本文主要是介绍快速入门Flink (5) ——DataSet必知必会的16种Transformation操作(超详细!建议收藏!),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
写在前面: 博主是一名大数据的初学者,昵称来源于《爱丽丝梦游仙境》中的Alice和自己的昵称。作为一名互联网小白,
写博客一方面是为了记录自己的学习历程,一方面是希望能够帮助到很多和自己一样处于起步阶段的萌新。由于水平有限,博客中难免会有一些错误,有纰漏之处恳请各位大佬不吝赐教!个人小站:http://alices.ibilibili.xyz/ , 博客主页:https://alice.blog.csdn.net/
尽管当前水平可能不及各位大佬,但我还是希望自己能够做得更好,因为一天的生活就是一生的缩影。我希望在最美的年华,做最好的自己!
在上一篇博客中,我们已经学习了在Flink中批处理流程的一般步骤,以及常见的输入DataSource和输出DataSink的几种方式(传送门:👉Flink的DataSource和DataSink,你都掌握了吗?)。本篇博客,我们来学习关于DataSet的Transfromation,也就是类似于我们之前学习的SparkCore的转换算子。
前方高能预警!!!码字不易,先赞后看

文章目录
- 1.4 DataSet 的 Transformation
- 1.4.1 map
- 1.4.2 flatMap
- 1.4.3 mapPartition
- 1.4.4 filter 函数
- 1.4.5 reduce
- 1.4.6 reduceGroup
- 1.4.7 Aggregate
- 1.4.8 minBy 和 maxBy
- 1.4.9 distinct 去重
- 1.4.10 Join
- 1.4.11 LeftOuterJoin
- 1.4.12 RightOuterJoin
- 1.4.13 fullOuterJoin
- 1.4.14 cross 交叉操作
- 1.4.15 Union
- 1.4.16 Rebalance
- 小结
1.4 DataSet 的 Transformation
1.4.1 map
将DataSet中的每一个元素转换为另一个元素。
示例
使用 map 操作,将以下数据 “1,张三”, “2,李四”, “3,王五”, “4,赵六”,转换为一个 scala 的样例类。
步骤
1) 获取 ExecutionEnvironment 运行环境
2) 使用 fromCollection 构建数据源
3) 创建一个 User 样例类
4) 使用 map 操作执行转换
5) 打印测试
参考代码
import org.apache.flink.api.scala._
/** @Author: Alice菌* @Date: 2020/7/8 10:16* @Description: */
object BashMapDemo {// 创建样例类,用于封装数据case class user(id:Int,name:String)def main(args: Array[String]): Unit = {// 1、 创建执行环境val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment// 2、 构建数据集val sourceDataSet: DataSet[String] = env.fromElements("1,张三","2,李四","3,王五")// 3、 数据转换处理val userDataSet: DataSet[user] = sourceDataSet.map(item => {val itemsArr: Array[String] = item.split(",")user(itemsArr(0).toInt, itemsArr(1))})// 4、 打印结果userDataSet.print()//user(1,张三)//user(2,李四)//user(3,王五)}
}
1.4.2 flatMap
将 DataSet 中的每一个元素转换为 0…n 个元素。
示例
分别将以下数据,转换成 国家 、省份 、城市 三个维度的数据。
张三,中国,江西省,南昌市
李四,中国,河北省,石家庄市
Tom,America,NewYo
转换为
张三,中国
张三,中国江西省
张三,中国江西省南昌市
思路
以上数据为一条转换为三条,显然,应当使用 flatMap 来实现 。分别在 flatMap 函数中构建三个数据,并放入到一个列表中。
姓名, 国家
姓名, 国家省份
姓名, 国家省份城市
步骤
1) 构建批处理运行环境
2) 构建本地集合数据源
3) 使用 flatMap 将一条数据转换为三条数据
a. 使用逗号分隔字段
b. 分别构建国家、国家省份、国家省份城市三个元组
4) 打印输出
代码示例
import org.apache.flink.api.scala._import scala.collection.mutable
/** @Author: Alice菌* @Date: 2020/7/8 10:23* @Description: 1) 构建批处理运行环境2) 构建本地集合数据源3) 使用 flatMap 将一条数据转换为三条数据 a. 使用逗号分隔字段 b. 分别构建国家、国家省份、国家省份城市三个元组4) 打印输出*/
