本文主要是介绍【数据结构】链表OJ面试题2《分割小于x并排序链表、回文结构、相交链表》+解析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.前言
前五题在这http://t.csdnimg.cn/UeggB
休息一天,今天继续刷题!
2.OJ题目训练
1. 编写代码,以给定值x为基准将链表分割成两部分,所有小于x的结点排在大于或等于x的结点之前 。链表分割_牛客题霸_牛客网
思路
既然涉及到链表分割并且原本的数据的顺序不能改变,那我们就要用到两个新的链表来存放值,一边存放小于x的,右边按顺序存放大于x的,最后再将两个链表连起来形成新的链表,就可以完成此题。
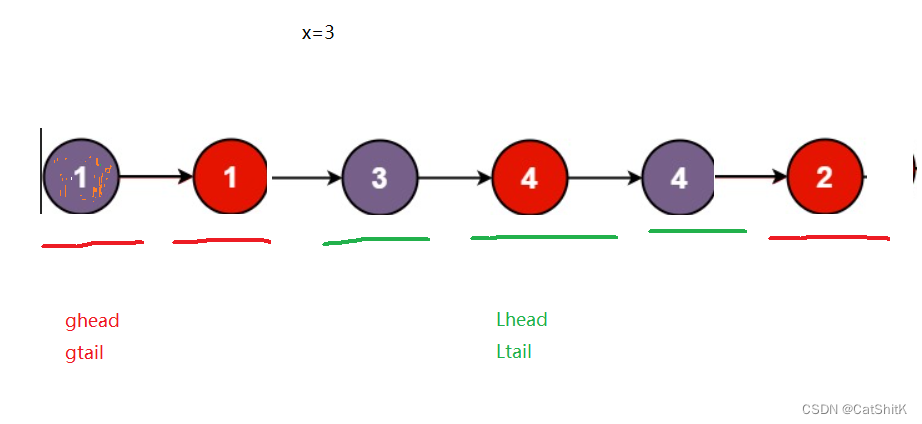
整个链表,红色底线为小于3的值,大于为绿色底线
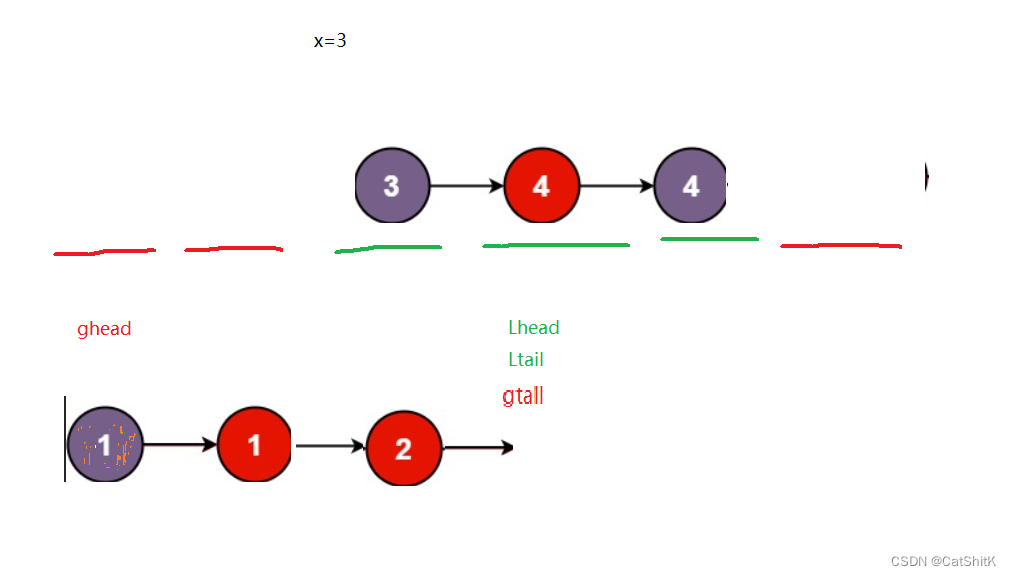
遍历整个表将小于x的值放入ghead中,同时更新gtail的值。

再将大于等于x的值放入Lhead表中,更新Ltail的值
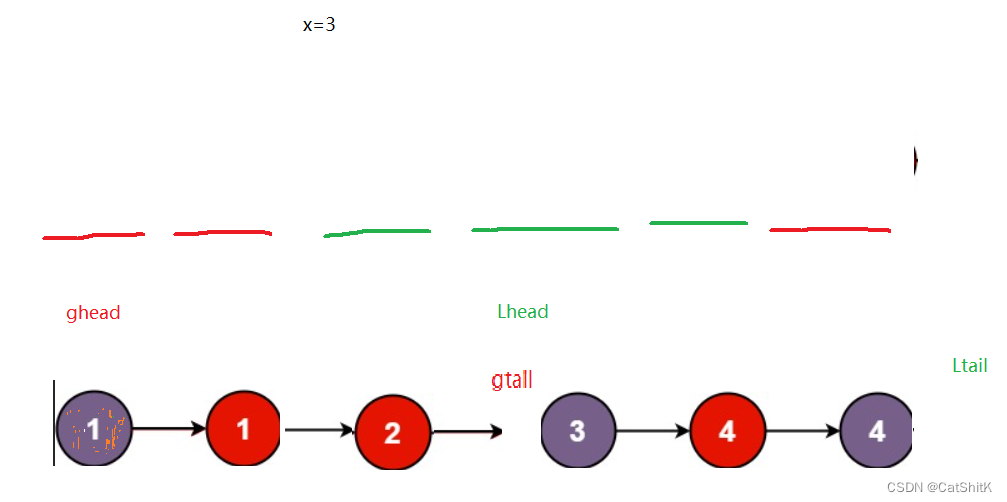
最后再通过gtail(前表尾节点)和Lhead(后表头节点)相连。返回ghead既为合并的表。
注意要点
- 涉及到改变头节点的方法,应该添加标兵节点,这样若其中一个表为空,也不会报错
-
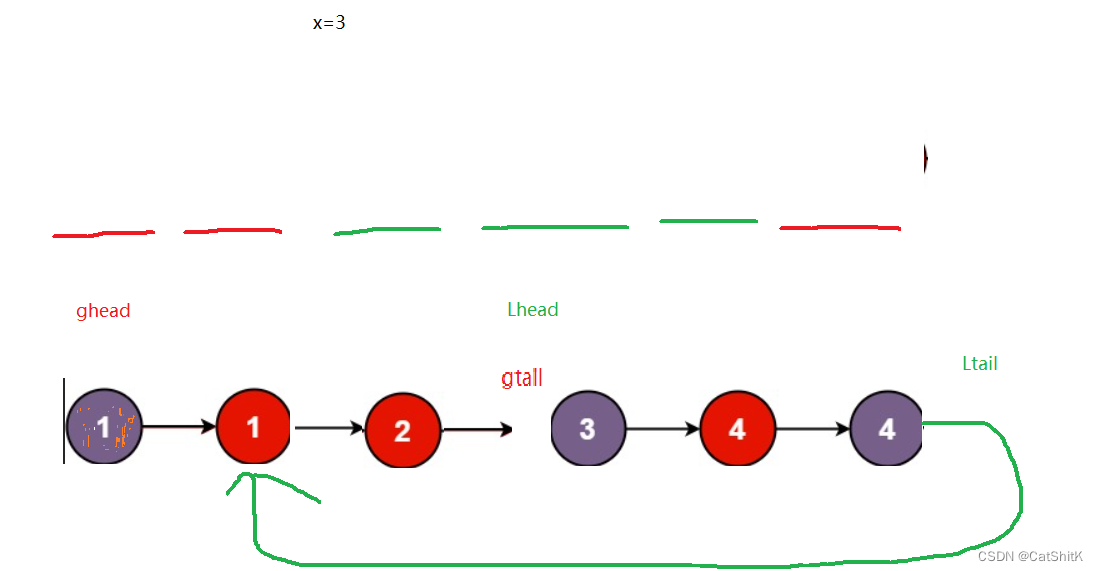
比x小的值在比x大的值后面的情况,那他就会指回L表,造成回环(假设第二个1本来是在4的后面,所以4的next节点还是指向1)
-
释放标兵节点
附源代码
/*
struct ListNode {int val;struct ListNode *next;ListNode(int x) : val(x), next(NULL) {}
};*/
#include <cstdlib>
