本文主要是介绍【机器学习算法】集成学习-2 三个臭皮匠顶一个诸葛亮,弱学习器的机器学习元算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
机器学习元算法
机器学习元算法概述
抽样技术
袋装法原理:
bagging
随机森林
提升法(boosting)
Boosting原理
GBDT提升法
Xgboost
这是一个机器算法的试验:
我的主页:晴天qt01的博客_CSDN博客-数据分析师领域博主
目前进度:第四部分【机器学习算法】
我们发现即使是弱分类器组合的模型,即使是组合投票的结果模型,居然可以胜过我们多个强学习器的融合学习。
机器学习元算法
机器学习元算法概述
只用一个算法,通过抽样的计算在训练数据做sample采样,采用同一个算法,做一些抽样,然后投票预测
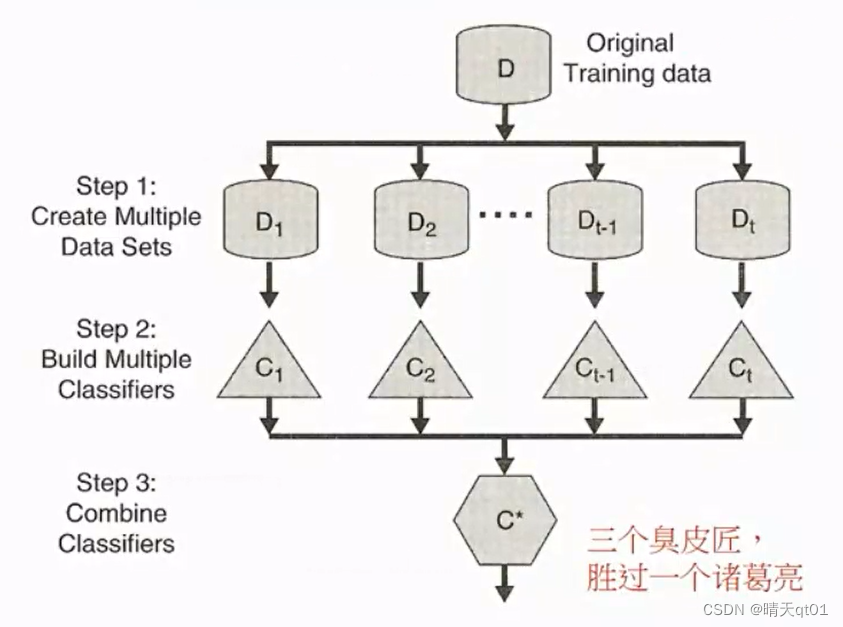
架构如上,有一笔训练数据,我们将原始的训练数据,通过抽样的方式,变为不同的数据集。
每个数据集用机器学习的算法建立某种模型,比如决策树,建立t个决策树,然后我们将t个决策树,进行一个投票,得到一个模型。
其中的每一个分类器,都是弱分类器,都是原始数据的一部分。我们发现即使是我们这种弱分类器组合的模型,即使是组合投票的结果模型,居然可以胜过我们多个强学习器的融合学习。
这就应了我们中国的谚语:“3个臭皮匠顶一个诸葛亮”
这句话其实是对的。这是机器学习算法的架构。将多个弱的学习器,集合起来成为一个强的学习器
根据学习器的不同,可以分为bagging和boosting两大类
Bagging的个体学习器不存在依赖关系(学习器与学习器之间),可以同时对样本随机采样进行生成个体学习器(做并行)。
Boosting的个体学习器之间存在强的依赖关系(上一个学习器的结果会影响下一个学习器),在基于前面模型的训练结果(误差)生成新的模型,所以必须串行串行行化生成(一个接一个生成)