object BashFlatMapDemo {def main(args: Array[String]): Unit = {val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironmentval userDataSet: DataSet[String] = env.fromCollection(List("张三, 中国,江西省,南昌市","李四,中国,河北省,石家庄市", "Tom,America,NewYork,Manhattan"))val userAdressSetData: DataSet[(String, String)] = userDataSet.flatMap(item => {val field: mutable.ArrayOps[String] = item.split(",")List((field(0), field(1)),(field(0), field(1) + field(2)),(field(0), field(1) + field(2) + field(3)))})// 输出结果userAdressSetData.print()//(张三, 中国)//(张三, 中国江西省)//(张三, 中国江西省南昌市)//(李四,中国)//(李四,中国河北省)//(李四,中国河北省石家庄市)//(Tom,America)//(Tom,AmericaNewYork)//(Tom,AmericaNewYorkManhattan)}
}
1.4.3 mapPartition
将一个分区中的元素转换为另一个元素。
示例
使用 mapPartition 操作,将以下数据"1,张三", “2,李四”, “3,王五”, "4,赵六"转换为一个 scala 的样例类。
步骤
1) 获取 ExecutionEnvironment 运行环境
2) 使用 fromCollection 构建数据源
3) 创建一个 User 样例类
4) 使用 mapPartition 操作执行转换
5) 打印测试
参考代码
import org.apache.flink.api.scala._/** @Author: Alice菌* @Date: 2020/7/8 20:55* @Description: */object BatchMapPartitionDemo {case class user(id:Int,name:String)def main(args: Array[String]): Unit = {// 1、创建执行环境val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment// 2、构建数据集val sourceDataSet: DataSet[String] = env.fromElements("1,张三", "2,李四", "3,王五", "4,赵六")// 3、数据处理val userDataSet: DataSet[user] = sourceDataSet.mapPartition(itemPartition => {itemPartition.map(item => {val itemsArr: Array[String] = item.split(",")user(itemsArr(0).toInt, itemsArr(1))})})// 4、打印数据userDataSet.print()//user(1,张三)//user(2,李四)//user(3,王五)//user(4,赵六)}
}1.4.4 filter 函数
过滤出来一些符合条件的元素。
Filter 函数在实际生产中特别实用,数据处理阶段可以过滤掉大部分不符合业务的内容,可以极大减轻整体 flink 的运算压力。
示例:
过滤出来以下以 h 开头的单词。
“hadoop”, “hive”, “spark”, “flink”
步骤
1) 获取 ExecutionEnvironment 运行环境
2) 使用 fromCollection 构建数据源
3) 使用 filter 操作执行过滤
4) 打印测试
参考代码
import org.apache.flink.api.scala.ExecutionEnvironmentimport org.apache.flink.api.scala._
/** @Author: Alice菌* @Date: 2020/7/26 23:16* @Description: */
object BatchFilterDemo {def main(args: Array[String]): Unit = {val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironmentval testDataSet: DataSet[String] = env.fromElements("hadoop","hive","spark","flink")val filterDataSet: DataSet[String] = testDataSet.filter(x=>x.startsWith("h"))filterDataSet.print()//hadoop//hive}
}1.4.5 reduce
可以对一个 dataset 或者一个 group 来进行聚合计算,最终聚合成一个元素。
示例
请将以下元组数据,使用 reduce 操作聚合成一个最终结果(“java” , 1) , (“java”, 1) ,(“java” , 1) 将上传元素数据转换为 (“java”,3)
步骤
1) 获取 ExecutionEnvironment 运行环境
2) 使用 fromCollection 构建数据源
3) 使用 redice 执行聚合操作
4) 打印测试
参考代码
import org.apache.flink.api.scala._
/** @Author: Alice菌* @Date: 2020/7/26 23:20* @Description: */
object BatchReduceDemo {def main(args: Array[String]): Unit = {val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironmentval testDataSet: DataSet[(String, Int)] = env.fromCollection(List(("java" , 1),("java", 1),("java" , 1)))val groupedDataSet: GroupedDataSet[(String, Int)] = testDataSet.groupBy(0)val reduceDataSet: DataSet[(String, Int)] = groupedDataSet.reduce((v1,v2)=>(v1._1,v1._2+v2._2))reduceDataSet.print()// (java,3)}
