本文主要是介绍智领云彭锋:云原生数据平台的最佳实践 | 甲子引力(附演讲视频下载),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

Everything On Kubernetes.
12月7日~10日,科技智库甲子光年在线上举办2022甲子引力大会。在12月9日下午的“新一代数字基础设施”专场上,智领云联合创始人&CEO彭锋就《Data on Kubernetes云原生数据平台最佳实践》发表了主题演讲。
以下为彭锋的演讲实录:
首先介绍一下我自己,我是彭锋,武汉大学硕士,2000年左右去美国读的博士,我和我的Cofounder宋文欣在读完博士之后,先后入职Ask.com、Twitter、EA三家公司,都是从无到有地搭建了它们的大数据平台,我们希望能够把我们在硅谷的工作经验形成产品,服务国内企业。
为什么数据平台会有云原生的诉求?这是Twitter十多年前的数据架构图,最近马斯克买了Twitter,开除了大概75%的员工,世界杯期间Twitter好像也没有什么事,系统都正常地运行,其实背后并不在于员工没有价值,关键在于云原生。
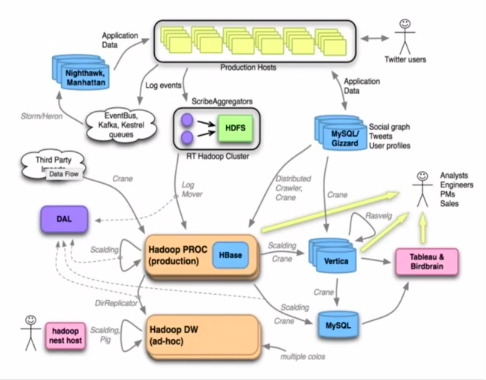
Twitter从2011年就开始建设自己内部私有云平台,所有业务系统和大数据平台全部在这个私有云上发布,实现了业务开发效率和运营效率指数级增长,系统稳定性和系统资源使用率也不断提升。Twitter大数据集群从2011年左右只有80台机器的Hadoop集群,到上市大概8000台机器全部是云原生平台,Kafka、Hadoop、Spark系统都在上面,以云原生的方式为整个公司各个部门提供数据能力矩阵,而且绝大部分都已经自动化,所以机器死掉、系统宕掉全部可以自动恢复,这么多年系统稳定性不断提高。
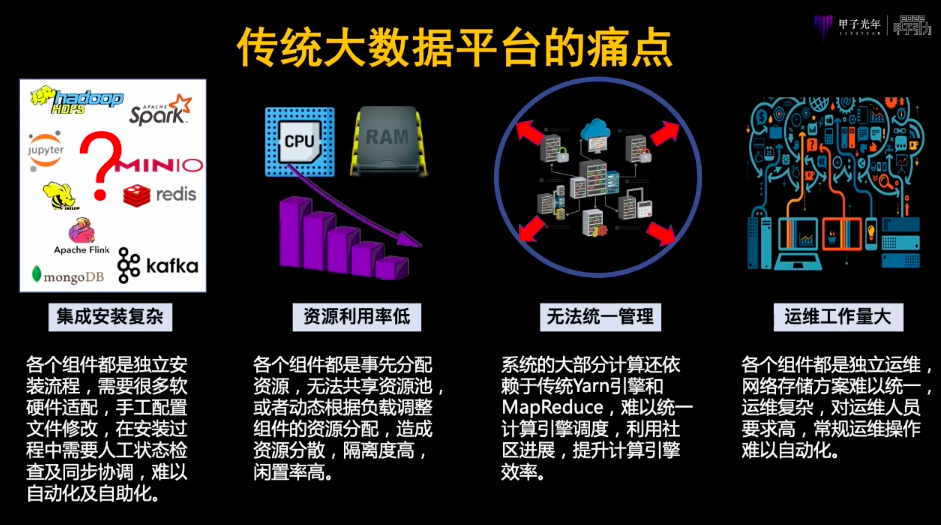
与云原生的数据平台相比,传统大数据平台有什么痛点?因为传统大数据平台比如Hadoop、HBase、Hive每一个都是独立安装流程,没法共享这个资源池,每一个都有自己运维的机制,每一个都有自己分布式管理的机制,所以系统在运行的时候不仅安装复杂,运维复杂,系统效率还特别低,而且对运维人员要求高。我们经常看到很多大企业即使集群很大,但是系统各个组件都是各自为战,没法形成统一的体系,资源效率特别低,造成特别大的问题。
原来K8s还没有那么成熟的时候,对大数据支持比较差,大家没办法在K8s上跑大数据应用。但是一旦K8s相对成熟之后,各种各样的系统都可以在K8s上运行,大家都想我能不能不要Hadoop,实现Cloud Native Data Platform without Hadoop,能够把业务系统、数据系统、应用系统一块跑。Hadoop的三架马车,HDFS、Yarn和MapReduce,都会有Kubernetes上的方案来解决对应的任务,特别最近两年K8s对有状态服务的支持越来越好。所以,大家都想现在所有的业务系统在K8s跑了,可以一起管了,可以共享资源、可以共享工具、可以一起统计它的各种使用了,为什么大数据系统还要单独去搞一套呢?