Bagging的方法对样本随机取样产生多个独立模型,然后平均所有模型的预测值,意在减少方差(Variance)产生稳定的模型。
Boosting是拟合前一个模型的误差,减少在前一个模型的误差,意在减少误差。准群。
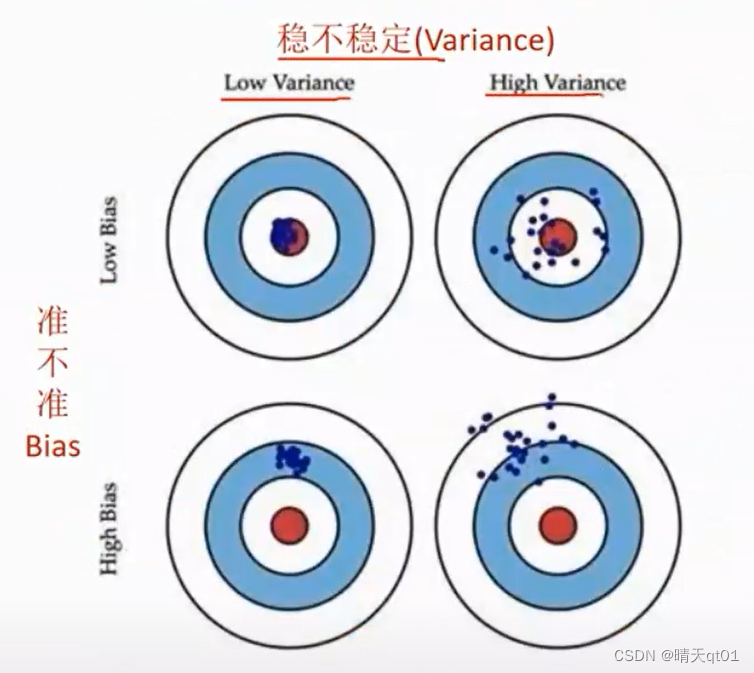
二者的区别就是如上图,高稳定(低方差)说明预测结果集中,低误差说明准确率好。
二者各有好处,比赛都喜欢用boosting,赌一把,准就冠军。如果很稳定就没有冠军的希望。不代表boosting很好,因为企业其实希望要稳定,Bagging
抽样技术
训练数据上的抽样技术
假设训练数据集有1000笔,每次也抽1000笔数据,方法一般有两种
Bagging和boosting
这这两个就是在训练数集是动手脚
输入字段上的抽样计算
我每次输入字段都不是用同一笔字段,有些字段有用,有些字段没有用。不同输入字段也会产生不同的输入模型,产生出的多个模型比如随机森林。
随机森林是既在输入字段动手脚,也在训练字段动手脚bagging)
袋装法(BAgging)
袋装法原理:
bagging
其实它的原理非常复杂,我们用一个简单的案例来说明
案例:
这是我们一个原始得到训练数据集。

它只有一个输入字段,一个输出字段。
1代表一类,-1代表另一类,
假如我给你这样的训练数据,让你建立一层的二元树,也就是只能用一个字段,把它分两枝。这是一层的二元树。那么我们这个决策树要在哪切割呢,得到最高的分类准确率。
我们会选择0.3和0.4之间切割,或者0.7和0.8之间分割
第一种就是,小于0.3预测为1,大于0.4预测为-1
这个节点准确率是百分之70,
这两种至少都会错3笔,无论我们用一层的二元树建立多少层,都会发现它的结果最多到达百分之70
准确率最多是百分之70这是一层的二元树的极限。
那么如果我们用bagging的话,它就会对原始数据进行可取回式的抽样。
那么这时候,它会抽,比如10笔抽10笔。
