本文主要是介绍拯救pandas计划(12)——转换包含np.nan的float64类型列为int64类型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
拯救pandas计划(12)——转换包含np.nan的float64类型列为int64类型
最近发现周围的很多小伙伴们都不太乐意使用pandas,转而投向其他的数据操作库,身为一个数据工作者,基本上是张口pandas,闭口pandas了,故而写下此系列以让更多的小伙伴们爱上pandas。
系列文章说明:
系列名(系列文章序号)——此次系列文章具体解决的需求
平台:
windows 10
python 3.8
pandas >=1.2.4
/ 数据需求
数据如下,需要将其中的浮点型数据转换为整型数据。
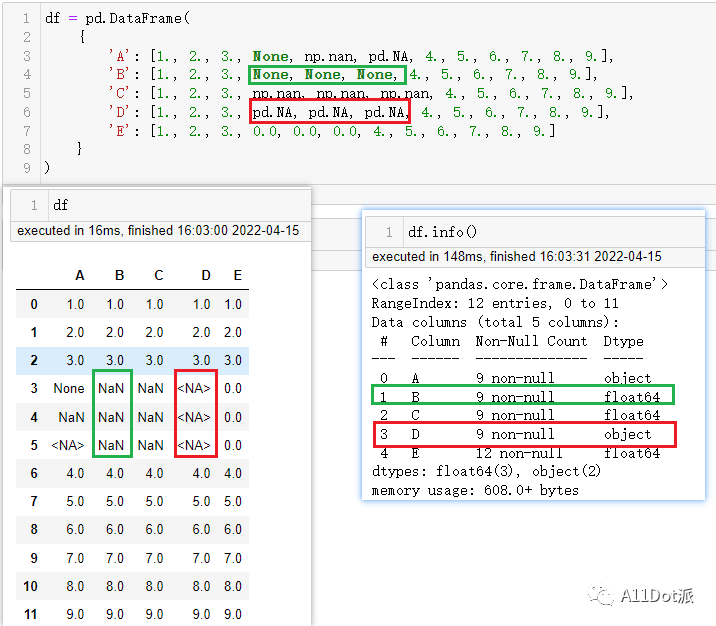
df = pd.DataFrame({'A': [1., 2., 3., None, np.nan, pd.NA, 4., 5., 6., 7., 8., 9.],'B': [1., 2., 3., None, None, None, 4., 5., 6., 7., 8., 9.],'C': [1., 2., 3., np.nan, np.nan, np.nan, 4., 5., 6., 7., 8., 9.],'D': [1., 2., 3., pd.NA, pd.NA, pd.NA, 4., 5., 6., 7., 8., 9.],'E': [1., 2., 3., 0.0, 0.0, 0.0, 4., 5., 6., 7., 8., 9.]}
)打印出样式和各列的类型,看出圈出的两列数据发生了微妙的改变,None在浮点型数据丛中自动转换成了np.nan,而pd.NA以<NA>显示,列类型除[0, 3]列外都是float64,似乎是pd.NA让列类型变化了。
/ 需求拆解
众所周知,在python中的numpy模块,独自闯出了一片天地,很多关于数据处理,科学计算,机器学习的模块会使用numpy模块,而其中的numpy.nan(以下称为np.nan)多多少少带点迷惑性,在python中空值使用None填充,而在更多的数据科学中使用的是np.nan,更令人奇怪的是np.nan是浮点型数据,在pandas模块为了解决这种情形,也设置了一个空类型属性`pandas.NA(以下称为pd.NA),在pandas中能够更好的适应数据的变化。
>>> None == None
True
>>> type(np.nan)
float
>>> np.nan == np.nan
False
>>> type(pd.NA)
pandas._libs.missing.NAType
>>> pd.NA == pd.NA
<NA>在这一例中,因为np.nan在数据列中是无法进行整型化,一种是可以将数据框转化为二维列表再遍历其中的列表将所有浮点数转换,另一种则是将np.nan转换为pd.NA,适应pandas结构,再转换各自的列。
可能注意到,上述没有提及None,None是一个随性的值,当有pd.NA存在时保持本性,而没有时就会随列类型变化,如B列中的None。
/ 需求处理
在pandas里有几种方法可以转换数据类型,这里试用一些方法,将每列都转换成int类型:
astype(int)
>>> df['A'].astype(int)
TypeError
...
TypeError: int() argument must be a string, a bytes-like object or a number, not 'NoneType'>>> df['B'].astype(int)
ValueError
...
ValueError: Cannot convert non-finite values (NA or inf) to integer>>> df['C'].astype(int)
ValueError
...
ValueError: Cannot convert non-finite values (NA or inf) to integer>>> df['D'].astype(int)
TypeError
...
TypeError: int() argument must be a string, a bytes-like object or a number, not 'NAType'>>> df['E'].astype(int)
0 1
1 2
2 3
3 0
4 0
5 0
6 4
7 5
8 6
9 7
10 8
11 9
Name: E, dtype: int32每列都操作完后,几乎全军覆没,除了E列中所有的数都是有效数字外可以完成目标,其他的都发生了报错,报错原因基本都是int这个函数不能转换空值或者无效值。
map(int)
map(int)执行效果与上一个方法一样。但在pandas.map里可以使用函数,对每个值进行判断如果是空值则返回pd.NA,否则转换为int类型。
>>> df['A'].map(lambda x: pd.NA if pd.isna(x) else int(x))
0 1
1 2
2 3
3 <NA>
4 <NA>
5 <NA>
6 4
7 5
8 6
9 7
10 8
11 9
Name: A, dtype: object后续的几列都能够完成转换,虽然类型转为了object,通过值判断可以确定已经将之前的浮点型数据转换为整型了。
可能会想,使用pd.NA可以转化成功,那么使用np.nan呢,具体原因在前文已经说明,不再赘述,可以自行测试。
(手动水印:原创CSDN宿者朽命,https://blog.csdn.net/weixin_46281427?spm=1011.2124.3001.5343,公众号A11Dot派)
astype('Int64')
pandas中的astype还可以转换为pandas中的Int64Dtype类型,注意astype中的大小写,其中的数字为整型,空值为pd.NA。转换效果与map(lambda x: ...)一样,不同处是列类型,这里为Int64Dtype,该类型可能在后续操作会有部分限制。
>>> df['A'].astype('Int64')
0 1
1 2
2 3
3 <NA>
4 <NA>
5 <NA>
6 4
7 5
8 6
9 7
10 8
11 9
Name: A, dtype: Int64
>>> df['C'].astype('Int64')/ 总结
简单的介绍了在数据框中包含空值,且需要将其中的浮点型数据转换为整型数据如何处理,因为在numpy中定义nan为浮点型数据,比通常的浮点型数据,如1.1之类的有多了些特性,在pandas中的部分操作中可能无法满足自身要求,这时不妨试试pandas中pd.NA来代替np.nan的使用,在平平凡凡的数据里也有多样的天空。
道可道,非常道。
于二零二二年四月十五作
这篇关于拯救pandas计划(12)——转换包含np.nan的float64类型列为int64类型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