}1.4.6 reduceGroup
可以对一个 dataset 或者一个 group 来进行聚合计算,最终聚合成一个元素。
reduce 和 reduceGroup 的 区别
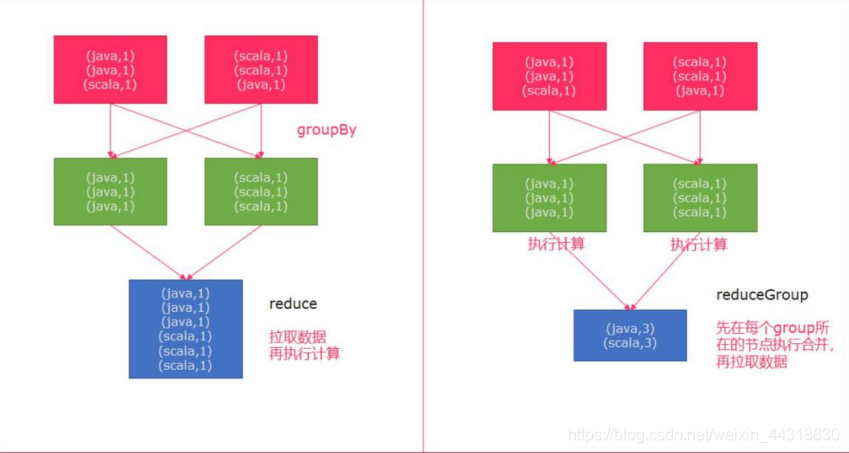
首先 groupBy 函数会将一个个的单词进行分组,分组后的数据被 reduce 一个个的拉 取过来,这种方式如果数据量大的情况下,拉取的数据会非常多,增加了网络 IO。
reduceGroup 是 reduce 的一种优化方案;
它会先分组 reduce,然后在做整体的 reduce;这样做的好处就是可以减少网络 IO;
示例
请将以下元组数据,下按照单词使用 groupBy 进行分组,再使用 reduceGroup 操作进行单词计数
(“java” , 1) , (“java”, 1) ,(“scala” , 1)
步骤
1) 获取 ExecutionEnvironment 运行环境
2) 使用 fromCollection 构建数据源
3) 使用 groupBy 按照单词进行分组
4) 使用 reduceGroup 对每个分组进行统计
5) 打印测试
参考代码
import org.apache.flink.api.scala._/** @Author: Alice菌* @Date: 2020/7/26 23:29* @Description: */
object BatchReduceGroupDemo {def main(args: Array[String]): Unit = {val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironmentval textDataSet: DataSet[(String, Int)] = env.fromCollection(List(("java" , 1),("java", 1),("scala" , 1)))val groupedDataSet: GroupedDataSet[(String, Int)] = textDataSet.groupBy(0)val reduceGroupDataSet: DataSet[(String, Int)] = groupedDataSet.reduceGroup(group => {group.reduce((v1, v2) => {(v1._1, v1._2 + v2._2)})})reduceGroupDataSet.print()//(java,2)//(scala,1)}
}1.4.7 Aggregate
按照内置的方式来进行聚合。例如:SUM/MIN/MAX…
示例
请将以下元组数据,使用 aggregate 操作进行单词统计。
(“java” , 1) , (“java”, 1) ,(“scala” , 1)
步骤
1) 获取 ExecutionEnvironment 运行环境
2) 使用 fromCollection 构建数据源
3) 使用 groupBy 按照单词进行分组
4) 使用 aggregate 对每个分组进行 SUM 统计
5) 打印测试
参考代码
注意:Aggregate 只能作用于元组上
import org.apache.flink.api.java.aggregation.Aggregations
import org.apache.flink.api.scala._
/** @Author: Alice菌* @Date: 2020/7/27 18:47* @Description: */
object BatchAggregateDemo {def main(args: Array[String]): Unit = {val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironmentval textDataSet: DataSet[(String, Int)] = env.fromCollection(List(("java",1),("java",1),("scala" , 1)))val grouped: GroupedDataSet[(String, Int)] = textDataSet.groupBy(0)val aggDataSet: AggregateDataSet[(String, Int)] = grouped.aggregate(Aggregations.SUM,1)aggDataSet.print()//(java,2)//(scala,1)}
}
1.4.8 minBy 和 maxBy
获取指定字段的最大值、最小值。
示例
请将以下元组数据,使用 aggregate 操作进行单词统计。
(1, “yuwen”, 89.0) , (2, “shuxue”, 92.2),(3, “yingyu”, 89.99),(4, “wuli”, 98.9),(1, “yuwen”, 88.88),(1, “wuli”, 93.00),(1, “yuwen”, 94.3)
步骤
1) 获取 ExecutionEnvironment 运行环境
2) 使用 fromCollection 构建数据源
3) 使用 groupBy 按照单词进行分组
4) 使用 maxBy、minBy对每个分组进行操作
5) 打印测试
参考代码
import org.apache.flink.api.java.aggregation.Aggregations
import org.apache.flink.api.scala.{DataSet, ExecutionEnvironment}
import scala.collection.mutable
import scala.util.Random
/** @Author: Alice菌* @Date: 2020/7/28 13:39* @Description: */
