本文主要是介绍Python有道翻译爬虫,破解反爬虫机制,解决{errorCode:50}错误,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、引言
参考网址:https://tendcode.com/article/youdao-spider/
当前成功时间:2019-6-28
转自个人开源博客:https://my.oschina.net/u/4004713/blog/3067132
本人使用环境:
- Python3.7 (Anaconda)
- IDE:PyCharm
- 系统:mac
二、具体操作
2.1 审查元素
(1)打开有道翻译网址:http://fanyi.youdao.com/ ,右键空白处选择“审查元素/检查”,点击“Network”,选择“XHR”。
在左侧输入要翻译内容,比如说“你好”,网站会自动生成翻译显示在右侧界面,并在XHR中多出一个translate_o文件,点击“翻译”按钮,也会多出一个translate_o文件,不同之处在于Form Data中的action参数,前者为FY_BY_REALTlME,后者是FY_BY_CLICKBUTTION,两种方法皆可,本文以后者为例。
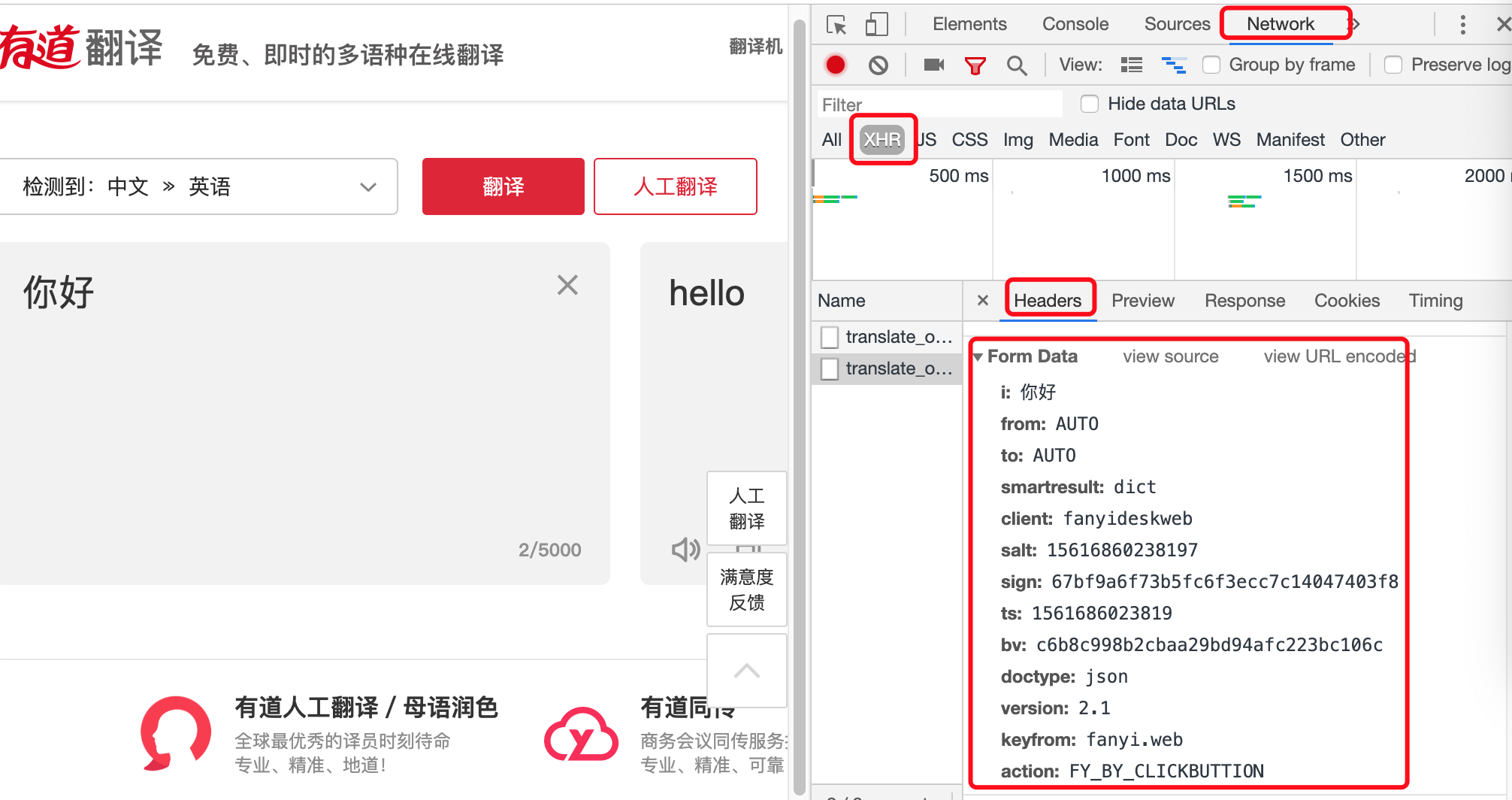
(2)需要记住的内容有:
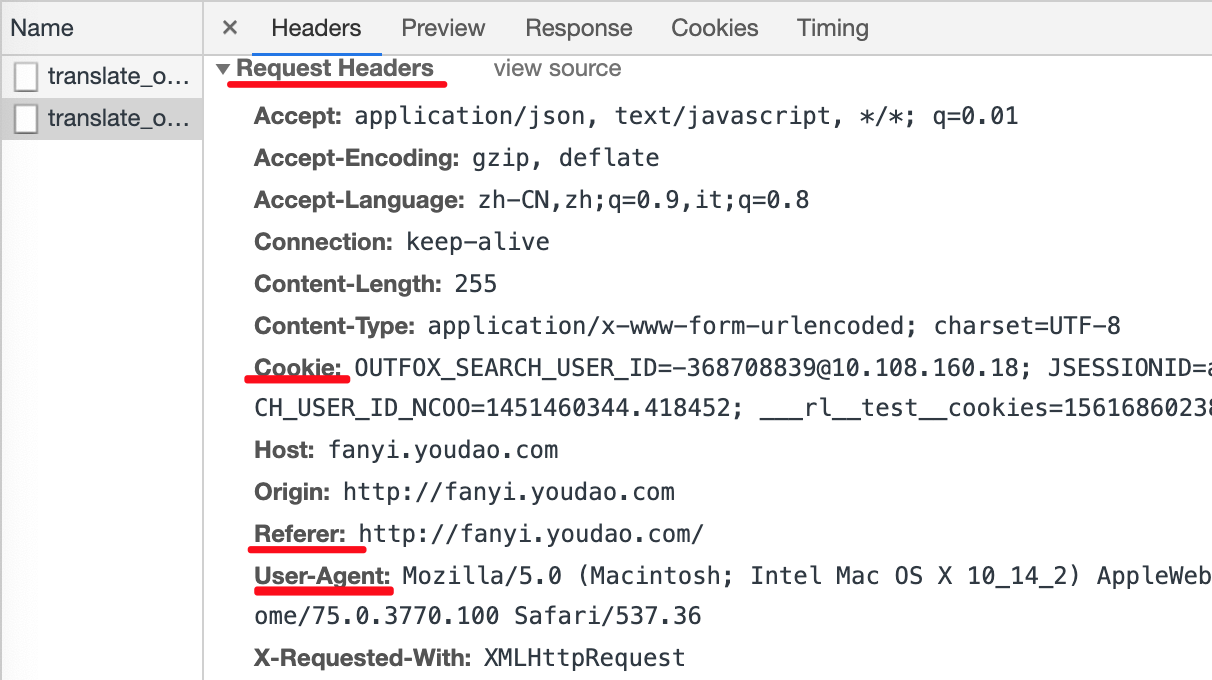
Request Headers(请求头,只需要Cookie,Referer,User-Agent)
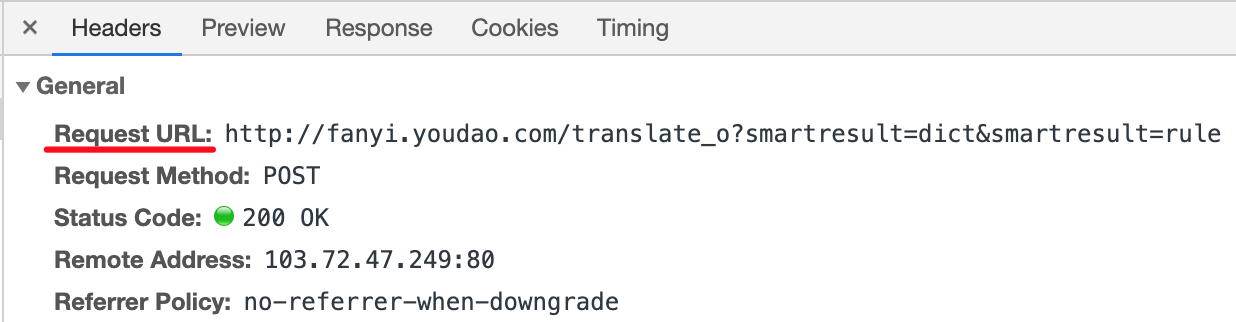
Request URL(请求URL地址)
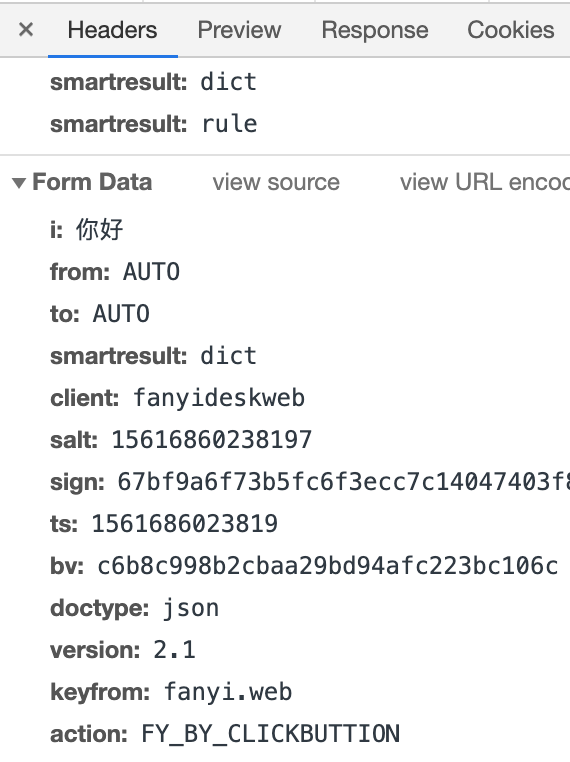
Form Data(发送的数据)
Response(响应内容,可根据其格式取要显示数据)

2.2 破解反爬虫机制
在无爬虫机制的情况下,我们可以简单的使用Form Data中的内容,以及Request Headers请求数据。
