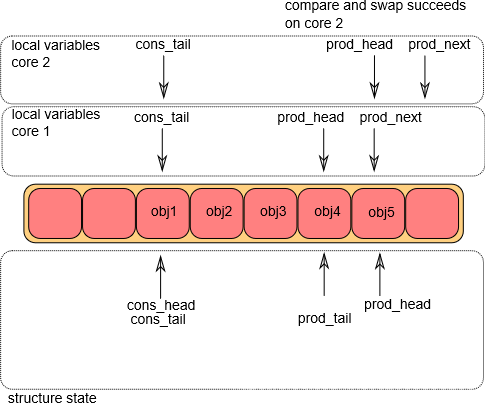
- 入队操作第④步
两个CPU同时更新prod_head指针,如果g_prod_tail == l_prod_head, 则更新g_prod_tail指针。从上图中我们可以看出,这个操作最初只能在CPU1上执行成功。结果如下:

CPU1将g_prod_tail指针进行了更新,此时CPU2上已经满足了g_prod_tail == l_prod_head。
-
入队操作第⑤步
CPU执行第④步操作,操作成功后,入队操作便执行完毕。

DPDK中的源码实现如下:
static inline int __attribute__((always_inline))
__rte_ring_mp_do_enqueue(struct rte_ring *r, void * const *obj_table,unsigned n, enum rte_ring_queue_behavior behavior)
{uint32_t prod_head, prod_next;uint32_t cons_tail, free_entries;const unsigned max = n;int success;unsigned i, rep = 0;uint32_t mask = r->prod.mask;int ret;/* move prod.head atomically */do {/* Reset n to the initial burst count */n = max;prod_head = r->prod.head;cons_tail = r->cons.tail;/* The subtraction is done between two unsigned 32bits value* (the result is always modulo 32 bits even if we have* prod_head > cons_tail). So 'free_entries' is always between 0* and size(ring)-1. */free_entries = (mask + cons_tail - prod_head);/* check that we have enough room in ring */if (unlikely(n > free_entries)) {if (behavior == RTE_RING_QUEUE_FIXED) {__RING_STAT_ADD(r, enq_fail, n);return -ENOBUFS;}else {/* No free entry available */if (unlikely(free_entries == 0)) {__RING_STAT_ADD(r, enq_fail, n);return 0;}n = free_entries;}}prod_next = prod_head + n;/** rte_atomic32_cmpset(volatile uint32_t *dst, uint32_t exp, uint32_t src)** if(dst==exp) dst=src;* else * return false;*/success = rte_atomic32_cmpset(&r->prod.head, prod_head,prod_next);/*此操作应该会从内存中读取值,并将不同核的修改写回到内存中*/} while (unlikely(success == 0));/*如果失败,更新相关指针重新操作*//* write entries in ring */ENQUEUE_PTRS();rte_smp_wmb();/*写内存屏障*//* if we exceed the watermark */if (unlikely(((mask + 1) - free_entries + n) > r->prod.watermark)) {ret = (behavior == RTE_RING_QUEUE_FIXED) ? -EDQUOT :(int)(n | RTE_RING_QUOT_EXCEED);__RING_STAT_ADD(r, enq_quota, n);}else {ret = (behavior == RTE_RING_QUEUE_FIXED) ? 0 : n;__RING_STAT_ADD(r, enq_success, n);}/** If there are other enqueues in progress that preceded us,* we need to wait for them to complete*/while (unlikely(r->prod.tail != prod_head)) {rte_pause();/* Set RTE_RING_PAUSE_REP_COUNT to avoid spin too long waiting* for other thread finish. It gives pre-empted thread a chance* to proceed and finish with ring dequeue operation. */if (RTE_RING_PAUSE_REP_COUNT &&++rep == RTE_RING_PAUSE_REP_COUNT) {rep = 0;sched_yield();}}r->prod.tail = prod_next;return ret;
}小故事不讲了,怕尺度太大,文章被禁呀!!!敬请原谅。
3.2 多消费者–出队
多消费者出队官方文档并没有说明,我也不再描述,直接附上源码供大家学习。
static inline int __attribute__((always_inline))
__rte_ring_mc_do_dequeue(struct rte_ring *r, void **obj_table,unsigned n, enum rte_ring_queue_behavior behavior)
{uint32_t cons_head, prod_tail;uint32_t cons_next, entries;const unsigned max = n;int success;unsigned i, rep = 0;uint32_t mask = r->prod.mask;/* move cons.head atomically */do {/* Restore n as it may change every loop */n = max;cons_head = r->cons.head;prod_tail = r->prod.tail;/* The subtraction is done between two unsigned 32bits value* (the result is always modulo 32 bits even if we have* cons_head > prod_tail). So 'entries' is always between 0* and size(ring)-1. */entries = (prod_tail - cons_head);/* Set the actual entries for dequeue */if (n > entries) {if (behavior == RTE_RING_QUEUE_FIXED) {__RING_STAT_ADD(r, deq_fail, n);return -ENOENT;}else {if (unlikely(entries == 0)){__RING_STAT_ADD(r, deq_fail, n);return 0;}n = entries;}}cons_next = cons_head + n;success = rte_atomic32_cmpset(&r->cons.head, cons_head,cons_next);} while (unlikely(success == 0));/* copy in table */DEQUEUE_PTRS();rte_smp_rmb();/** If there are other dequeues in progress that preceded us,* we need to wait for them to complete*/while (unlikely(r->cons.tail != cons_head)) {rte_pause();/* Set RTE_RING_PAUSE_REP_COUNT to avoid spin too long waiting* for other thread finish. It gives pre-empted thread a chance* to proceed and finish with ring dequeue operation. */if (RTE_RING_PAUSE_REP_COUNT &&++rep == RTE_RING_PAUSE_REP_COUNT) {rep = 0;sched_yield();}}__RING_STAT_ADD(r, deq_success, n);r->cons.tail = cons_next;return behavior == RTE_RING_QUEUE_FIXED ? 0 : n;
}参考文献:
Programmer’s Guid
这篇关于DPDK 无锁环形队列(Ring)详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






