本文主要是介绍MapReduce之多输入,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
MapReduce之多输入
- 一、需求说明
- 二、测试数据
- 三、编程思路
- 四、实现步骤
- 五、打包上传到集群中运行
一、需求说明
- 说明:多输入指的是数据源有多种格式的数据,比如在一个目录下有文本类型的和SequenceFile二进制格式的。 针对这种场景,需要使用MapReduce来分析数据。
- 要求:改写wordcount程序的输入数据源,实现单词统计。
二、测试数据
- 序列化文件:下载地址
- 文本文件可以使用之前的wordcount案例所使用的测试数据
三、编程思路
- 思路:
1、有多少种数据格式,就需要编写与之对应的mapper即可
2、需要使用MultipleInputs类来实现
四、实现步骤
-
在Idea或eclipse中创建maven项目
-
在pom.xml中添加hadoop依赖
<dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>2.7.3</version> </dependency> <dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>2.7.3</version> </dependency> <dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-common</artifactId><version>2.7.3</version> </dependency> <dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-core</artifactId><version>2.7.3</version> </dependency> -
添加log4j.properties文件在资源目录下即resources,文件内容如下:
### 配置根 ### log4j.rootLogger = debug,console,fileAppender ## 配置输出到控制台 ### log4j.appender.console = org.apache.log4j.ConsoleAppender log4j.appender.console.Target = System.out log4j.appender.console.layout = org.apache.log4j.PatternLayout log4j.appender.console.layout.ConversionPattern = %d{ABSOLUTE} %5p %c:%L - %m%n ### 配置输出到文件 ### log4j.appender.fileAppender = org.apache.log4j.FileAppender log4j.appender.fileAppender.File = logs/logs.log log4j.appender.fileAppender.Append = false log4j.appender.fileAppender.Threshold = DEBUG,INFO,WARN,ERROR log4j.appender.fileAppender.layout = org.apache.log4j.PatternLayout log4j.appender.fileAppender.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n -
编写文本类型的mapper即TextInputMapper
import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class TextInputMapper extends Mapper<LongWritable, Text,Text, IntWritable> {@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {String data = value.toString();//分词:I love GuizhouString[] words = data.split(" ");for (String word: words) {context.write(new Text(word),new IntWritable(1));}} } -
编写SequenceFile二进制格式类型的mapper,即SequenceFileInputMapper
import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class SequenceFileInputMapper extends Mapper<IntWritable, Text,Text,IntWritable> {protected void map(IntWritable key, Text value, Context context) throws IOException, InterruptedException {//数据格式:100 One, two, buckle my shoeString data = value.toString();String[] words = data.split(",");for (int i = 0; i < words.length; ++i) {if (i < 2){context.write(new Text(words[i]),new IntWritable(1));}else{String[] subWords = words[i].split(" ");for (int j = 0; j < subWords.length; j++) {context.write(new Text(subWords[j]),new IntWritable(1));}}}} } -
编写reducer类
import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class WordCountReducer extends Reducer<Text, IntWritable,Text,IntWritable> {protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {int sum = 0;for (IntWritable v : values) {sum += v.get();}context.write(key,new IntWritable(sum));} } -
编写Driver类
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.MultipleInputs; import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.util.Random;public class WordCountJob {public static void main(String[] args) throws Exception {Configuration configuration = new Configuration();Job job = Job.getInstance(configuration);job.setJarByClass(WordCountJob.class);//多输入设置MultipleInputs.addInputPath(job,new Path("F:\\NIIT\\hadoopOnWindow\\input\\data\\txt"), TextInputFormat.class, TextInputMapper.class);MultipleInputs.addInputPath(job,new Path("F:\\NIIT\\hadoopOnWindow\\input\\data\\seq"), SequenceFileInputFormat.class, SequenceFileInputMapper.class);/指定reducejob.setReducerClass(WordCountReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);//设置输出FileOutputFormat.setOutputPath(job,new Path(getOutputDir()));boolean result = job.waitForCompletion(true);if (result)System.out.println("运行成功");elseSystem.out.println("运行失败");}//用于产生随机输出目录public static String getOutputDir(){String prefix = "F:\\NIIT\\hadoopOnWindow\\output\\";long time = System.currentTimeMillis();int random = new Random().nextInt(1000);return prefix + "result_" + time + "_" + random;} } -
本地运行代码,测试下结果正确与否
五、打包上传到集群中运行
-
上传emp.csv到hdfs中的datas目录下
-
本地运行测试结果正确后,需要对Driver类输入输出部分代码进行修改,具体修改如下:
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1])); -
将程序打成jar包,需要在pom.xml中配置打包插件
<build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId> maven-assembly-plugin </artifactId><configuration><!-- 使用Maven预配置的描述符--><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><!-- 绑定到package生命周期 --><phase>package</phase><goals><!-- 只运行一次 --><goal>single</goal></goals></execution></executions></plugin></plugins></build>按照如下图所示进行操作
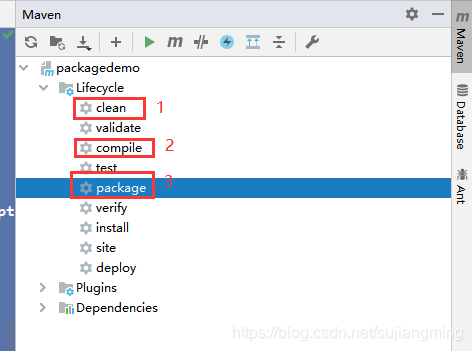
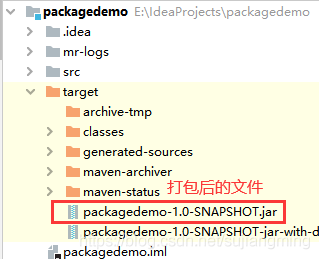
-
提交集群运行,执行如下命令:
hadoop jar packagedemo-1.0-SNAPSHOT.jar com.niit.mr.EmpJob /datas/emp.csv /output/emp/至此,所有的步骤已经完成,大家可以试试,祝大家好运~~~~
这篇关于MapReduce之多输入的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!