本文主要是介绍探索C语言中的联合体与枚举:数据多面手的完美组合!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
✨✨ 欢迎大家来到贝蒂大讲堂✨✨
🎈🎈养成好习惯,先赞后看哦~🎈🎈
所属专栏:C语言学习
贝蒂的主页:Betty‘s blog

1. 联合体的定义
联合体又叫共用体,它是一种特殊的数据类型,允许您在相同的内存位置存储不同的数据类型。给联合体其中⼀个成员赋值,其他成员的值也跟着变化。
2. 联合体基础
2.1 联合体声明
联合体的结构类似于结构体,由关键字union和多个成员变量组成。格式如下:
union [union tag]
{
member definition;
member definition;
…
member definition;
} [one or more union variables];
- union tag 是你自己定义的,每个 member definition 是标准的变量定义,比如 int i; 或者 float f; 或者其他有效的变量定义。在共用体定义的末尾,最后一个分号之前,您可以指定一个或多个共用体变量,这一点和结构体类似。
(1) 普通联合体
union data
{int n;char ch;
};
(2) 嵌套联合体
联合体也是可以嵌套使用的。
union Un1
{char c[5];int i;
};
union Un2{int n;union Un1 u1;
};
(3) 匿名联合体
匿名联合体是一种特殊联合体,省略了联合体名称,这种联合体只能在其定义的代码块内使用一次。例如,如果你在一个函数内部定义了一个匿名联合体,则该联合体只能在该函数内部使用。当代码块执行完毕后,该联合体将不再可见。
union
{int n;char ch;
};
(4) typedef联合体
我们也可以使用typedef简化联合体。
typedef union Un1
{char c[5];int i;
}Un1;//之后可以使用Un1代替union Un1
2.2 联合体变量的创建与初始化
联合体变量创建除了在创建联合体时候定义,也可以在主函数内定义并且同时能够对齐初始化。
用例如下:
union Un
{char c;int i;
};
int main()
{//联合体的初始化union Un u1 = { 'a',0 };//错误union Un u2 = { 0 };//正确return 0;
}
- 联合体的初始化只能使用一个值,因为联合体的所有成员共享同一块内存空间。
2.3 访问联合体
为了访问联合体的成员,我们使用成员访问运算符(.)。成员访问运算符是联合体变量名称和我们要访问的共用体成员之间的一个句号。下面是一个实例:
#include<string.h>
typedef union Un1
{char c[10];int i;
}Un1;int main()
{Un1 u = { 0 };printf("%d ", u.i);printf("%s ", strcpy(u.c, "abcdef"));return 0;
}
输出结果:

3. 联合体的内存存储
3.1 联合体的大小
联合体的大小是其成员变量大小之和,还是和结构体一样遵循某种特殊规律呢?我们通过以下代码实验一下。
union Un
{char c[5];int i;
};
int main()
{union Un u2 = { 0 };printf("大小为%zd", sizeof(union Un));return 0;
}
输出结果:

通过验证我们知晓联合体的大小并不是其成员变量大小之和,也是遵循某种特定的规律。
那么这种规律到底是什么呢?其实很简单
- 联合的⼤⼩⾄少是最⼤成员的⼤⼩。
- 当最⼤成员⼤⼩不是最⼤对⻬数的整数倍的时候,就要对⻬到最⼤对⻬数的整数倍。
- 对⻬数=编译器默认的⼀个对⻬数与该成员变量⼤⼩的较⼩值。(VS 中默认的值为 8 ,Linux中gcc没有默认对齐数,对⻬数就是成员⾃⾝的⼤⼩)
3.2 存储形式
知道了联合体的大小,我们也就会很容易知道它的内存存储方式了。下面有具体四个样例:
(1) 样例一
#include <stdio.h>
union Un
{char c;int i;
};
int main()
{//联合变量的定义union Un un = { 0 };// 下⾯输出的结果是⼀样的吗?printf("%p\n", &(un.i));printf("%p\n", &(un.c));printf("%p\n", &un);return 0;
}
输出结果:

- 通过这次实验我们联合体从起始位置开始共用的
(2) 样例二
#include <stdio.h>
//联合类型的声明
union Un
{char c;int i;
};
int main()
{//联合变量的定义union Un un = { 0 };un.i = 0x11223344;un.c = 0x55;printf("%x\n", un.i);return 0;
}
输出结果:

