本文主要是介绍抓取b站视频信息存入excel表格 + 存进mysql (已修改),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、项目简介
1. 抓取搜索b站的视频,抓取标题、链接、播放量、弹幕数以及视频的上传时间,并把他们存放在excel中
2.涉及的类库:time、requests、xlwt、re、lxml
二、代码
# python
# -*- coding:utf-8 -*-
# author:Only time:2019/9/11'''
1.爬取b站 python3视频链接、播放量、以及名称
2.xpath解析
3.存mysql
'''
import xlwt
import re
import time
import requests
from lxml import etreedef save_excel():alllists = get_parse_html()f = xlwt.Workbook(encoding='utf-8')sheet = f.add_sheet('b站爬虫_python教学视频',cell_overwrite_ok=True)alllists.insert(0,("标题","链接","观看次数","弹幕","上传时间"))for row, row_list in enumerate(alllists):for column, column_list in enumerate(row_list):sheet.write(row,column,str(column_list))f.save('b站爬虫_python教学视频'+'.xls')def get_urllist(keyword):urllist = []for page in range(1,3):url = 'https://search.bilibili.com/all?keyword=' + keyword +'&page=' + str(page)urllist.append(url)return urllistdef get_parse_html():header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}alllists = []for url in get_urllist(keyword):response = requests.get(url, headers = header).texthtml = etree.HTML(response)# 标题titles = html.xpath('//div[@class="info"]//a//@title')# 链接links = html.xpath('//li[@class="video-item matrix"]/a/@href')# 观看次数people = html.xpath('//div[@class="tags"]/span[@title="观看"]/text()')peoples = []for i in people:people = i.replace('\n ','')people = i.replace('\n ', '')people = re.split(r'\s+',people) # 正则表达式去空格people = people[1]if people[-1:] == '万':people = float(people[0:-1])*10000else:people = float(people)print(type(people))peoples.append(people)# 