去年有两个标志性事件,一个是Apache Spark从3.1开始官方支持K8s,第二是Kafka去年5月也开始官方支持K8s,这两个事件就标志着最核心的大数据组件现在都支持K8s。据Gartner预测,部署在云原生平台上的数据应用将由2021年的30%增长到2025年的95%,就是说基本上到2025年,95%的数据应用都会跑在云原生平台上,这个云原生平台大概率就是K8s。
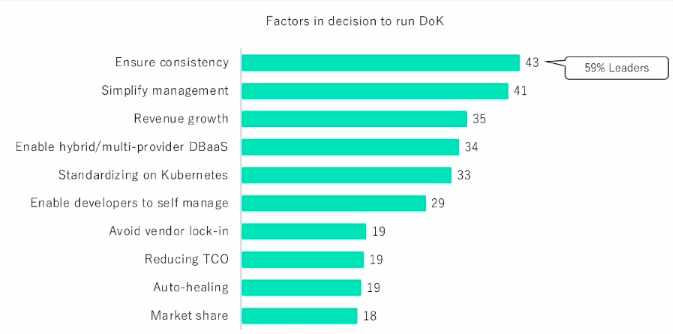
有这个趋势之后,就出来一个名词叫做Data on Kubernetes,也是今天我们介绍一个主题,这个词还比较新,今年10月份北美的KubeCon刚刚结束,第一次组织了Data on Kubernetes专场,讲如何在Kubernetes跑数据应用。在DoK社区组织的行业报告中,展示的就是这些使用Data on Kubernetes的企业,为什么要把这些应用迁移到Kubernetes上,基于前两位的就是保证管理的统一性以及简化管理。
在国内实践中我们碰到的主要场景有下面四个。第一个是标准化管理,如何将发布运维标准化,怎么能够让大数据平台和业务系统同时使用K8s一套基础架构和运维工具;第二个是项目部署。有很多系统集成商和软件开发的客户,在项目实施和运维中他们想使用统一的集群发布,提升部署的速度,提升系统的稳定性,降低系统对硬件的要求,简化运维要求。第三是有些大企业里面,资源效率特别低,买了几百台机器,平时每个机器大概10%到15%的利用率,Hadoop Data node不能去跑AI的应用,它的任务完全没法去混排,所以资源使用效率特别低,系统资源得不到有效利用,部门计算能力有新要求的时候又必须购买新的硬件,效率很低。第四个场景就是所谓的DPaaS (Data Platform as a Service)。有很多大集团企业希望能够在完善的多租户管理体系下,为各个部门和团队提供各自数据组件的安装集成,让他们自助去完成数据应用开发。

这个解决方案就是Everything On Kubernetes,核心的变化就是把大数据组件和大数据应用的发布与运维,用Kubernetes来标准化,解决刚才所提到的问题。这里面有个问题,Data on Kubernetes是不是只要把大数据组件容器化装到K8s上就可以了?毕竟现在像Spark、Kafka都已经官方支持了,像MySQL、Redis也有一些官方和社区提供的容器化的解决方案,甚至K8s云原生方案,除了把它们装起来还需要干什么呢?
其实容器化只是云原生数据架构六大特征之一,仅仅容器化并不代表云原生,云原生还需要提供可观测性,支持流水线即代码,还要支持多租户和命名空间的完善管理,需要应用都是面向服务的发布,需要提供基础架构的无关性,可以随时在混合云上发布,可以在一个新的集群上完整发布以前的架构,这种都是云原生数据架构的特征,不仅仅是容器化一项工作就可以解决的。

所以在社区所做的容器化工作之上,还需要以云原生的方式来运行现在大数据组件,并让它们在统一平台上能够高效地运行。比如说,原来有很多大数据组件只能使用主机网络,不能用云原生网络栈;比如说存储只能在本机上,不能使用云原生的PV,这些都需要做一些改造;比如说原来很多组件,像kerberos发布,有很多只能使用NFS发布,无法做弹性的扩容。把这些大数据组件完整地集成到一起,能够以一个云原生的集成方式工作,这是我们需要做的工作。