抽样不只是抽一一次,我们打算抽10次。有些数值会被重复抽到
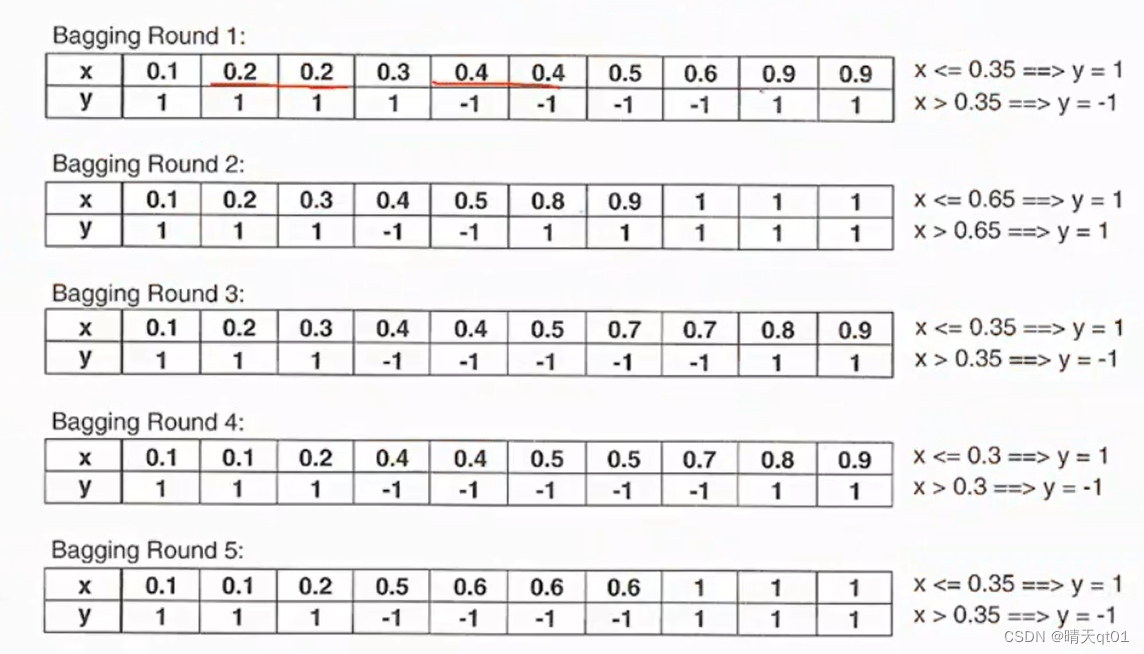
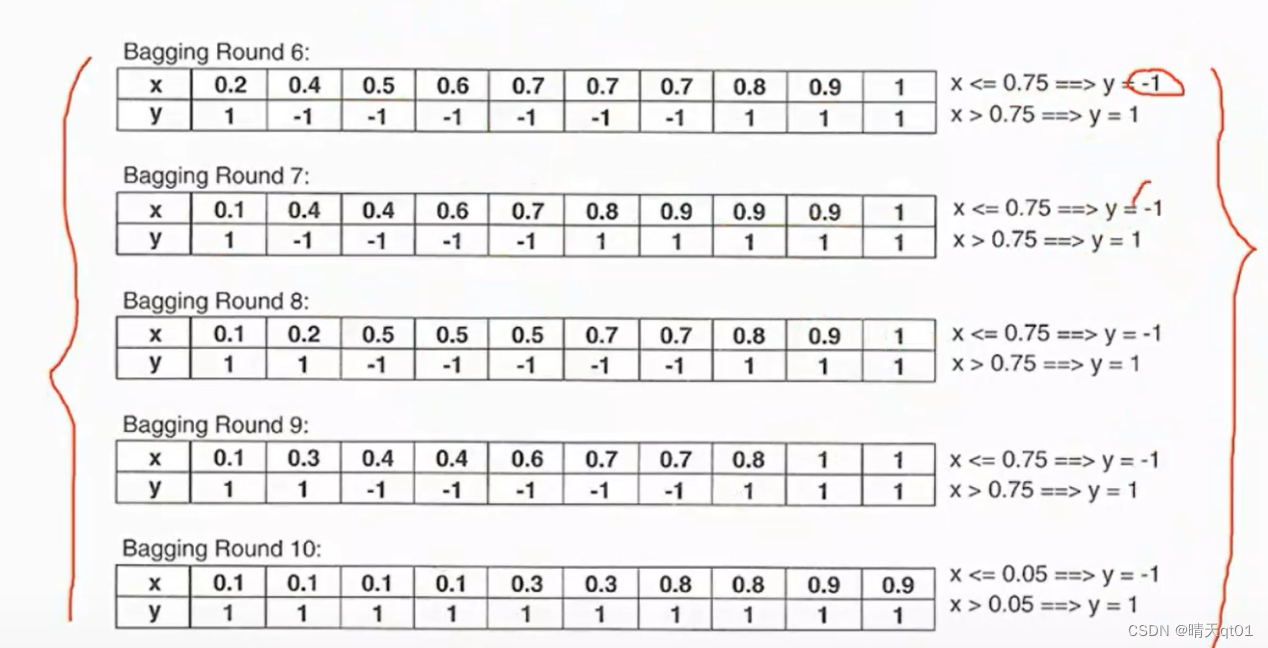
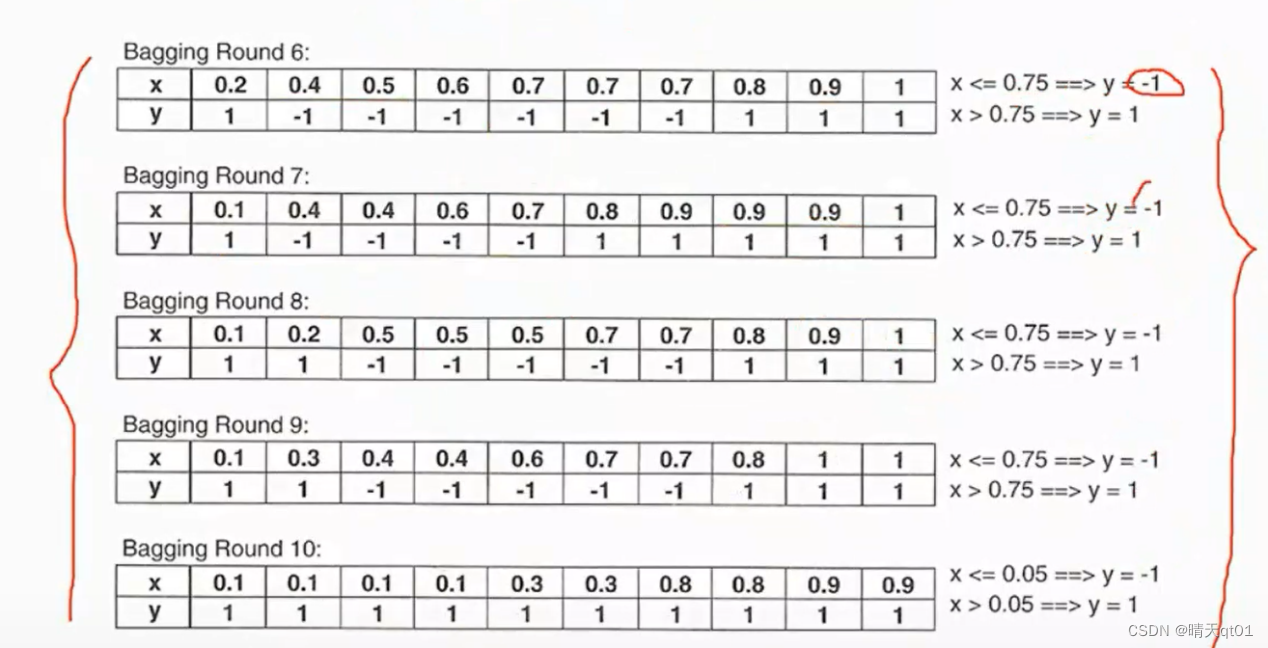
每个随机抽样的结果,只能一层的二元树,应该怎么切割呢,我已经把结果写在图后面了, 第一次我们切割点是0.35,第二次是0.65。。。。
以第一次为例子,它的预测结果是小于0.35都预测为1,大于0.35都预测为-1,我们可以得到他的预测结果
那么现在我们得到了10次抽样结果,每次抽10笔数据的预测结果如下。
我们把这些数据的预测结果,当做我们的训练数据。
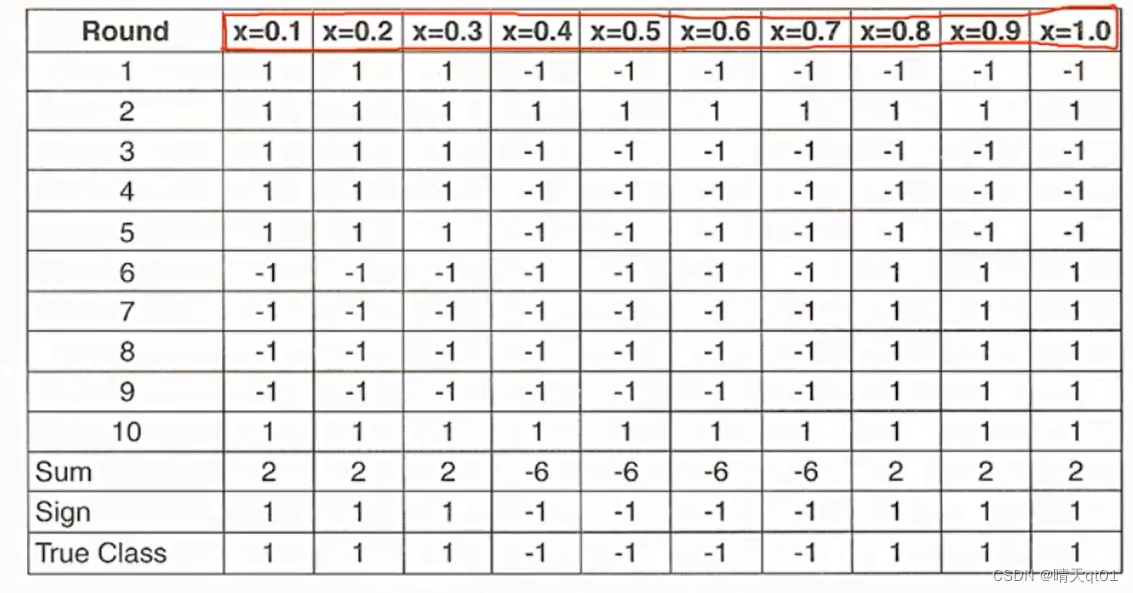
我们采用投票法,当x=0.1的时候,我们把10次预测的结果求和起来,大于0说明预测为1的结果比较多,那么我们就认为它是1,如果小于0说明预测结果为-1的比较多,那么以此类推我们发现,预测结果为111,-1,-1,-1,-1,1,1,1
这时我们回头看目标字段的结果,发现我们用弱学习器得到的结果和目标字段的结果完全一致,准确率达到百分百。
我们用原来的数据,用强分类器,竭尽全力也只能预测正确百分之70.而我们用弱学习器进行投票预测,结果就能达到百分之百,这也说明的机器学习算法的魅力,你会发现它挺神奇的,注意我们也是用一层二元决策树进行建立模型,结果我们却可以突破它的极限能力。因为我们原来这棵树,我们如果想要完全分类正确,我们要如何做,第一刀切割在0.3-0.4之间,第二到0.7-0.8之间再切一刀。
所以如果的二元树我们就得建立2层的二元树。我们只运用一层的二元树,却有两层二元树的效果。所以这个是bagging厉害的地方,
我们有一个假设,每一笔数据被挑中的概率是相同的,也就是每一笔训练数据的权重是相同的,它没有专注在其中一笔数据上。所以他一般都不会出现模型过拟合的情况。以为它都是随机抽样,没有针对性的对一个数据进行记忆处理。
