本文主要是介绍只要5分钟用数据可视化带你看遍11月份新闻热点事件,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2017年11月份已经离我们而去,在过去的11月份我们也许经历了双十一的剁手,也可能亲眼看见了别人剁手。11月份的北京大兴区发生了”11·18”重大火灾,国内多家幼儿园也多次上了头条,学前教育引起广大重视等等,但是这些事情到底在新闻媒体中出现的频率是有多少呢?11月份又发生了哪些大事呢?且待我用数据告诉你。大数据时代,数据最能体现实际情况,那就开始吧。
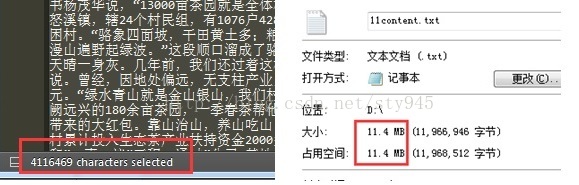
为了给大家提供可靠直观的信息,我决定抓取中国新闻网社会新闻版块(http://www.chinanews.com/society.shtml)11月份的所有新闻数据,之所以选取中国新闻网的数据是因为中国新闻网的新闻质量权威性相对较高。然后我将用数据可视化的图表为大家更加形象的呈现。为了证明我的数据是真实可靠的,下图是我在抓取过程中的一张截图。截止到11月30日中午12点,我总共抓取了约3339条新闻数据,总计大约411万字,在txt文档里大约11M,详细见图2,平均大约每天111多条新闻啊,这个数据量还是可以的,同时也为新闻工作者们心疼3秒钟,要知道这只是中国新闻网的一个社会新闻版块啊,哈哈哈......
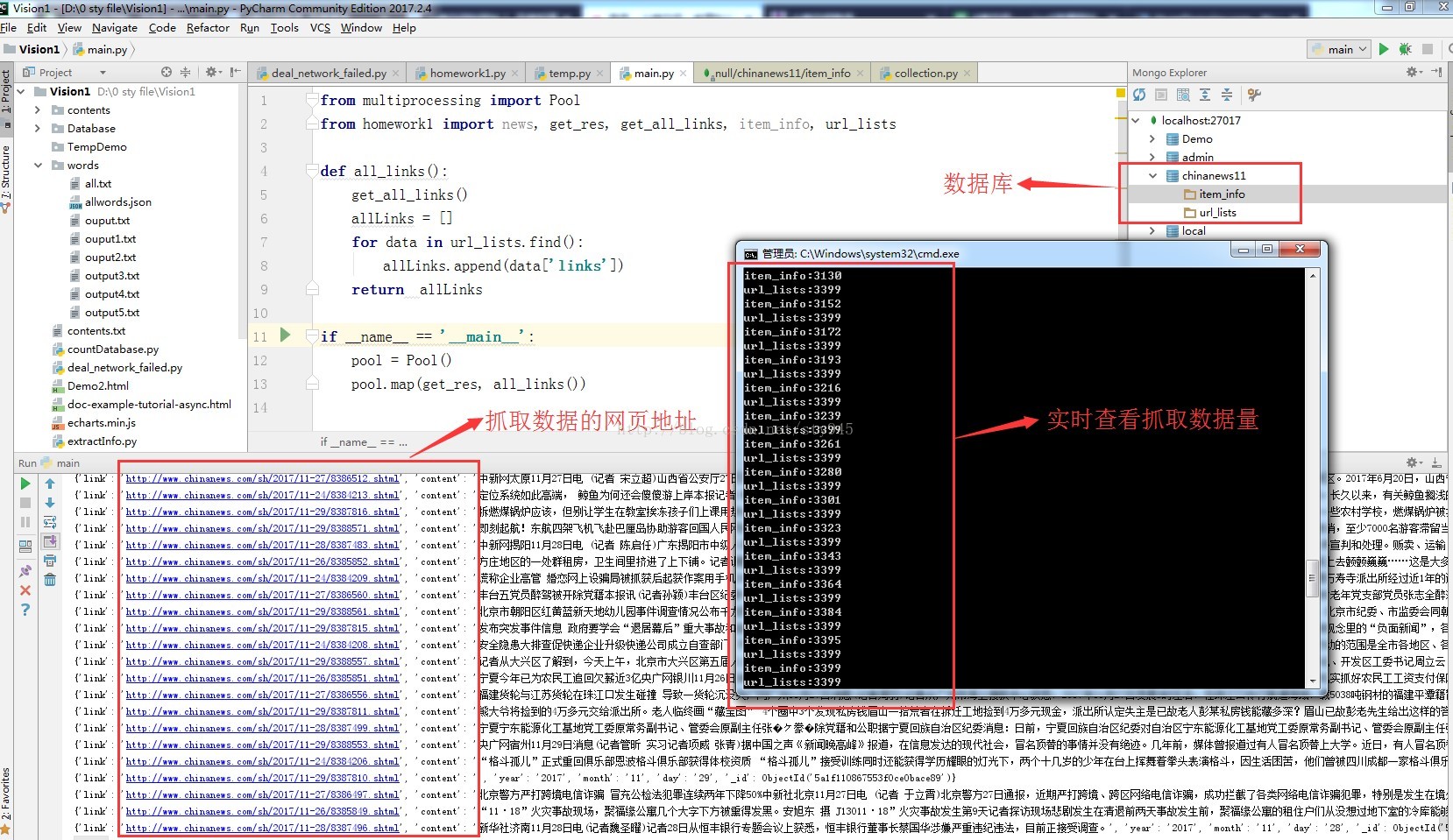
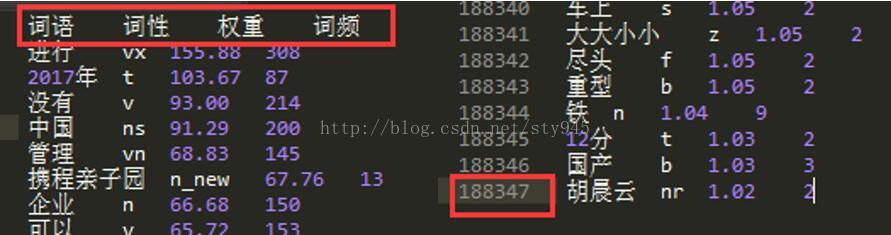
拿到这些数据我们要怎么办呢?我想知道热点事件是什么?哪些地方的热点事件最多?诸如此类的问题,我们当然可以将这些文章都看了,然后来得到一个整体的影响,但作为承担着共建我们伟大复兴中国梦的新时代计算机信息化人才,我怎么能采取如此低效的方式呢?(此处请允许小编露出八颗大牙的微笑)我将这包含着这411万字的新闻数据文档,通过计算机智能分词系统,然后经过一系列操作(此处省略若干字),毕竟我们在乎的是结果,这期间乏味的工作,小编已经做了,最后我得到了大约18万8千的关键字数据。