第一我们需要有个集成框架,让所有组件以标准化的方式集成进来;第二集成进来之后需要把它们以一种标准化方式发布到K8s平台上,他们之间有依赖的时候我们怎么处理,一个组件配置发生改变,他依赖的组件如何来进行相应的改变,如何在一个系统实现自动扩容和加容,如何实现系统发现问题的时候能够自动迁移,这都是发布服务需要解决问题;我们还要提供可观测性服务,一个系统组件接进来之后,它所有的资源使用情况,它的监控报警必须自动来接入,我们还需要把所有组件通过统一的调度来共享这个资源池,如果所有组件都是自己来调度,就达不到云原生这种调度支持的要求,所以说我们必须在存算分离基础上能够统一调度。
这些工作都不是各个组件自己能做的,需要在各个组件的基础上来做。但我们认为这个工作不需要每个企业自己来做,所以我们就提供了Kubernetes Data Platform,简称KDP。给大家简单介绍一下KDP大致的思路,KDP是完全基于Kubernetes发布的云原生大数据平台,它所有组件都是K8s上发布,实现刚才所说的所有功能,也对大数据组件进行了需要的云原生改造。简单来讲,如果你有一个K8s Account,我就可以给你一个大数据平台。我们已经与各种的公有云、私有云上的Kubernetes的版本成功对接,阿里云、AWS、腾讯云、华为云、天翼云、金山云都可以快速发布使用。
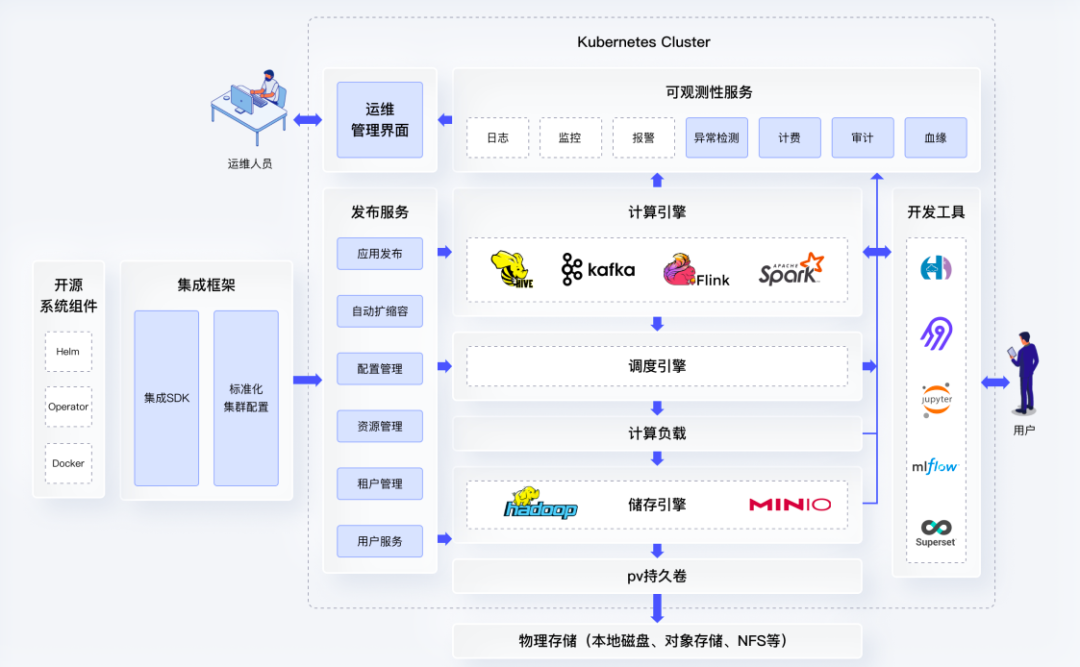
这里面还是有很多工作要做,并不是简单把这些组件装起来就可以了。首先我们对很多现代大数据核心组件进行代码级别的改造,以支持K8s资源调度、网络、存储,保证他们以云原生的方式来进行。第二我们以这种Operator / Helm chart方式来实现发布和运维的标准化、自动化,扩容、降容都可以自动完成,绝大部分操作都不需要人工干预;第三是我们扩展并强化了这种多租户环境,提供了各种安全认证鉴权机制,采用统一云原生的Kerberos方式和Ranger的方式来进行授权和鉴权,让我们用K8s的命名空间实现了多租户的管理,资源隔离,实现了按区域动态资源分配,并实现计费和审计。
我们基于OAM统一标准发布各种应用以及管理流程,打通了各个组件之间的配置管理,应用配置变化的时候其他相应的配置全部自动发生调整,实现Infra as Code;我们对计算引擎在云原生形态下进行优化,比如Volcano批处理的调度,解决了Spark on HDFS的Data Locality,保证所有的组件在一个系统中能够在云原生环境下高效实现数据的计算。此外,我们把日志、监控、报警、异常检测、计费、审计都做成统一的框架,所有的组件一旦接入都可以明确地在可观测性服务中监控,在统一界面来进行管理。
最后简单总结一下,我们认为KDP是面向未来的数据基础架构,提供标准化大数据组件的部署和运行。我们在实践中看到部署效率之前按天计,现在变成按小时计,以前资源效率10%、20%,现在我们可以达到50%、60%,运维效率得到极大提高,绝大多数运维操作是高度自动化,我们在各个项目中看到的整体效率都得到非常大的提升。
所以我们这次推出的Kubernetes Data Platform,希望能够为大家从传统大数据平台到云原生架构的大数据平台转换提供一些帮助。目前,我们KDP正式在全国招募合作伙伴和客户,如果有需要在K8s运行你的大数据平台,或者是需要在K8s上服务客户的大数据需求,可以联系我们,最后也非常感谢甲子光年给我们提供这个机会,给大家介绍我们一些进展,祝大会圆满成功,谢谢大家!
END.
关注智领云科技公众号,回复“甲子引力”获取视频回放

点击阅读原文,详细了解首款完全基于K8s的大数据平台KDP
这篇关于智领云彭锋:云原生数据平台的最佳实践 | 甲子引力(附演讲视频下载)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




