本文主要是介绍ESM蛋白质语言模型系列,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
模型总览
-
第一篇《Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences 》ESM-1b
-
第二篇《MSA Transformer》在ESM-1b的基础上作出改进,将模型的输入从单一蛋白质序列改为MSA矩阵,并在Transformer中加入行、列两种轴向注意力机制,对位点分别计算第个序列和第个对齐位置的影响,充分利用二维输入的优势。
-
第三篇《Language models enable zero-shot prediction of the effects of mutations on protein function 》中提出了ESM-1v模型,该模型与ESM-1b模型构架相同,只是预训练数据集改为UR90(ESM-1b预训练数据集为UR50)
-
第四篇《Language models of protein sequences at the scale of evolution enable accurate structure prediction》,ESMFold,提出了ESM2,代替MSA部分和Structure Template部分,对Postion Embedding做了修改,可以支持更长的氨基酸序列编码
| 模型名称 | input | 普适性 | 模型 | 论文 |
|---|---|---|---|---|
| ESM-1b | single sequence | family-specific | transformer encoder | Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences |
| ESM-MSA-1b | MSA | few-shot | 加了两个行列注意力机制 | MSA Transformer |
| ESM-1v | single sequence | zero-shot | transformer encoder | Language models enable zero-shot prediction of the effects of mutations on protein function |
| ESM-2 | single sequence | zero-shot | transformer encoder | Language models of protein sequences at the scale of evolution enable accurate structure prediction |
ESM-1B的模型大小如下所示
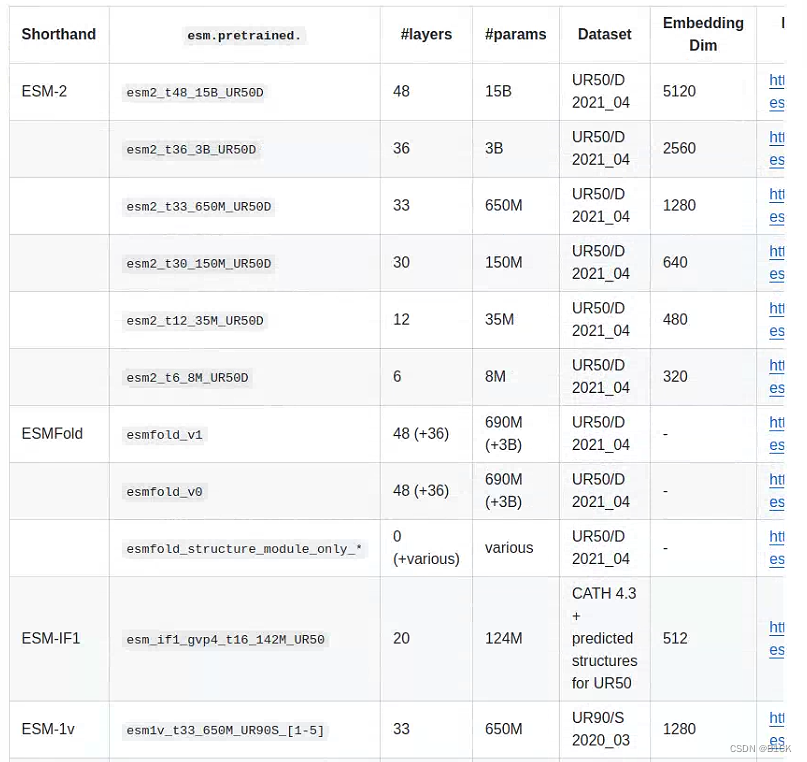
ESM2模型大小如下所示(esm-github截图):
ESM-2 embedding:
Bert输入Embeddings包含三个部分,第一部分为token的embeddings,第二部分为位置编码的embeddings,第三部分为token所属段落编码的embeddings
-
tokenizer(由wordpiece创建)对输入pr序列会头尾添加CLS,EOS特殊字符(论文里写的是BOS、EOS),占两个字符长度 ,batch中长度不够加Padding Token [PAD](CLIP用的是GPT所以用EOS)
-
tokenizer会创建固定大小的词汇表,进行分词,查词汇表将token转化成索引列表
-
加入旋转位置编码
-
分词后送入token embedding层从而将每一个词转换成向量形式
以下是bert 词嵌入的过程:
tokenizer首先检查整个单词是否在词汇表中。如果没有,则尝试将单词分解为词汇表中包含的尽可能大的子单词,最后将单词分解为单个字符。注意,由于这个原因,我们总是可以将一个单词表示为至少是它的单个字符的集合
self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=0),相同位置输出相同
将这3个ID序列输入到BERT中就会按照BERT模型的定义依次将各种ID转换为对应的embedding:
Token Embeddings, (1, n, 768) ,词的向量表示
Segment Embeddings, (1, n, 768),辅助BERT区别句子对中的两个句子的向量表示,EMS2将蛋白质视为几个句子?