如下图所示,大家有没有注意到一个熟悉的幼儿园出现在数据集中,而且频次很高,这在某种程度上证明我们数据还是比较准确的,是不是很期待接下来的会有什么结果,请慢慢往下看。
为了可视化的展现这些数据,通过百度的echarts可以动态的交互的将数据以各种形式显示在网页上,但是为了在这里公众号上显示,这里我提供了静态图片供大家观看。下图为2017年11月在中国新闻网社会版块出现频率最高的名词。
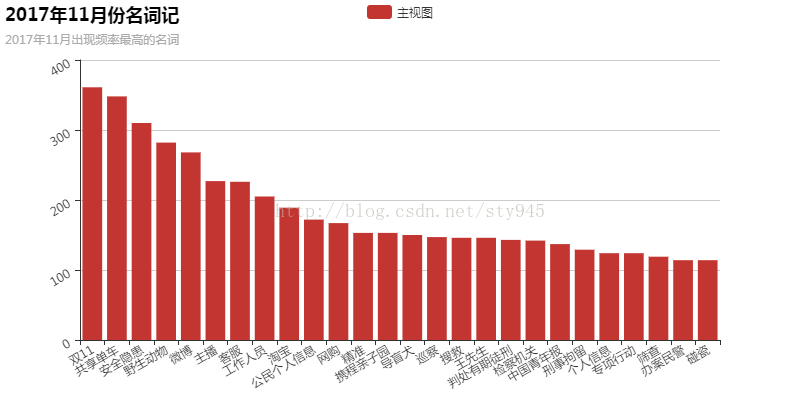
通过上图我们可以清楚的看到“双十一”毋庸置疑的占领了名词榜的榜首,'共享单车'和‘安全隐患’分别列第2、3名。共享单车的出现也不意外,在过去的十一月份各个省市都出台了一系列关于治理共享单车“乱停乱放”等现象的管理实施意见,并且随着共享单车行业进入洗牌期,多家共享单车出现的退押金难等诸多问题,让它进入我们的前三名似乎也不意外。关于第三名“安全隐患”,联系到北京大兴区西红门镇“11.18”重大火灾事故所揭露出来的诸多安全隐患问题,也不难理解。尤其值得注意的”携程亲子园”也在我们的图表中位于中等位置。而近期热点事件的另一家幼儿园并没有上榜,估计是事件太近所以数据量难免不足。其它的数据应该也是对应着一些热点信息,就不逐个解释了。
下图为2017年11月在中国新闻网社会版块出现频率最高的人名。

你知道新闻媒体在新闻报道中最喜欢用什么来指代人物么?通过上图的词云我们可以知道李某、张某、王某、陈某、刘某可以说是新闻媒体在新闻报道的最常用的五大指代名啊,这可能也间接说明这是中国最多的几个姓氏,事实呢?确实是这样的,这5大姓氏在中国大约有4亿的人口。那其它的人名有何含义呢?其他人名我们不难发现,几乎囊括了11月份重大热门案件的主角,成为了人们的关注点,其频率自然而然就提高了。是不是感觉数据真的不会骗你?