class Partition {
public:ListNode* partition(ListNode* pHead, int x) {// write code herestruct ListNode *ghead,*gtail,*Lhead,*Ltail;ghead = gtail = (struct ListNode *) malloc(sizeof(struct ListNode));Lhead = Ltail = (struct ListNode *) malloc(sizeof(struct ListNode));struct ListNode *cur = pHead;while(cur){if(cur->val<x){Ltail->next = cur;cur = cur->next;Ltail=Ltail->next;}else {gtail->next = cur;cur = cur->next;gtail=gtail->next; }}Ltail->next = ghead->next;struct ListNode * a = Lhead->next;gtail->next = NULL; //防止比x大的最后一个值下一个节点指向其他的值(比x小的值在他后面的情况,那他就会指回L表,造成回环)free(Lhead);free(ghead);return a;}
};2. 链表的回文结构。
链表的回文结构_牛客题霸_牛客网
首先科普一下回文

可以形象的理解为:正态分布就为回文,反之不是。
方法
由于回文的基本特性我们可以,将回文分成一半一半的两部分,然后进行比较

分成红底进行比较,但是由于链表的特殊性,我们不能倒着比较。
所以就要对另一半进行逆序来比较
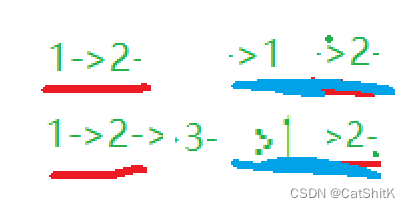
逆序后进行比较。
这样我们就可以用到我们之前题目的积累,正所谓功夫不负有心人,CV大法启动!