object BatchMinByAndMaxByDemo {def main(args: Array[String]): Unit = {val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironmentval data: mutable.MutableList[(Int, String, Double)] = new mutable.MutableList[(Int, String, Double)]data .+= ((1,"yuyan",89.0))data .+= ((2,"shuxue",92.2))data .+= ((3,"yiingyu",89.99))data .+= ((4,"wuli",98.9))data .+= ((5,"yuwen",88.88))data .+= ((1,"wuli",93.00))data .+= ((1,"yuyan",94.3))// 导入隐式转换import org.apache.flink.api.scala._// fromCollection 将数据转换成 DataSetval input: DataSet[(Int, String, Double)] = env.fromCollection(Random.shuffle(data))input.print()println("===========获取指定字段分组后,某个字段的最大值 ==================")val output: AggregateDataSet[(Int, String, Double)] = input.groupBy(1).aggregate(Aggregations.MAX,2)output.print()println("===========使用【MinBy】获取指定字段分组后,某个字段的最小值 ==================")val output2: DataSet[(Int, String, Double)] = input.groupBy(1)// 求每个学科下的最小分数// minBy的参数 代表 要求哪个字段的最小值.minBy(2)output2.print()println("===========使用【maxBy】获取指定字段分组后,某个字段的最大值 ==================")val output3: DataSet[(Int, String, Double)] = input.groupBy(1)// 求每个学科下的最大分数// maxBy的参数代表着要求哪个字段的最大值.maxBy(2)output3.print()}
}1.4.9 distinct 去重
distinct 去重。
示例
请将以下元组数据,使用distinct 操作去除重复的单词。
(“java” , 1) , (“java”, 1) ,(“scala” , 1)
去重得到
(“java”, 1), (“scala”, 1)
步骤
1) 获取 ExecutionEnvironment 运行环境
2) 使用 fromCollection 构建数据源
3) 使用 distinct 指定按照哪个字段来进行去重
4) 打印测试
参考代码
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.api.scala._/** @Author: Alice菌* @Date: 2020/7/28 13:58* @Description: */
object BatchDistinctDemo {def main(args: Array[String]): Unit = {val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironmentval textDataSet: DataSet[(String, Int)] = env.fromCollection(List(("java",1),("java",1),("scala",1)))textDataSet.distinct(0).print()//(java,1)//(scala,1)}
}
1.4.10 Join
使用 join 可以将两个 DataSet 连接起来。
示例:
有两个 csv 文件,有一个为 score.csv,一个为 subject.csv,分别保存了成绩数据以及学科数据。
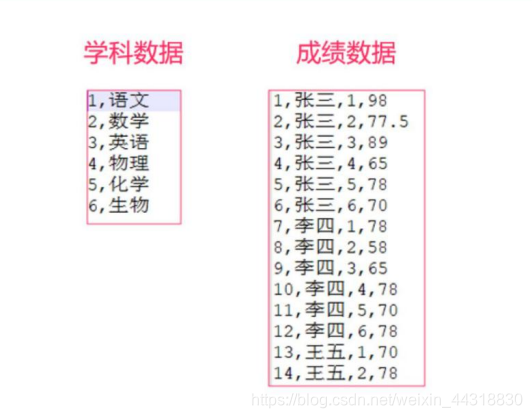
需要将这两个数据连接到一起,然后打印出来。
合并的规则如下:
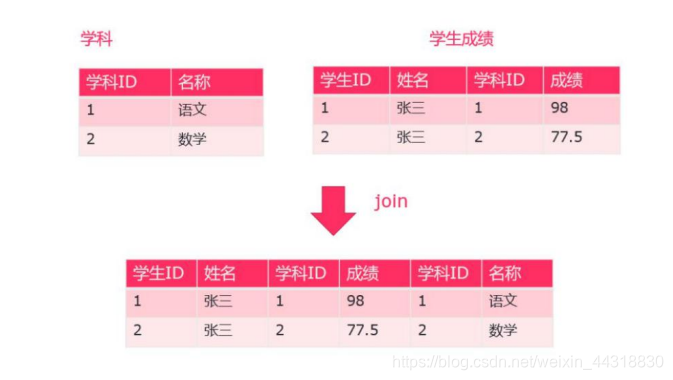
步骤
1) 分别将资料中的两个文件复制到项目中的 data/join/input 中
2) 构建批处理环境
3) 创建两个样例类
a. 学科 Subject(学科 ID、学科名字)
b. 成绩 Score(唯一 ID、学生姓名、学科 ID、分数——Double 类型)
4) 分别使用 readCsvFile 加载 csv 数据源,并制定泛型
5) 使用 join 连接两个 DataSet,并使用 where 、 equalTo 方法设置关联条件
6) 打印关联后的数据源
参考代码
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.api.scala._/** @Author: Alice菌* @Date: 2020/7/28 14:39* @Description: */