弹幕barrage = html.xpath('//div[@class="tags"]/span[@title="弹幕"]/text()')barrages = []for i in barrage:barrage = i.replace('\n ','')barrage = i.replace('\n ', '')barrages.append(barrage)# 上传时间data = html.xpath('//div[@class="tags"]/span[@title="上传时间"]/text()')datas = []for i in data:data = i.replace('\n ', '')data = i.replace('\n ', '')datas.append(data)#print("第"+str(number)+"页抓取成功")# time.sleep(5) # 设置间隔时间为5秒抓取一次alllist = [zonghe for zonghe in zip(titles,links,peoples,barrages,datas)]alllists.extend(alllist)return alllistsif __name__ == "__main__":keyword = "python3" # input("请输入要查找的关键字:")get_urllist(keyword)get_parse_html()save_excel()三、运行结果
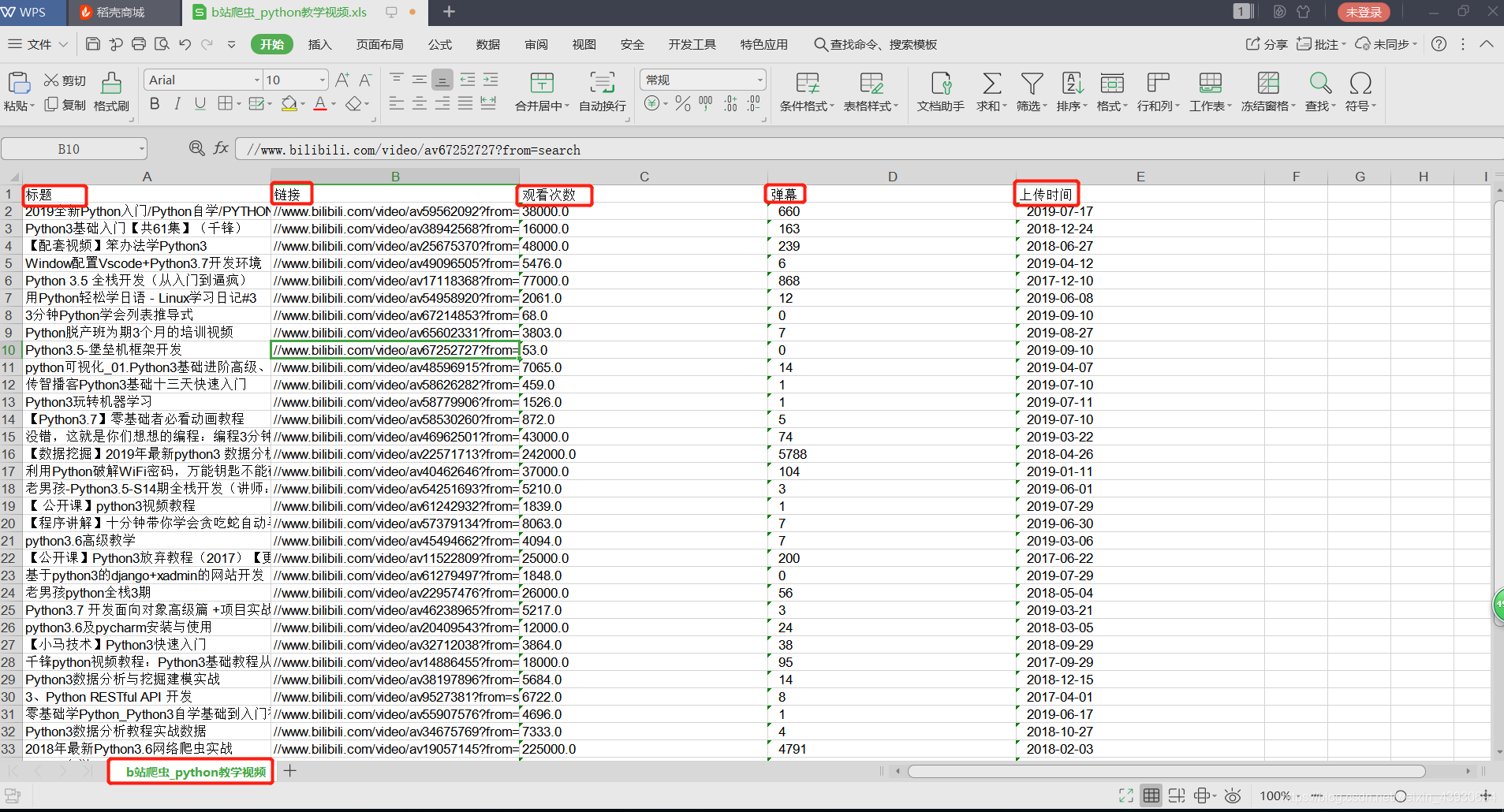
一、项目内容
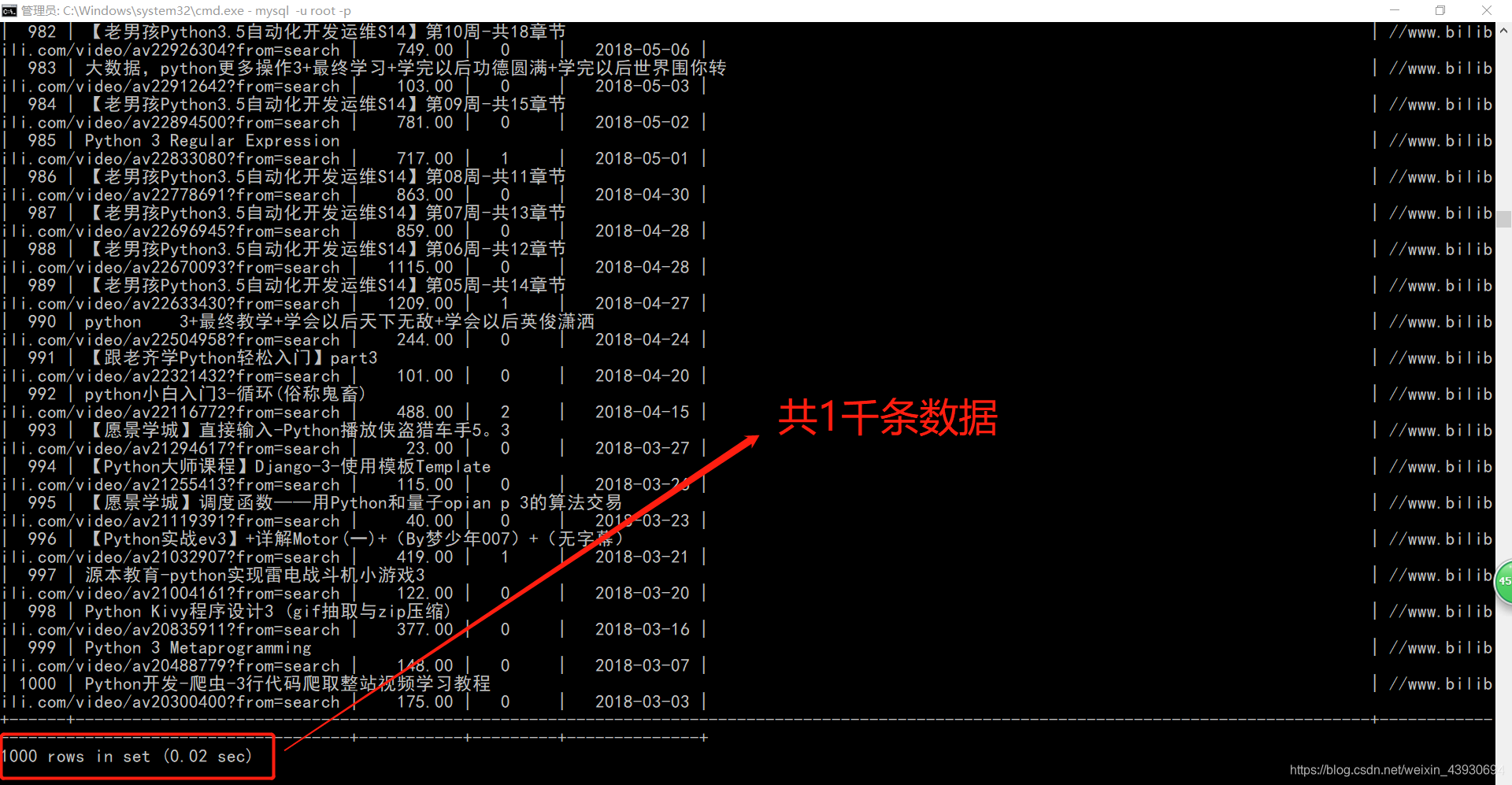
1.抓取b站数据,存入mysql
2.涉及类库:re、lxml、requests、time、pymysql、
3.python3
4. mysql基础笔记
二、代码
# python
# -*- coding:utf-8 -*-
# author:Only time:2019/9/13import pymysql
import requests
import re
import time
from lxml import etree# 获得网址链接
def get_urllist(keyword):urllist = []for page in range(1,51):url = 'https://search.bilibili.com/all?keyword=' + keyword +'&page=' + str(page)urllist.append(url)print(urllist)return urllistdef save_mysql(url_list):# 连接数据库conn = pymysql.connect(host = '127.0.0.1',port = 3306,user = 'root',password = '123qwe',database = 'only',charset = 'utf8')cursor = conn.cursor()sql_1 = 'create table blibli(id int primary key auto_increment not null,title varchar(120) ,link varchar(120) , people float(8,2) , barrage varchar(120) , data varchar(120))'cursor.execute(sql_1)try:# 