Position Embeddings ,(1, n, 768) ,让BERT学习到输入的顺序属性
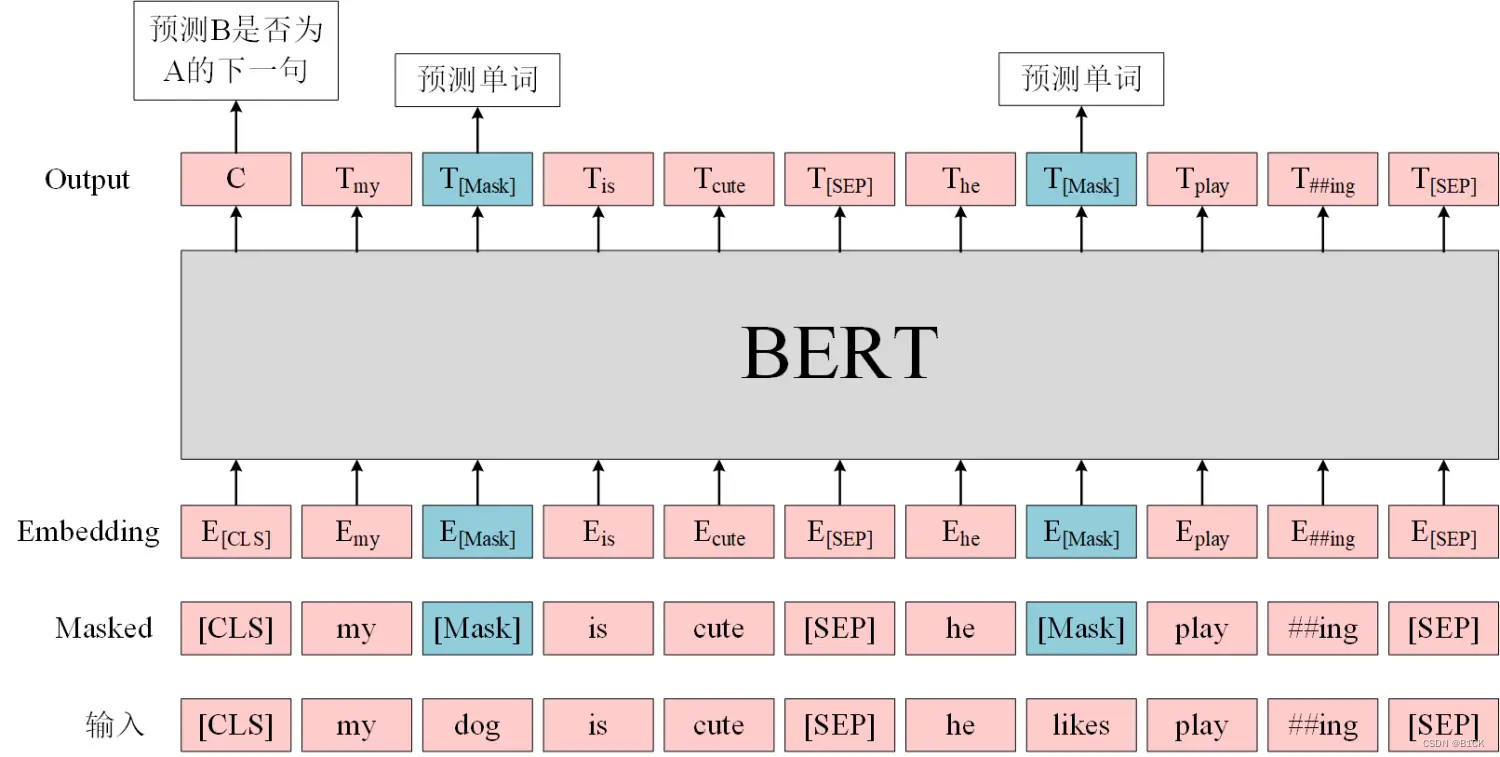
bert应用于下游任务:

ESM-2 output:
最开始是CLS,最后是EOS
这篇关于ESM蛋白质语言模型系列的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