附上链接:
2. 反转一个单链表。
力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台
3. 给定一个带有头结点 head 的非空单链表,返回链表的中间结点。如果有两个中间结点,则返回第二个中间结点。
力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台
注意要点
- 中间节点要记录好,因为后续比较要用到
- 该如何判断比较的继续条件(任何一个为NULL就结束)
附源代码:
/*
struct ListNode {int val;struct ListNode *next;ListNode(int x) : val(x), next(NULL) {}
};*/
class PalindromeList {
public:struct ListNode* middleNode(struct ListNode* head) {struct ListNode* tail = head;while(tail->next){head=head->next;tail=tail->next;if(tail->next==NULL){//head=head->next;}elsetail=tail->next;}return head;}struct ListNode* reverseList(struct ListNode* head)
{struct ListNode* cur=head;struct ListNode* newhead = NULL;while(cur){struct ListNode* next=cur->next;cur->next = newhead; //指向新节点newhead = cur;cur = next;} return newhead;
}bool chkPalindrome(ListNode* A) {struct ListNode* mid = middleNode(A);struct ListNode* rev = reverseList(mid);while(A&&rev){if(A->val!=rev->val){return false;}A=A->next;rev=rev->next;}return true;
}
};
3. 输入两个链表,找出它们的第一个公共结点。
力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台
方法
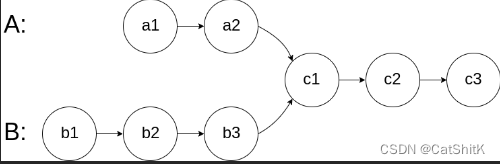
大家要注意相交的链表的意思是后面的节点会交汇,而不是交叉相交
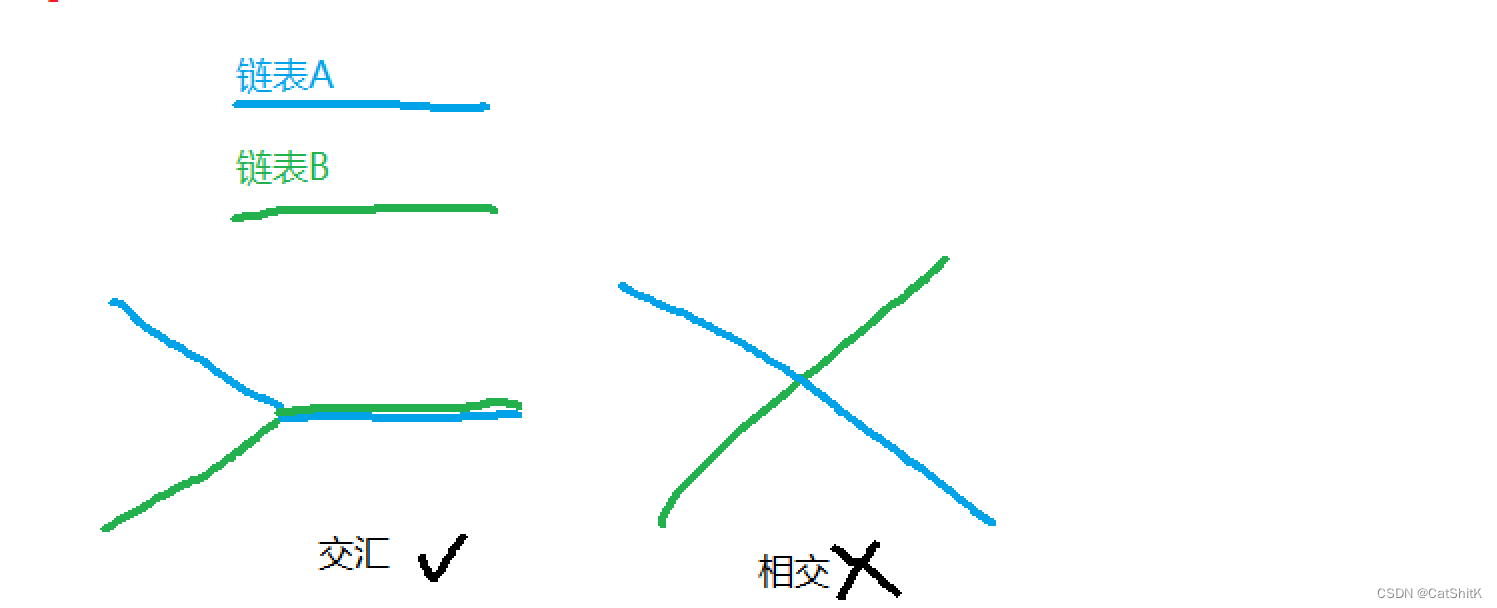