示意图:
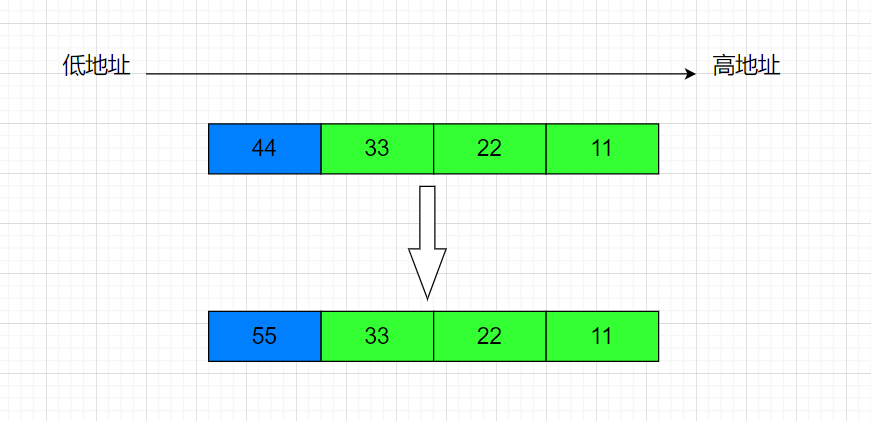
- 蓝色为共用部分,绿色为非共用部分
- VS编译器为小端存储
(3) 样例三
#include <stdio.h>
union Un1
{char c;int i;
};
int main()
{// 下⾯输出的结果是什么?printf("大小为%d\n", sizeof(union Un1));return 0;
}
输出结果:

示意图:

解析:
- c的大小为一个字节,i的大小为四个字节,他们共用一个字节。
- 最大对齐数为4,结构体大小此时刚好为4,是最大对齐数的整数倍。
(4) 样例四
#include <stdio.h>
union Un2
{short c[7];int i;
};
int main()
{// 下⾯输出的结果是什么?printf("大小为%d\n", sizeof(union Un2));return 0;
}
输出结果:

示意图:

解析:
- short大小为2,c中有7个大小为14,i大小为4,共用四个字节。
- 最大对齐数为4,联合体大小为最大对齐数的整数倍,为16。
4. 利用联合体判断大小端
我们早在学习数据在内存中如何存储时就已经了解过一种判断大小端的方法,今天就为大家介绍另一种方法——通过联合体判断大小端,
还是这幅图,我们要判断大小端就需要判断第一位存储到底是01还是00。

