本文主要是介绍大数据-玩转数据-双流JOIN,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、双流JOIN
在Flink中, 支持两种方式的流的Join: Window Join和Interval Join
二、Window Join
窗口join会join具有相同的key并且处于同一个窗口中的两个流的元素.
注意:
1.所有的窗口join都是 inner join, 意味着a流中的元素如果在b流中没有对应的, 则a流中这个元素就不会处理(就是忽略掉了)
2.join成功后的元素的会以所在窗口的最大时间作为其时间戳. 例如窗口[5,10), 则元素会以9作为自己的时间戳。
Window join 仍然可分为 滚动窗口、滑动窗口Join、会话窗口Join
滚动窗口Join代码段示例

package com.lyh.flink12;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.JoinFunction;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;/*** @Author lizhenchao@atguigu.cn* @Date 2021/1/24 22:09*/
public class Flink01_Join_Window_Tumbling {public static void main(String[] args) {StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());env.setParallelism(1);SingleOutputStreamOperator<WaterSensor> s1 = env.socketTextStream("hadoop100", 8888) // 在socket终端只输入毫秒级别的时间戳.map(value -> {String[] datas = value.split(",");return new WaterSensor(datas[0], Long.valueOf(datas[1]), Integer.valueOf(datas[2]));}).assignTimestampsAndWatermarks(WatermarkStrategy.<WaterSensor>forMonotonousTimestamps().withTimestampAssigner(new SerializableTimestampAssigner<WaterSensor>() {@Overridepublic long extractTimestamp(WaterSensor element, long recordTimestamp) {return element.getTs() * 1000;}}));SingleOutputStreamOperator<WaterSensor> s2 = env.socketTextStream("hadoop100", 9999) // 在socket终端只输入毫秒级别的时间戳.map(value -> {String[] datas = value.split(",");return new WaterSensor(datas[0], Long.valueOf(datas[1]), Integer.valueOf(datas[2]));}).assignTimestampsAndWatermarks(WatermarkStrategy.<WaterSensor>forMonotonousTimestamps().withTimestampAssigner(new SerializableTimestampAssigner<WaterSensor>() {@Overridepublic long extractTimestamp(WaterSensor element, long recordTimestamp) {return element.getTs() * 1000;}}));s1.join(s2).where(WaterSensor::getId).equalTo(WaterSensor::getId).window(TumblingEventTimeWindows.of(Time.seconds(5))) // 必须使用窗口.apply(new JoinFunction<WaterSensor, WaterSensor, String>() {@Overridepublic String join(WaterSensor first, WaterSensor second) throws Exception {return "first: " + first + ", second: " + second;}}).print();try {env.execute();} catch (Exception e) {e.printStackTrace();}}
}
运行结果:

三、Interval Join
间隔流join(Interval Join), 是指使用一个流的数据按照key去join另外一条流的指定范围的数据.
如下图: 橙色的流去join绿色的流.范围是由橙色流的event-time + lower bound和event-time + upper bound来决定的.
orangeElem.ts + lowerBound <= greenElem.ts <= orangeElem.ts + upperBound
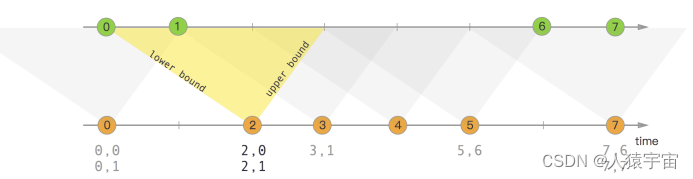
Interval Join只支持event-time
必须是keyBy之后的流才可以interval join
package com.lyh.flink12;
import com.lyh.bean.WaterSensor;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.ProcessJoinFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.table.planner.expressions.In;
import org.apache.flink.util.Collector;
import java.time.Duration;public class Sql_Join_Windows_Interval{public static void main(String[] args) {StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());env.setParallelism(2);SingleOutputStreamOperator<WaterSensor> s1 = env.socketTextStream("hadoop100", 8888).map(value -> {String[] data = value.split(",");return new WaterSensor(data[0],Long.valueOf(data[1]),Integer.valueOf(data[2]));}).assignTimestampsAndWatermarks(WatermarkStrategy.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(2)).withTimestampAssigner(new SerializableTimestampAssigner<WaterSensor>() {@Overridepublic long extractTimestamp(WaterSensor element, long timestamp) {return element.getTs();}}));SingleOutputStreamOperator<WaterSensor> s2 = env.socketTextStream("hadoop100", 9999).map(value -> {String[] data = value.split(",");return new WaterSensor(data[0],Long.valueOf(data[1]),Integer.valueOf(data[2]));}).assignTimestampsAndWatermarks(WatermarkStrategy.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(2)).withTimestampAssigner(new SerializableTimestampAssigner<WaterSensor>() {@Overridepublic long extractTimestamp(WaterSensor element, long timestamp) {return element.getTs();}}));s1.keyBy(WaterSensor::getId).intervalJoin(s2.keyBy(WaterSensor::getId)).between(Time.seconds(-2),Time.seconds(3)).process(new ProcessJoinFunction<WaterSensor, WaterSensor, String>() {@Overridepublic void processElement(WaterSensor left,WaterSensor right,Context ctx,Collector<String> out) throws Exception {out.collect(left + "," + right);}}).print();try{env.execute();} catch (Exception e){e.printStackTrace();}}}
运行结果:

这篇关于大数据-玩转数据-双流JOIN的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