爬数据header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}for url in url_list:time.sleep(3) # 设置延时 防止ip被封response = requests.get(url, headers=header).texthtml = etree.HTML(response)# 标题titles = html.xpath('//div[@class="info"]//a//@title')# 链接links = html.xpath('//li[@class="video-item matrix"]/a/@href')# 观看次数people = html.xpath('//div[@class="tags"]/span[@title="观看"]/text()')peoples = []for i in people:people = i.replace('\n ', '')people = i.replace('\n ', '')people = re.split(r'\s+', people) # 正则表达式去空格people = people[1]if people[-1:] == '万':people = float(people[0:-1]) * 10000else:people = float(people)peoples.append(people)# 弹幕barrage = html.xpath('//div[@class="tags"]/span[@title="弹幕"]/text()')barrages = []for i in barrage:barrage = i.replace('\n ', '')barrage = i.replace('\n ', '')barrages.append(barrage)# 上传时间data = html.xpath('//div[@class="tags"]/span[@title="上传时间"]/text()')datas = []for i in data:data = i.replace('\n ', '')data = i.replace('\n ', '')datas.append(data)for i in range(len(datas)):print(titles[i])# 执行数据库操作sql_2 = '''insert into blibli(title,link,people,barrage,data) values ("%s","%s","%f","%s","%s")'''cursor.execute(sql_2 % (titles[i],links[i],peoples[i],barrages[i],datas[i]))cursor.fetchall()conn.commit()print("已提交")except Exception as e:conn.rollback()print("数据已回滚")print(e)conn.close()if __name__ == "__main__":keyword = 'python3'url_list = get_urllist(keyword)save_mysql(url_list)
三、代码执行结果展示

这篇关于抓取b站视频信息存入excel表格 + 存进mysql (已修改)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



