本文主要是介绍假设检验的过程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
假设检验的核心思想是小概率事件在一次实验中不可能发生,假设检验就是利用小概率事件的发生进行反正。学习假设检验,有几个概念不能跳过,原假设、p值
1.原假设
假设检验的基本过程如下:
1)做出一个假设H0,以及它的备择假设H1,注意,H0一般实验组和对照组无差异
2)在H0成立的情况下,根据置信度构造一个小概率事件。(显著性水平一般设为5%,即在H0成立的情况下,发生的可能性,这也就是我们说的小概率事件)
显著性水平和P值是假设检验中关键的两个概念,显著性水平
是认为定义的用于判断是否是小概率事件的阈值,低于该阈值,则认为是小概率事件,也是可以接受判断发生错误的概率。
显著性水平,是当原假设H0为真时,可以容忍的第一类错误(本来正确的判断为不正确的错误,之所以
选择第一类错误进行计算标准,是因为我们觉得第一类错误更严重,比方说上了个实验,本来没效果,判断为有效果,相对于有效果,判断为没效果,对业务影响更大)发生的概率,是认为定义的小概率事件发生的最大概率值。

2.统计功效
第二类错误也应该避免,因为如果第二类错误发生的概率过高,会导致错失发展机会,因此,为了控制第二类错误,引入功效概念,即当H0不成立时,做出拒绝H0的结论正确的概率=1-第二类错误发生的概率,功效越高,发生第二类错误的概率越小。
综上,P值是小概率事件实际发生的概率,P值<,证明小概率事件发生,拒绝H0,接受H1,认为策略有效;否则,不能拒绝H0,但不代表接受H1, 我们需要进一步看功效,若功效>80%(一般情况下),证明犯第二类错误的概率很低,说明策略大概率是无效的,若功效<80%,说明有效判断为无效的概率比较大,但是也可能是真没效果,可以通过增加样本量n的方法继续观察。
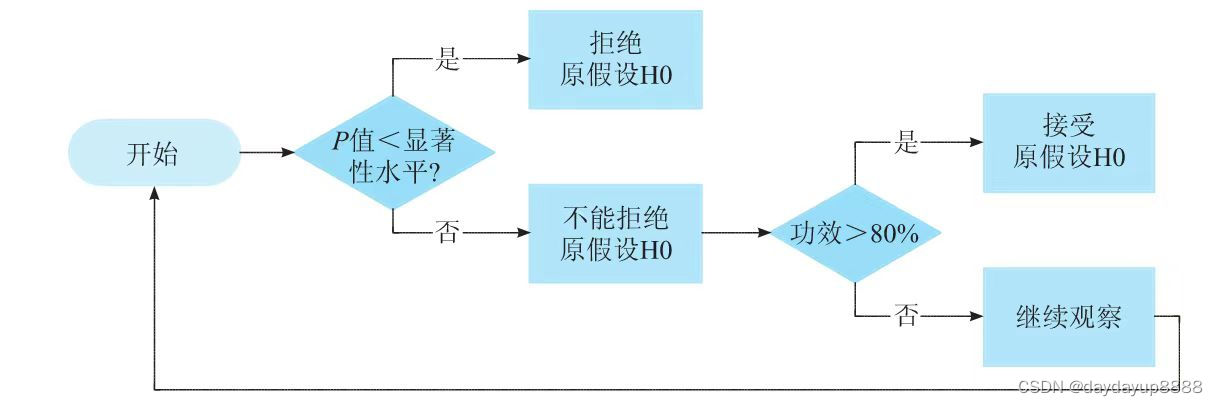
3.p值和统计功效的计算
在正态分布时,P值与t值(在下面公式中,假设了两个组别的方差是一样的)有对应关系,求p值可以转化为求检验统计量t值。在现成的t检验,输出的结果包括P值,置信区间,两个样本的均值。
通过构造t分布(是一个概率密度曲线,与正态分布很像,5%的显著性水平,对于t值>=1.96或t值<=-1.96, 双边的),计算在实际发生的概率,得到p值。
set.seed(123)
group1 <- rnorm(100, mean = 50, sd = 10)
group2 <- rnorm(100, mean = 50, sd = 10)# 使用t.test()函数进行两样本t检验
t.test(group1, group2, alternative = "two.sided")得到结果
Welch Two Sample t-testdata: group1 and group2
t = 1.4886, df = 197.35, p-value = 0.1382
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:-0.6428618 4.6019159
sample estimates:
mean of x mean of y 50.90406 48.92453 统计功效:,这里的u指的是我们认为两组数据真实的差值为u
设
公式变为
当u=0.05时,计算
这篇关于假设检验的过程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