Form_Data = {'i': self.msg,'from': 'AUTO','to': 'AUTO','smartresult': 'dict','client': 'fanyideskweb','salt': '15616860238197','sign': '67bf9a6f73b5fc6f3ecc7c14047403f8','ts': '1561686023819','bv': 'c6b8c998b2cbaa29bd94afc223bc106c','doctype': 'json','version': '2.1','keyfrom': 'fanyi.web','action': 'FY_BY_REALTlME'}response = requests.post(self.url, data=Form_Data, headers=headers).texttranslate_results = json.loads(response)
然而,返回结果却是{“errorCode”:50}。从Form Data中分析原因得知,salt,sign,ts三个参数值是动态变化的,每次请求其值都不同,这表明网站对这三个参数作出了加密反爬虫机制,若想取得数据,就必须先破解其加密机制。
观察这几个参数,猜测salt和ts参数与时间戳有关,具体使用了何种加密方式,还要去看网页代码元素。
右键,查看网页源代码,在html中并没有找到对应参数,那么就可能在js文件中,在网页的最后一部分代码,根据js文件的文件名,猜测这几个参数的获取方式可能在"fanyi.min.js"文件中。
打开该js文件,发现这个文件是处理过的 js,直接看是难以看出逻辑的,所以可以把 js 代码放到一些可以重新排版的工具中再查看,如在线“站长工具”,最后可以通过搜索“salt”找到几个参数的生成位置,具体代码片段如下:
define("newweb/common/service", ["./utils", "./md5", "./jquery-1.7"],
function(e, t) {var n = e("./jquery-1.7");e("./utils");e("./md5");var r = function(e) {var t = n.md5(navigator.appVersion),r = "" + (new Date).getTime(),i = r + parseInt(10 * Math.random(), 10);return {ts: r,bv: t,salt: i,sign: n.md5("fanyideskweb" + e + i + "@6f#X3=cCuncYssPsuRUE")}};
从上述参数生成代码中,可知:
(1)网站采用的是md5加密