为什么要说明这个情况,以为我们之后boosting会出现这种过拟合的情况,针对某个数据进行特定记忆,提高某些数据的权重,降低误差。
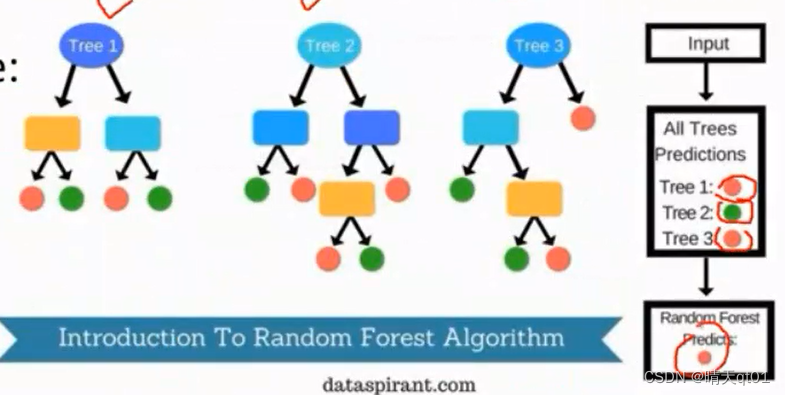
随机森林
我们上面说的是袋装法。
而随机森林是连右边的预测结果都是随机预测的。
随机森林是针对算法上也会做随机(字段选择也是随机),不仅仅是训练数据抽样的随机,所以随机森林是对回归树和分类树的特定处理模型。
一般的袋装法是根据最好的训练数据抽样结果进行字段切割,但是随机森林不是。
这边假设我的候选字段有10个,一般的决策树会用最好的字段进行切割,它会在在k个字段做选择,比如我们人为把k设为3,就会从10个里面挑出3个字段,然后在3个里面挑出最好。
那么我们训练数据和依据字段都是随机的话,那么我的模型就会出现很多种多元的情况。
最后的预测结果同样是在多个弱学习算法的模型进行挑选
Bagging不一定要搭配随机森林,前面训练数据随机挑选出来,后面的算法可以用各自不同的算法,例如挑选的是KNN,神经网络,支持向量机。可以搭配任何的算法。也可以搭配决策树(不过这种情况你要知道你的训练数据是随机的加上不随机的决策树,而随机森林是训练数据也随机,决策字段也随机。可以对比一下二者的结果,可以看看字段随机会不会带来好处。)
所以我们bagging的套件一般后面的算法步骤都是可以选择的,用哪个都可以。像python的套件,它就是数据它帮你随机,算法你自己选。随机森林的套件就是固定的,全随机。
提升法(boosting)
1999年代由schapire提出。然后他和它的搭档yoav Freund改进了这个算法得到Adaboost
在当时 adboost和随机森林,支持向量机是最好的分类器