object BatchJoinDemo {case class Subject(id:Int,name:String)case class Score(id:Int,stuName:String,subId:Int,score:Double)def main(args: Array[String]): Unit = {val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironmentval subjectDataSet: DataSet[Score] = env.readCsvFile("E:\\2020大数据新学年\\BigData\\06-Flink\\课堂资料\\0708\\day02资料\\测试数据源\\score.csv")val scoreDataSet: DataSet[Subject] = env.readCsvFile("E:\\2020大数据新学年\\BigData\\06-Flink\\课堂资料\\0708\\day02资料\\测试数据源\\subject.csv")val joinDataSet: JoinDataSet[Score, Subject] = subjectDataSet.join(scoreDataSet).where(_.subId).equalTo(_.id)joinDataSet.print()//(Score(27,小七,3,78.0),Subject(3,英语))//(Score(15,王五,3,58.0),Subject(3,英语))//(Score(21,赵六,3,65.0),Subject(3,英语))//(Score(3,张三,3,89.0),Subject(3,英语))//(Score(9,李四,3,65.0),Subject(3,英语))//(Score(17,王五,5,78.0),Subject(5,化学))//(Score(29,小七,5,65.0),Subject(5,化学))//(Score(23,赵六,5,70.0),Subject(5,化学))//(Score(5,张三,5,78.0),Subject(5,化学))//(Score(11,李四,5,70.0),Subject(5,化学))//(Score(18,王五,6,98.0),Subject(6,生物))//(Score(30,小七,6,78.0),Subject(6,生物))//(Score(12,李四,6,78.0),Subject(6,生物))//(Score(24,赵六,6,78.0),Subject(6,生物))//(Score(6,张三,6,70.0),Subject(6,生物))//(Score(19,赵六,1,77.5),Subject(1,语文))//(Score(7,李四,1,78.0),Subject(1,语文))//(Score(13,王五,1,70.0),Subject(1,语文))//(Score(1,张三,1,98.0),Subject(1,语文))//(Score(25,小七,1,78.0),Subject(1,语文))//(Score(28,小七,4,58.0),Subject(4,物理))//(Score(16,王五,4,65.0),Subject(4,物理))//(Score(22,赵六,4,78.0),Subject(4,物理))//(Score(4,张三,4,65.0),Subject(4,物理))//(Score(10,李四,4,78.0),Subject(4,物理))//(Score(14,王五,2,78.0),Subject(2,数学))//(Score(20,赵六,2,89.0),Subject(2,数学))//(Score(8,李四,2,58.0),Subject(2,数学))//(Score(2,张三,2,77.5),Subject(2,数学))//(Score(26,小七,2,70.0),Subject(2,数学))}
}优化 join
通过给 Flink 一些提示,可以使得你的 join 更快,但是首先我们要简单了解一下 Flink 如何执行 join 的。
当 Flink 处理批量数据的时候,每台机器只是存储了集群的部分数据。为了执行 join, Flink 需要找到两个数据集的所有满足 join 条件的数据。为了实现这个目标,Flink 需要将两个数据集有相同 key 的数据发送到同一台机器上。
有两种策略:
1. repartition-repartition strategy
在该情况下,两个数据集都会使用 key 进行重分区并使用通过网络传输。这就意味着假如数据集太大的话,网络传输数据集将耗费大量的时间。
2. broadcast-forward strategy
在该情况下,一个数据集不动,另一个数据集会 copy 到有第一个数据集部分数据的所有机器上。如果使用小数据集与大数据集进行 join,可以选择 broadcast-forward 策略,将小 数据集广播, 避免代价高的重分区。
ds1.join(ds2, JoinHint.BROADCAST_HASH_FIRST)
第二个参数就是提示,第一个数据集比第二个小。
也可以使用下面几个提示:
BROADCAST_HASH_SECOND: 第二个数据集是较小的数据集
REPARTITION_HASH_FIRST:第一个数据集是较小的数据集
REPARTITION_HASH_SECOND:第二个数据集是较小的数据集
REPARTITION_SORT_MERGE:对数据集进行重分区,同时使用 sort 和 merge 策略。
OPTIMIZER_CHOOSES:(默认的)Flink的优化器决定两个数据集如何 join。
1.4.11 LeftOuterJoin
左外连接,左边的 Dataset 中的每一个元素,去连接右边的元素。
示例
请将以下元组数据(用户 id,用户姓名)
(1, “zhangsan”) , (2, “lisi”) ,(3 , “wangwu”) ,(4 , “zhaoliu”)
元组数据(用户 id,所在城市)
(1, “beijing”), (2, “shanghai”), (4, “guangzhou”)
返回如下数据:
(3,wangwu,null),(1,zhangsan,beijing) ,(2,lisi,shanghai) ,(4,zhaoliu,guangzhou)
参考代码
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.api.scala._import scala.collection.mutable.ListBuffer