那如何取出第一位呢?除了通过指针,我们也能利用联合体共用同一块内存这一性质判断。
代码如下:
int check_sys()
{union{int i;char c;}un;un.i = 1;return un.c; //返回1是⼩端,返回0是⼤端
}
int main()
{int ret = check_sys();if (ret == 1){printf("⼩端\n");}else{printf("⼤端\n");}return 0;
}
5. 联合体的应用
通过联合体我们可以节省一部分内存。比如:我们要搞⼀个活动,要上线⼀个礼品兑换单,礼品兑换单中有三种商品:图书、杯⼦、衬衫。每⼀种商品都有:库存量、价格、商品类型和商品类型相关的其他信息。
其他信息:
图书:书名、作者、⻚数
杯⼦:设计
衬衫:设计、可选颜⾊、可选尺⼨
我第一想法是通过一个结构体定义:
struct gift_list
{//公共属性int stock_number; //库存量double price; //定价int item_type; //商品类型//特殊属性char title[20]; //书名char author[20]; //作者int num_pages; //⻚数char design[30]; //设计int colors; //颜⾊int sizes; //尺⼨
};
上述的结构其实设计的很简单,⽤起来也⽅便,但是结构的设计中包含了所有礼品的各种属性,这样使得结构体的⼤⼩就会偏⼤,⽐较浪费内存。但是对于礼品兑换单中的商品来说,只有部分属性信息是常⽤的。⽐如:商品是图书,就不需要design、colors、sizes。所以我们就可以把公共属性单独写出来,剩余属于各种商品本⾝的属性使⽤联合体起来,这样就可以介绍所需的内存空间,⼀定程度上节省了内存。
通过联合体定义:
struct gift_list
{int stock_number; //库存量double price; //定价int item_type; //商品类型union {struct{char title[20]; //书名char author[20]; //作者int num_pages; //⻚数}book;struct{char design[30]; //设计}mug;struct{char design[30]; //设计int colors; //颜⾊int sizes; //尺⼨}shirt;}item;
};
6. 枚举的定义
在 C 语言中,枚举(enum)是一种用户定义的数据类型,用于定义一个由标识符列表组成的整数常量集合。枚举类型通过关键字 enum来定义。
在实际应用中我们经常把能够且便于一一列举的类型用枚举来表示。就比如:一周的星期、一年的月份……,其基本语法如下:
enum 枚举类型名
{
标识符1,
标识符2,
…
};
- 枚举类型名受自己定义,如:week,year…,标识符就是其中的枚举常量,如Mon,Tues,Wed…
- 每个枚举常量可以用一个标识符来表示,也可以为它们指定一个整数值,如果没有指定,那么默认从 0 开始递增。
7. 枚举基础
7.1 枚举的声明
(1) 普通枚举
接下来我们举个例子,比如:一星期有 7 天,如果不用枚举,我们需要使用 #define 来为每个整数定义一个别名:
#define MON 1
#define TUE 2
#define WED 3
#define THU 4
#define FRI 5
#define SAT 6
#define SUN 7
这个看起来代码量就比较多,接下来我们看看使用枚举的方式:
enum DAY
{MON=1, //指定从1开始,否则默认从0开始TUE,WED,THU, FRI, SAT, SUN
};
(2) 匿名枚举
和匿名结构体与匿名联合体类似,枚举也有匿名类型。
enum
{APPLE,BANANA,ORANGE
};
(3) typedef枚举
我们也可以使用typedef简化枚举。
typedef enum DAY
{MON = 1, //指定从1开始,否则默认从0开始TUE,WED,THU,FRI,SAT,SUN
}DAY;
7.2 打印枚举常量
typedef enum DAY
{MON, TUE,WED,THU,FRI,SAT,SUN
}DAY;
int main()
{for (int i = MON; i < SUN; i++){printf("%d ", i);}return 0;
}
输出结果:

- 这也间接证明枚举是一个常量,默认从0开始。
7.3 枚举变量的创建与初始化
我们可以利用定义的枚举常量对枚举变量进行赋值。
typedef enum DAY
{MON, TUE,WED,THU,FRI,SAT,SUN
}DAY;
int main()
{DAY a = MON;//最好用枚举常量赋值return 0;
}
- 那是否可以拿整数给枚举变量赋值呢?在C语⾔中是可以的,但是在C++是不⾏的,C++的类型检查⽐较严格。
8. 枚举常量的大小
枚举常量的大小同 int 的大小一样,都是四个字节。
我们可以通过以下代码来实验:
#include <stdio.h>
enum color1
{RED,GREEN,BLUE
};enum color2
{GRAY = 0x112233445566,YELLOW,PURPLE
};int main()
{printf("enum color1: %d\n", sizeof(enum color1));printf("enum color2: %d\n", sizeof(enum color2));return 0;
}输出结果:

9. 枚举的优点
乍一看,我们可能会感觉枚举有点画蛇添足的感觉,那使用枚举到底有哪些优点呢?
优点:
- 增加代码的可读性和可维护性
- 和#define定义的标识符⽐较枚举有类型检查,更加严谨。
- 便于调试,预处理阶段会删除 #define 定义的符号
- 使⽤⽅便,⼀次可以定义多个常量
- 枚举常量是遵循作⽤域规则的,枚举声明在函数内,只能在函数内使⽤
10. 枚举的应用
枚举的使用常与switch语句联系起来。
#include <stdio.h>
int main()
{enum color { red = 1, green, blue };enum color favorite_color;/* 用户输入数字来选择颜色 */printf("请输入你喜欢的颜色: (1. red, 2. green, 3. blue): \n");scanf("%d", &favorite_color);/* 输出结果 */switch (favorite_color){case red:printf("你喜欢的颜色是红色\n");break;case green:printf("你喜欢的颜色是绿色\n");break;case blue:printf("你喜欢的颜色是蓝色\n");break;default:printf("你没有选择你喜欢的颜色\n");}return 0;
}这篇关于探索C语言中的联合体与枚举:数据多面手的完美组合!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