2001年每个史丹福大学的统计学教授jerome H.Fridman 提出了GBDT(梯度提升决策树,Grading Boosting Decision Tree)的概念,集合弱决策树的分类器,来发展出最优模型是算法
但是阿,由于boosting是通过不断迭代优化的模型,如果数据集非常复杂,那么背后可能需要进行成千上万次的运算,造成计算瓶颈,容易拖慢计算机的计算效率。
面对这个问题,2014年华盛顿大学博士生开发出XG-boosting。
它大幅提升了模型的训练速度与预测的精度
2016年的DMTK的团队他们训练出比较精准,比较轻量级的boost(lightGBM)高效算法。
Boosting原理
Boosting的原理不是很复杂。它是在训练数据动手脚,会动态调整每一笔数据,针对那些难以分类正确的数据,提高他们分类正确的概率。
挑训练数据动态调整每一笔数据被抽样的概率,针对那些难以分类正确的数据,提高它们被抽样的概率。也就是每个数据的被抽中的概率(权重)是不一样
比如我们现在给小学生考试,现在有3个题型,bagging就是每个题型各出1/3来给他考,考完之后,A这个部分大部分都对,B一般,C错了很多。那么我再给他考题的时候,就多出一点C,A少出一点。然后我们发现第二次考题C几乎都对了,B错了一些,A之前做的不错,现在错了几题(说明A之前有些也是恰巧猜对),那么下一次就尽量B和A多一些,C少一些,这样的方法渐渐的ABC就会都对。通过调整权重,把各自都抽出来,并且会调整多次。
如果一笔数据一直被抽错,那么它就会被抽到多笔。那么你把它分类错误的情况就会比较少。(因为它的数据多,比如一半都是这笔数据,为了准确率就一般都会预测它对)
每笔数据的权重刚开始都是给1/N。我们训练分类树,我们发现分类树有一些被分类错误,classified incorrectly,那么我们就会提升这些被分类错误的权重。然后抽样在建立分类器,然后我们看训练结果。这就是提升法的原理。
举例:
这是我们进行的3次10个抽样方案