根据这种链表的特点,我们可以清楚他们的尾节点一定是相等的
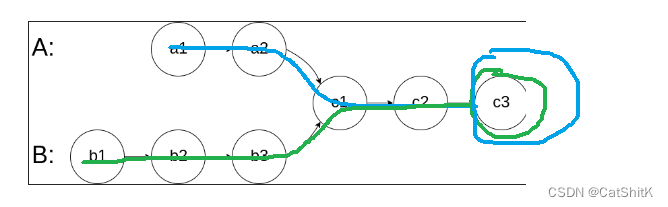
通过这点我们就可以对是否为此类的链表进行判断。
再者我们发现,如果是两个链表,按照“顺序”,第一个相等的就是相交节点
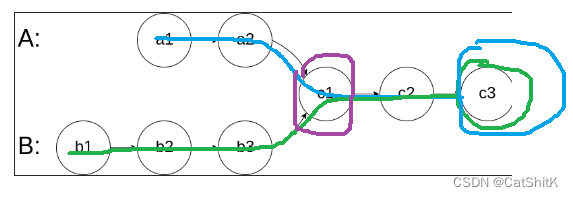
那么我们要怎么让两个节点的比较值相对整个表是一样的,因为有长短不一的表

如果从首节点开始相互比较,那他们永远都不会相等,所以我们要做到同步比较
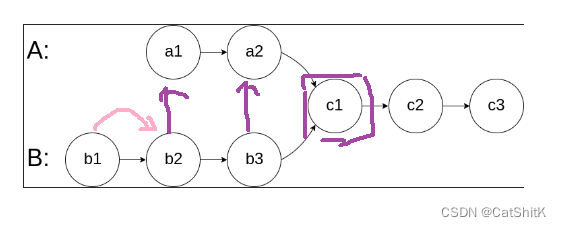
通过计算两表的长度,让较长的表提前向前走差值步,再进行比较,当第一次比较相等时,那就是相交节点!
注意要点
- 在遍历尾节点时,可以顺便计算链表长度
- 对于长表的定义,我们可以用指针替代,然后再用各自对应的长度比较,再进行长表指针的定义,这样就可以节省掉很多if else语句。
附源代码
/*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) {struct ListNode *curA=headA;struct ListNode *curB=headB;int lenA=1,lenB=1; //链表的长度至少为1while(curA->next) //计算链表A的长度及尾节点{lenA++; //顺便计算表长curA=curA->next;}while(curB->next){lenB++;curB=curB->next;}if(curA!=curB){return NULL; //两边的为节点不相同,那根本不是相交链表}int gap=abs(lenA-lenB); //abs为取绝对值struct ListNode *longlist=headA; //假设A为长节点,这里我们利用替身来表示长表struct ListNode *shortlist=headB; //就可以节省很多判断语句if(lenB>lenA) //若B长,侧替换{longlist=headB;shortlist=headA;}while(gap--){longlist=longlist->next; //先走差值步}while(longlist!=shortlist) //不等于则同时向前遍历,直到相等{longlist=longlist->next;shortlist=shortlist->next;}return longlist; //返回第一个相等值
}这篇关于【数据结构】链表OJ面试题2《分割小于x并排序链表、回文结构、相交链表》+解析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