(2)ts = "" + (new Date).getTime() ,为时间戳
(3)salt = "" + (new Date).getTime() + parseInt(10 * Math.random(), 10)
(4)sign = n.md5("fanyideskweb" + e + i + "@6f#X3=cCuncYssPsuRUE")
其中,e为要翻译内容,i为时间戳,等于ts,其余为固定字符串
明确参数获取方式后,即可编写python代码,破解反爬虫机制。
三、附录代码
import hashlib
import random
import time
import requests
import json"""
向有道翻译发送data,得到翻译结果
"""class Youdao:def __init__(self, msg):self.msg = msgself.url = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'self.D = "@6f#X3=cCuncYssPsuRUE"self.salt = self.get_salt()self.sign = self.get_sign()self.ts = self.get_ts()def get_md(self, value):# md5加密m = hashlib.md5()# m.update(value)m.update(value.encode('utf-8'))return m.hexdigest()def get_salt(self):# 根据当前时间戳获取salt参数s = int(time.time() * 1000) + random.randint(0, 10)return str(s)def get_sign(self):# 使用md5函数和其他参数,得到sign参数s = "fanyideskweb" + self.msg + self.salt + self.Dreturn self.get_md(s)def get_ts(self):# 根据当前时间戳获取ts参数s = int(time.time() * 1000)return str(s)def get_result(self):Form_Data = {'i': self.msg,'from': 'AUTO','to': 'AUTO','smartresult': 'dict','client': 'fanyideskweb','salt': self.salt,'sign': self.sign,'ts': self.ts,'bv': 'c6b8c998b2cbaa29bd94afc223bc106c','doctype': 'json','version': '2.1','keyfrom': 'fanyi.web','action': 'FY_BY_CLICKBUTTION'}headers = {'Cookie': 'OUTFOX_SEARCH_USER_ID=-368708839@10.108.160.18; JSESSIONID=aaaL2DMAbpTgg8Qpc2xUw; OUTFOX_SEARCH_USER_ID_NCOO=1451460344.418452; ___rl__test__cookies=1561684330987','Referer': 'http://fanyi.youdao.com/','User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OSX10_14_2) AppleWebKit/537.36(KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'}response = requests.post(self.url, data=Form_Data, headers=headers).texttranslate_results = json.loads(response)# 找到翻译结果if 'translateResult' in translate_results:translate_results = translate_results['translateResult'][0][0]['tgt']print("翻译的结果是:%s" % translate_results)else:print(translate_results)if __name__ == "__main__":y = Youdao('我成功啦')y.get_result()这篇关于Python有道翻译爬虫,破解反爬虫机制,解决{errorCode:50}错误的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