/** @Author: Alice菌* @Date: 2020/7/28 14:58* @Description: 左外连接,左边的Dataset中的每一个元素,去连接右边的元素*/object BatchLeftOuterJoinDemo {def main(args: Array[String]): Unit = {val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironmentval data1: ListBuffer[(Int, String)] = ListBuffer[Tuple2[Int,String]]()data1.append((1,"zhangsan"))data1.append((2,"lisi"))data1.append((3,"wangwu"))data1.append((4,"zhaoliu"))val data2: ListBuffer[(Int, String)] = ListBuffer[Tuple2[Int,String]]()data2.append((1,"beijing"))data2.append((2,"shanghai"))data2.append((4,"guangzhou"))val text1: DataSet[(Int, String)] = env.fromCollection(data1)val text2: DataSet[(Int, String)] = env.fromCollection(data2)text1.leftOuterJoin(text2).where(0).equalTo(0).apply((first,second) =>{if (second == null){(first._1,first._2,"null")}else{(first._1,first._2,second._2)}}).print()//(3,wangwu,null)//(1,zhangsan,beijing)//(4,zhaoliu,guangzhou)//(2,lisi,shanghai)}
}1.4.12 RightOuterJoin
右外连接,右边的 Dataset 中的每一个元素,去连接左边的元素。
示例
请将以下元组数据(用户 id,用户姓名)
(1, “zhangsan”) , (2, “lisi”) ,(3 , “wangwu”) ,(4 , “zhaoliu”)
元组数据(用户 id,所在城市)
(1, “beijing”),(2, “shanghai”), (4, “guangzhou”)
返回如下数据:
(1,zhangsan,beijing)
(2,lisi,shanghai)
(4,zhaoliu,guangzhou)
参考代码
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.api.scala._import scala.collection.mutable.ListBuffer
/** @Author: Alice菌* @Date: 2020/7/28 18:15* @Description: */
object BatchRightOuterJoinDemo {def main(args: Array[String]): Unit = {val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironmentval data1: ListBuffer[(Int, String)] = ListBuffer[Tuple2[Int,String]]()data1.append((1,"zhangsan"))data1.append((2,"lisi"))data1.append((3,"wangwu"))data1.append((4,"zhaoliu"))val data2: ListBuffer[(Int, String)] = ListBuffer[Tuple2[Int,String]]()data2.append((1,"beijing"))data2.append((2,"shanghai"))data2.append((4,"guangzhou"))val text1: DataSet[(Int, String)] = env.fromCollection(data1)val text2: DataSet[(Int, String)] = env.fromCollection(data2)text1.rightOuterJoin(text2).where(0).equalTo(0).apply((first,second) =>{if (first == null){(first._1,first._2,"null")}else{(first._1,first._2,second._2)}}).print()//(1,zhangsan,beijing)//(4,zhaoliu,guangzhou)//(2,lisi,shanghai)}
}1.4.13 fullOuterJoin
全外连接,左右两边的元素,全部连接。
示例
请将以下元组数据(用户 id,用户姓名)
(1, “zhangsan”) , (2, “lisi”) ,(3 , “wangwu”) ,(4 , “zhaoliu”)
元组数据(用户 id,所在城市)
(1, “beijing”), (2, “shanghai”), (4, “guangzhou”)
返回如下数据:
(3,wangwu,null)
(1,zhangsan,beijing)
(2,lisi,shanghai)
(4,zhaoliu,guangzhou)
参考代码
import org.apache.flink.api.common.operators.base.JoinOperatorBase.JoinHint
import org.apache.flink.api.scala.{ExecutionEnvironment, _}
import scala.collection.mutable.ListBuffer/** @Author: Alice菌* @Date: 2020/7/28 19:07* @Description: */