画蓝色部分,是分类正确的,画红色的是分类错误的。我们发现7和3被分类正确,下次就会少抽样到它,提高4的权重。注意降低权重,不是一定不会被抽到。
第3次一般会把4分对。
案例:
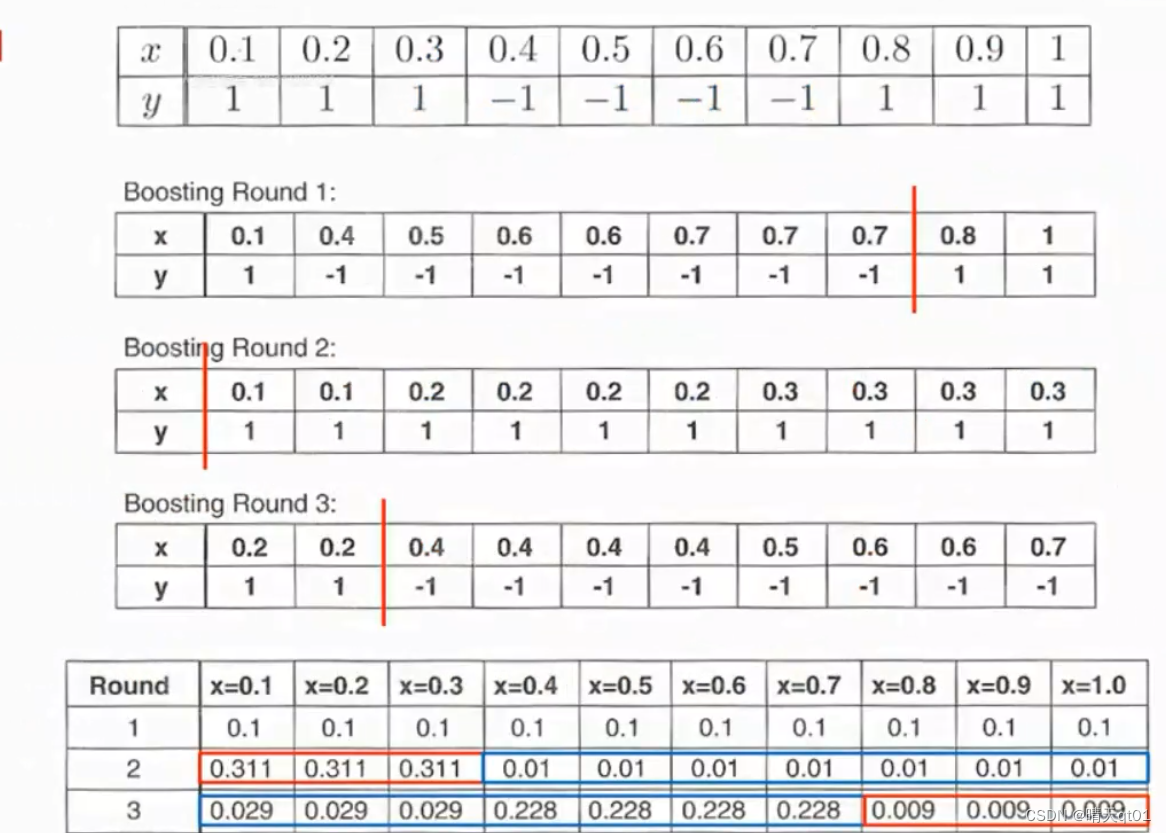
我们这里有一个输入字段,我们直接看最后一个表格,刚开始我们抽样概率都是0.1.第一个分类器我们就会切割在0.7-0.8之间。第一个分类器会分错3个数据(注意这里我们要回头到原始数据中去看错误率),这时我们就会调整每个数据被抽中的概率,因为第一个分类器放在原始数据分错了3类0.1,0.2,0.3,那么我们就提高他们出现的概率,所以第二次训练数据的抽取中,0.1,,02,0.3的概率都提高到0.311。注意这里概率的求和要求是1.
然后我们看第二次抽训练数据的概率。发现要么是0.1要么是0.2要么是0.3,这个时候就随便切嘛都认为是1,在原函数里错误的数值就会是中间4个0.4-0.7
于是我们在增加0.4-0.7它的概率,剩下的都降低权重,下降的概率是有一个公式,没有列出来,也不是很复杂。最后得到第三次抽训练数据的概率。
最后我们分类器会切割在0.2-0.4之间。
你会发现我们分类抽样会和我们的错误率有关,
而且,boosting提升法有一个观念越后面的模型越重要。
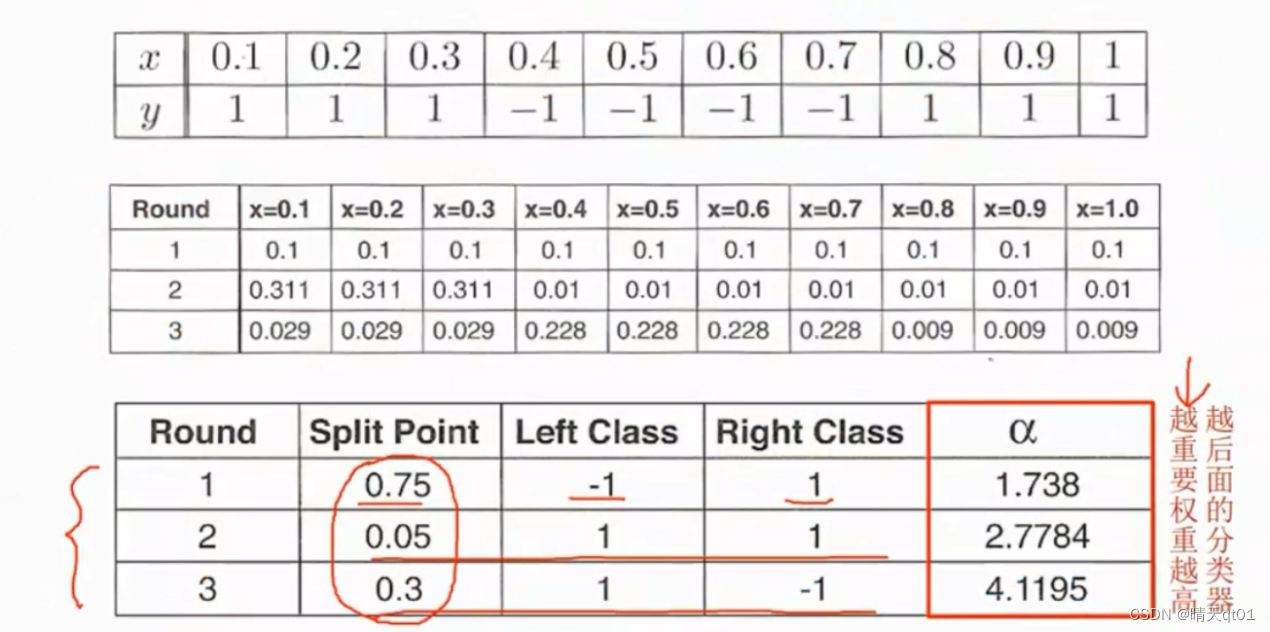
我们会特意给后面的模型更高的权重。Bagging每个权重就是一样的。
然后既然我们现在得到这样的3个模型,我们就可以进行投票求结果
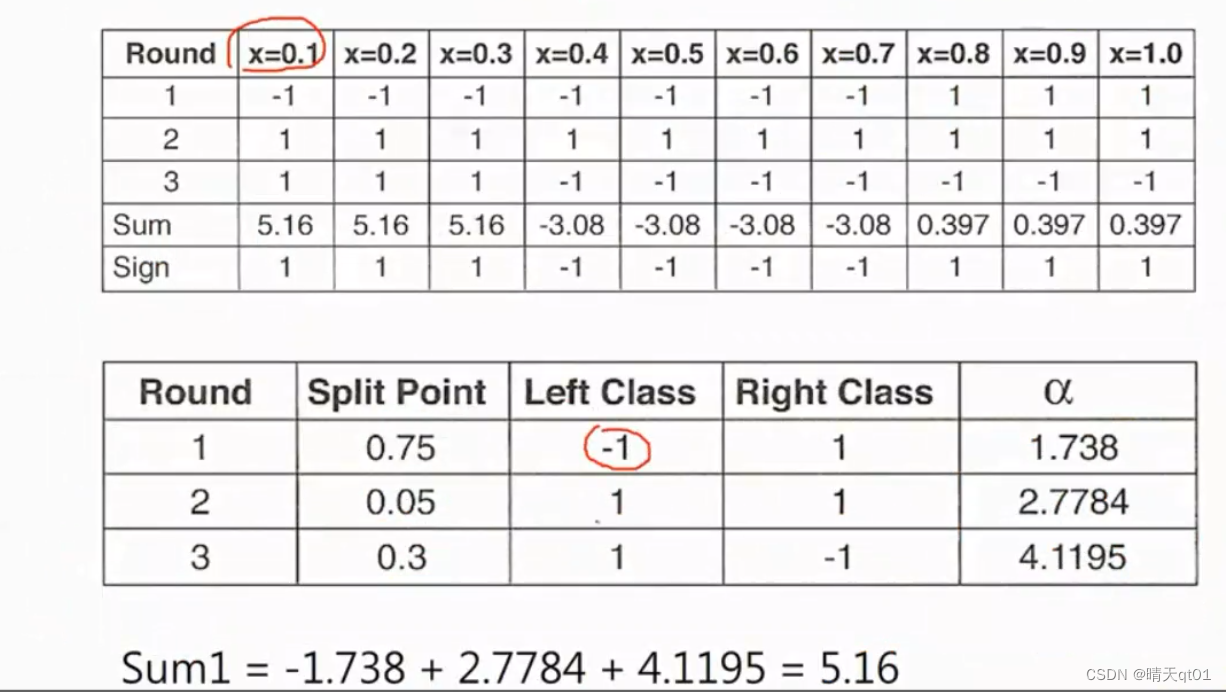
我们把每次的模型数据乘以权重值进行累计求和,最后的结果如果大于0就分类到+1类,小于0就分类到-1类。
最后我们也是可以百分百把数据分类正确。
提升法原理:
如果没有用这个方法,一样的一层的二元分类树顶天了就只能百分之70的分类准确率。
但是如果采用了这个方法,能做到完美的,百分之百分类正确。Boosting会关注之前分类错误的数据,正是因为这样也容易出现过拟合的现象。