那这么多的热点事件都在什么地方发生的呢?通过下面这张11月份各省市新闻出现频率的地图热点显示图,我相信你可以直观的感受到。
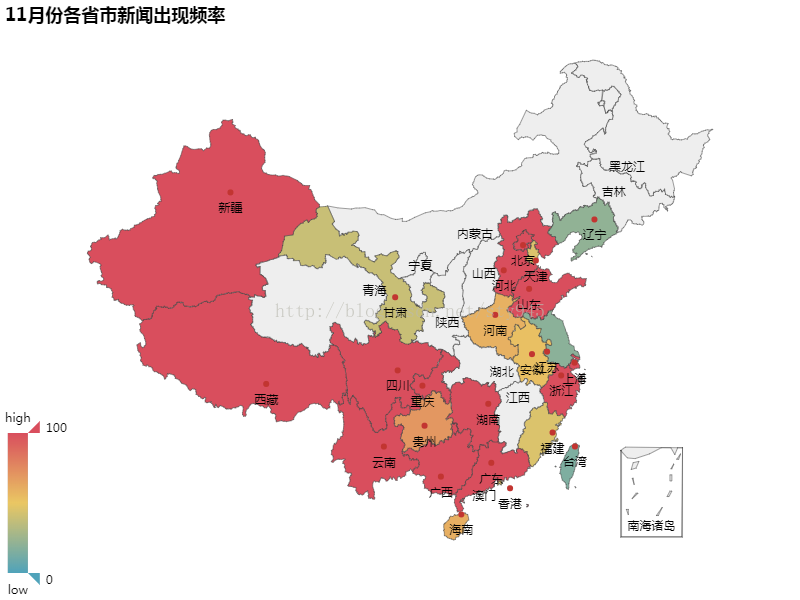
通过不同的颜色我们可以看出不同地方热点事件发生的情况,红色的表示在该地区在新闻上出现的频率很高,北京、上海、广东、新疆、西藏都排在了前列,而黑龙江、吉林、内蒙古、山西在新闻上出现的频率则远远不足。
那过去的11月份有没有什么机构在新闻中有着很高的“出镜率”呢?别说,还真有。下图这个圆环饼图表示11月份出现的高频机构。
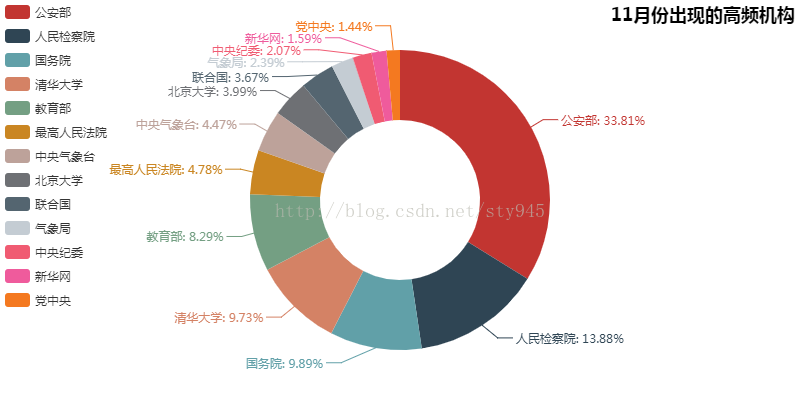
通过这个圆环饼图我们可以清楚的看出,在过去的11月里,公安部以绝对的优势占据了榜首,细想一下不难发现,几乎牵扯到广大社会人民的热点新闻事件,我们的警察叔叔第一时间出现在我们的视线里,这里向辛苦的人民警察致敬。这些机构中除了清华大学和北京大学这两所高校外,其他则以政府部门居多,毕竟我们是以社会版块的新闻为数据源进行分析的,政府部门居多更是能反映我们的国家对人民生活时刻保持关注,我为我们在生活在这个伟大的国度而自豪。
到这里,今天给大家带来的11月份基于新闻数据的可视化分析就结束了,小编对该数据的真实性负责,但是其中的分析方法和数据筛选原则难免会有些瑕疵,欢迎有兴趣的同学进行交流。
本项目的开源地址如下:
https://github.com/sty945/news_spider
如果希望学习该项目整体的思路以及如何利用NLP技术做简单数据可视化分析可以扫描下面二维码,直达详细教程:

欢迎fork和共同完善!!
转载请注明出处:
CSDN:楼上小宇_home:http://blog.csdn.net/sty945
简书:楼上小宇:http://www.jianshu.com/u/1621b29625df
这篇关于只要5分钟用数据可视化带你看遍11月份新闻热点事件的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