这就是boosting的方法。现在它可以利用CPU多线程的技巧,加快计算过程。
原理图解:

第一次建立简单的模型,然后把错误的资料权重加大,上图就可以发现我们有3个加号被分类错误,所以就会加大3个错误的权重,然后下一次又有3个负号分类错误,那么我就会提高这3次错误的误差,然后我们就可以百分百分类正确。
从图我们可以看出来,我们利用了线性的分类器,产生了非线性的分类结果
再举一个图解案例
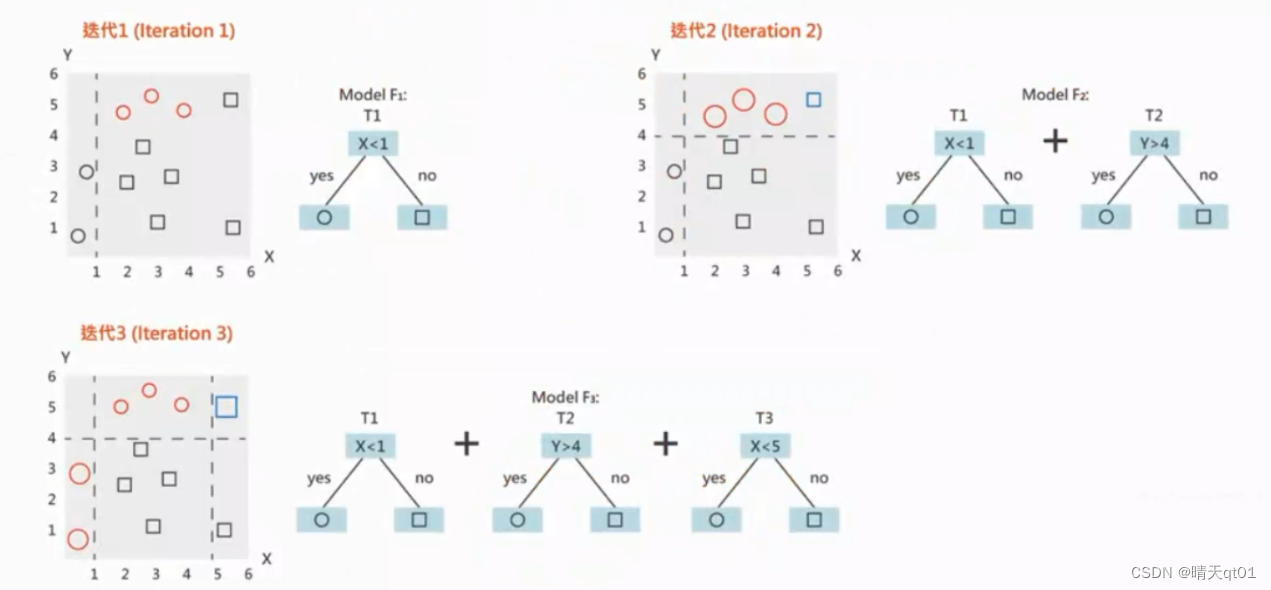
数据有圈也有正方形。在第3次我们就可以得到3个模型来吧这些模型分类正确。
树就是由3棵树的模型进行权重分配。
GBDT提升法
使用训练数据集和样本的真实值,训练一棵树,利用这棵树预测训练集,得到训练集每个样本的预测值,由于预测值和真值存在偏差,使用二者相减就会得到误差值
然后我们在训练第二棵树,这时我们把标准答案真值,改为残差,两棵树训练完成之后就可以再次得到样本的残差。
然后进一步训练第三棵树,以此类推树的总棵数可以人为指定,也可以监控某些指标如验证集上的误差来停止训练
这里我们举一个案例,
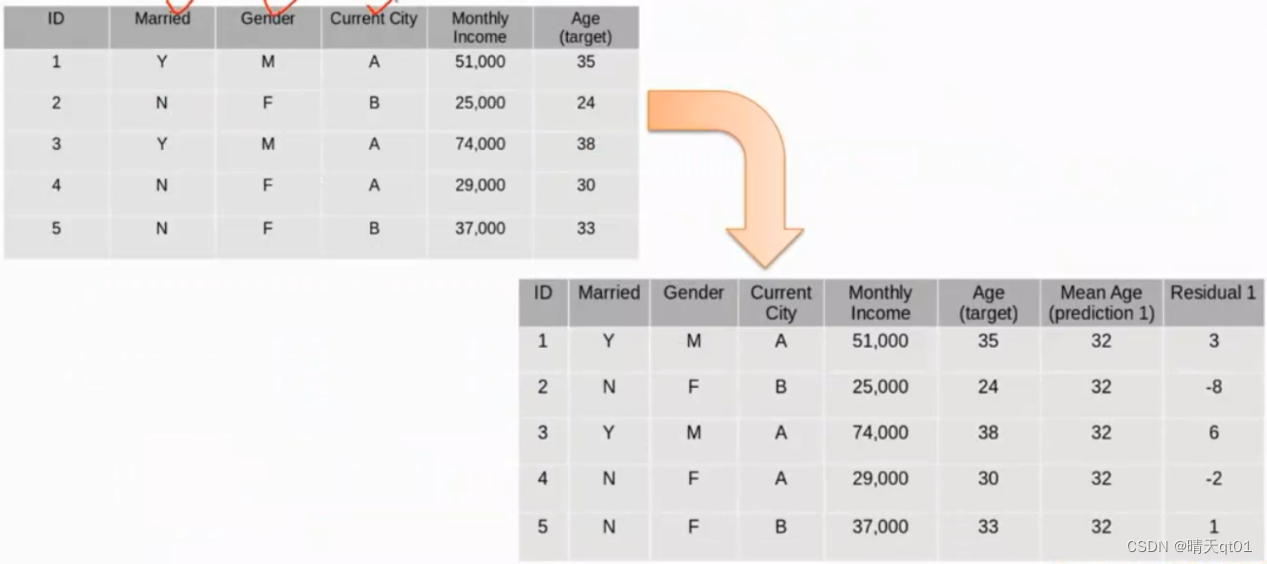
目前我们要预测的是年龄字段,目标字段是4个,字段1是是否结婚,性别,居住城市,收入。
第二个表我们可以发现,残差是图中的真实值减去预测值,因为我们是拿平均年龄为预测字段,所以残差值就是年龄真实值,减去平均值。得到的残差是最后一个字段。
然后我们建立我们的第3个表,也就是建立第3个模型
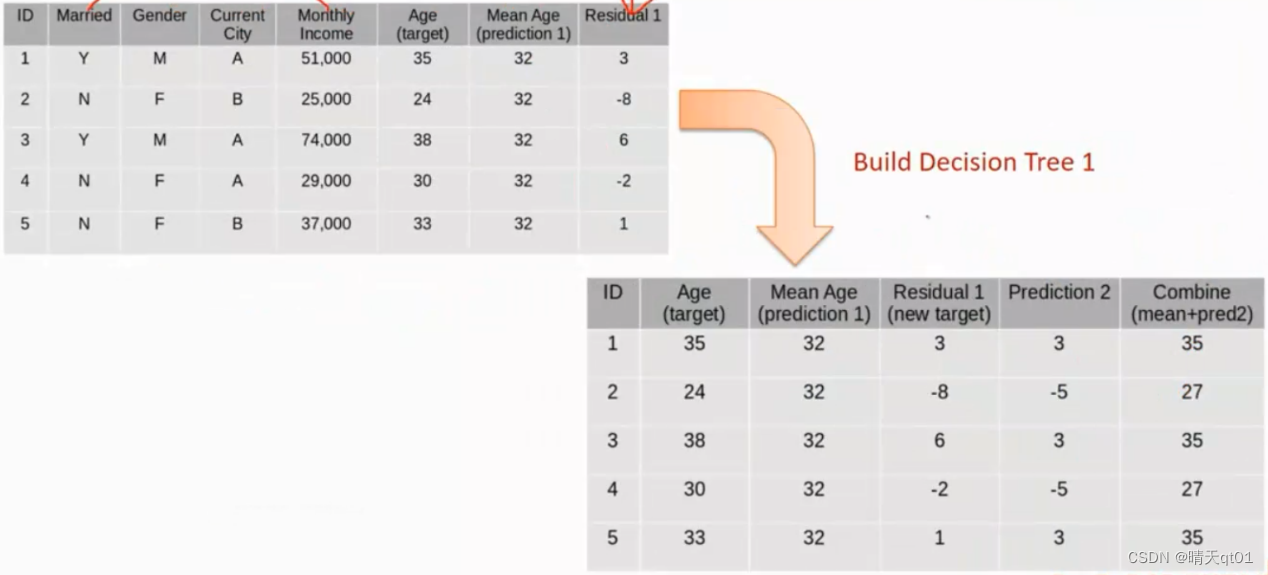
然后我们预测第二个字段,求出第二个字段的残差利用这个残差值作为我们需要的目标字段,其中combine字段代表模型二得到的预测结果。如果我们要结合2个模型的话,就需要用平均年龄加上prediction的残差值
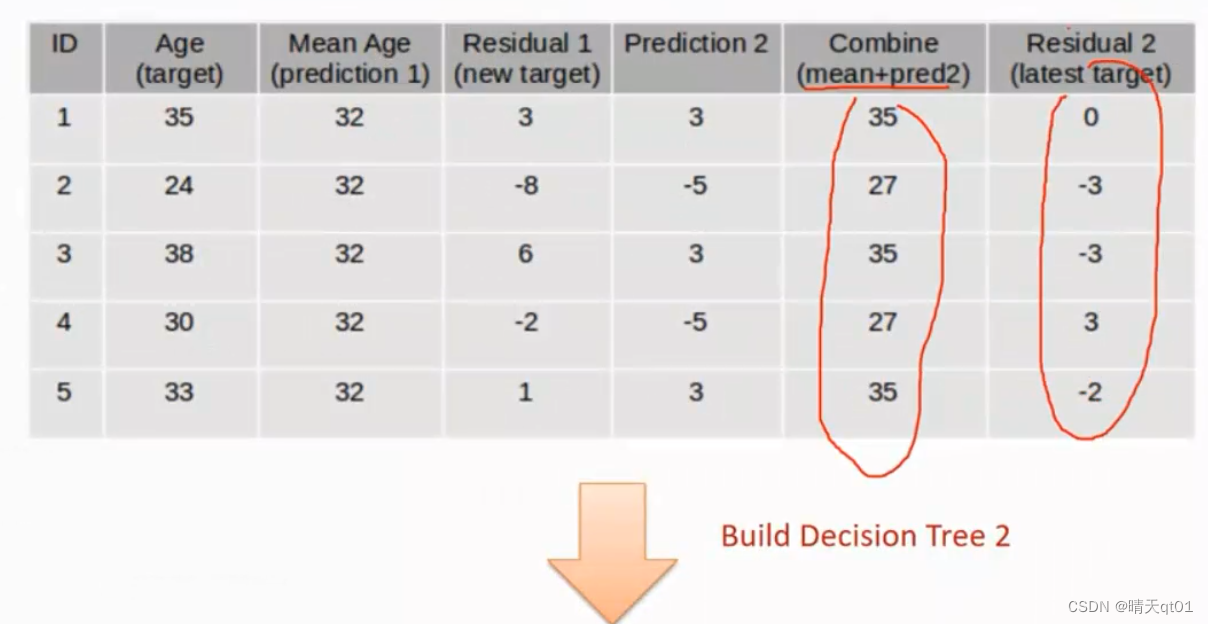
我们此时就得到了两个模型结合的预测结果,,,combine 他的残差值是residual 2(目标字段)
我们就可以再选择下一个模型,不过我们一般不会再选择决策树,而是使用其他模型,我们把残差值作为预测目标,建立下一个模型,
然后把两个模型的值与下一个模型的误差值相加就是我们的预测结果。
Xgboost
Xgboost其实就是在boosting的基础是让其变的更快效率更高。
比较神奇的是,2015年的数据挖掘竞赛中,获胜的29个算法里就有17个使用了XGBoost
在KDDcup2015年的竞赛中排名前十的队伍都使用了XGBoost
它速度快,效果好,功能多,而且它现在也可以在套件中使用,spark上使用,用的人比较多。
这是一个机器算法的试验:
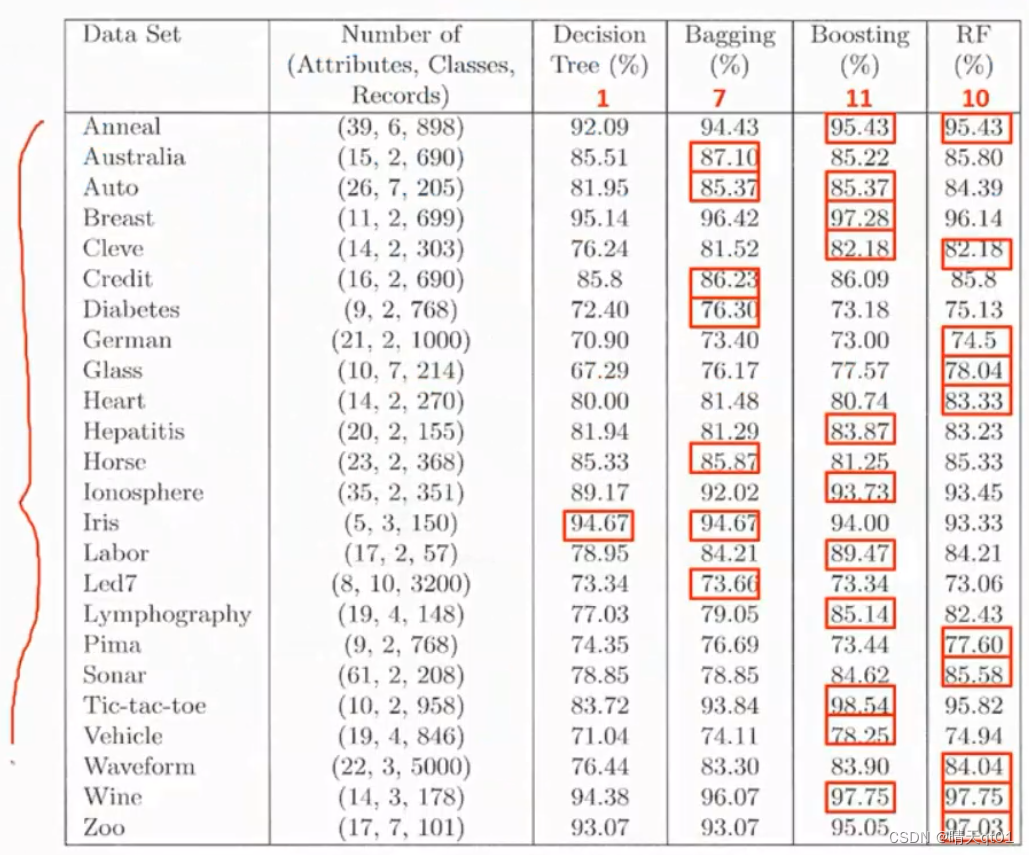
第二列是数据代表如下(39,6,898)代表它有39个字段,6类,898笔数据。如果当初用决策树,准确率92.09,bagging94.43,boosting95.43(决策树的boosting),RF(随机森林)95.43
我们发现单纯只做训练数据随机的bagging效果比做全随机的随机森林,效果要差些。
红色的框代表准确率最高,这样我们统计一下,我们发现决策树只有一次获得冠军,bagging有7次获得冠军,boosting有11次获得冠军,RF有10次获得冠军。
所以随机森林的字段随机其实是有意义的,boosting效果很好。
这个实验里面的正确率是用10则交叉验证的方法建立正确率。我们发现机器学习元算法ensemble要大幅领先原本的决策树。这是集成学习算法的优点。
这篇关于【机器学习算法】集成学习-2 三个臭皮匠顶一个诸葛亮,弱学习器的机器学习元算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