object BatchFullOuterJoinDemo {def main(args: Array[String]): Unit = {val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironmentval data1: ListBuffer[(Int, String)] = ListBuffer[Tuple2[Int,String]]()data1.append((1,"zhangsan"))data1.append((2,"lisi"))data1.append((3,"wangwu"))data1.append((4,"zhaoliu"))val data2: ListBuffer[(Int, String)] = ListBuffer[Tuple2[Int,String]]()data2.append((1,"beijing"))data2.append((2,"shanghai"))data2.append((4,"guangzhou"))val text1: DataSet[(Int, String)] = env.fromCollection(data1)val text2: DataSet[(Int, String)] = env.fromCollection(data2)text1.fullOuterJoin(text2,JoinHint.REPARTITION_SORT_MERGE).where(0).equalTo(0).apply((first,second) =>{if (first == null){(second._1,"null",second._2)}else if (second == null){(first._1,first._2,"null")}else{(first._1,first._2,second._2)}}).print()//(3,wangwu,null)//(1,zhangsan,beijing)//(4,zhaoliu,guangzhou)//(2,lisi,shanghai)}
}1.4.14 cross 交叉操作
和 join 类似,但是这种交叉操作会产生笛卡尔积,在数据比较大的时候,是非常消耗内存的操作;
示例
3请将以下元组数据
(1, 4, 7), (2, 5, 8), (3, 6, 9)
元组数据
(10, 40, 70), (20, 50, 80), (30, 60, 90)
进行笛卡尔积,返回如下数据:
Buffer(((1,4,7),(10,40,70)), ((1,4,7),(20,50,80)), ((1,4,7),(30,60,90)), ((2,5,8),(10,40,70)), ((2,5,8),(20,50,80)), ((2,5,8),(30,60,90)), ((3,6,9),(10,40,70)), ((3,6,9),(20,50,80)), ((3,6,9),(30,60,90)))
参考代码
import org.apache.flink.api.scala.{DataSet, ExecutionEnvironment}
import org.apache.flink.api.scala._/** @Author: Alice菌* @Date: 2020/7/29 14:09* @Description: */
object BatchCrossDemo {def main(args: Array[String]): Unit = {val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironmentprintln("============cross1==================")cross1(env)println("============cross2==================")cross2(env)println("============cross3==================")cross3(env)println("============crossWithTiny==================")crossWithTiny1(env)println("============crossWithHuge==================")crossWithHuge1(env)}// 定义一个方法def cross1(benv:ExecutionEnvironment): Unit ={// 1、定义两个DataSetval coords1: DataSet[(Int, Int, Int)] = benv.fromElements((1,4,7),(2,5,8),(3,6,9))val coords2: DataSet[(Int, Int, Int)] = benv.fromElements((10,40,70),(20,50,80),(30,60,90))// 2、交叉两个DataSet[Coord]val result1: CrossDataSet[(Int, Int, Int), (Int, Int, Int)] = coords1.cross(coords2)// 3、显示结果println(result1.collect)}def cross2(benv:ExecutionEnvironment): Unit ={// 1、 定义case classcase class Coord(id:Int,x:Int,y:Int)// 2、 定义两个DataSet[Coord]val coords1: DataSet[Coord] = benv.fromElements(Coord(1,4,7),Coord(2,5,8),Coord(3,6,9))val coords2: DataSet[Coord] = benv.fromElements(Coord(10,40,70),Coord(20,50,80),Coord(30,60,90))// 3、 交叉两个DataSet[Coord]val result1: CrossDataSet[Coord, Coord] = coords1.cross(coords2)// 4、 显示结果println(result1.collect)}def cross3(benv:ExecutionEnvironment): Unit ={// 1、 定义case classcase class Coord(id:Int,x:Int,y:Int)// 2、 定义两个DataSet[Coord]val coords1: DataSet[Coord] = benv.fromElements(Coord(1,4,7),Coord(2,5,8),Coord(3,6,9))val coords2: DataSet[Coord] = benv.fromElements(Coord(1,4,7),Coord(2,5,8),Coord(3,6,9))// 3、定义两个DataSet[Coord]val r: DataSet[(Int, Int, Int)] = coords1.cross(coords2) { (c1, c2) => {val dist: Int = (c1.x + c2.x) + (c1.y + c2.y)(c1.id, c2.id, dist)}}// 4、显示结果println(r.collect)}def crossWithTiny1(benv: ExecutionEnvironment): Unit ={// 1、 定义case classcase class Coord(id:Int,x:Int,y:Int)// 2、 定义两个DataSet[Coord]val coords1: DataSet[Coord] = benv.fromElements(Coord(1,4,7),Coord(2,5,8),Coord(3,6,9))val coords2: DataSet[Coord] = benv.fromElements(Coord(10,40,70),Coord(20,50,80),Coord(30,60,90))// 3、交叉两个DataSet[Coord],暗示第二个输入较小// 拿第一个输入的每一个元素和第二个输入的每一个元素进行交叉操作。val result1: CrossDataSet[Coord, Coord] = coords1.crossWithTiny(coords2)// 4、显示结果println(result1.collect)}def crossWithHuge1(benv: ExecutionEnvironment): Unit = {// 1、 定义case classcase class Coord(id:Int,x:Int,y:Int)// 2、 定义两个DataSet[Coord]val coords1: DataSet[Coord] = benv.fromElements(Coord(1,4,7),Coord(2,5,8),Coord(3,6,9))val coords2: DataSet[Coord] = benv.fromElements(Coord(10,40,70),Coord(20,50,80),Coord(30,60,90))// 3、 交叉两个Dataset[Coord],暗示第二个输入较大val result1: CrossDataSet[Coord, Coord] = coords1.crossWithHuge(coords2)// 4、 显示结果println(result1.collect)}
}1.4.15 Union
将多个 DataSet 合并成一个 DataSet。
【注意】:union 合并的 DataSet 的类型必须是一致的。
示例
将以下数据进行取并集操作。
数据集 1
“hadoop”, “hive”, “flume”
数据集 2
“hadoop”, “hive”, “spark”
步骤
1)构建批处理运行环境
2)使用 fromCollection 创建两个数据源
3)使用 union 将两个数据源关联在一起
4)打印测试
参考代码
import org.apache.flink.api.scala._/** @Author: Alice菌* @Date: 2020/7/29 15:42* @Description: */
object BatchUnionDemo {def main(args: Array[String]): Unit = {val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment// 使用 fromCollection 创建两个数据源val wordDataSet1: DataSet[String] = env.fromCollection(List("hadoop","hive","flume"))val wordDataSet2: DataSet[String] = env.fromCollection(List("hadoop","hive","spark"))val wordDataSet3: DataSet[String] = env.fromElements("hadoop")val wordDataSet4: DataSet[String] = env.fromElements("hadoop")wordDataSet1.union(wordDataSet2).print()println("- - - - - - - - - - - - - - - - - - - - - - - - -")wordDataSet3.union(wordDataSet4).print()//hadoop//hadoop//hive//hive//flume//spark//- - - - - - - - - - - - - - - - - - - - - - - - -//hadoop//hadoop}
}1.4.16 Rebalance
Flink 也有数据倾斜的时候,比如当前有数据量大概 10 亿条数据需要处理,在处理过程中可能会发生如图所示的状况:

这个时候本来总体数据量只需要 10 分钟解决的问题,出现了数据倾斜,机器 1 上的 任务需要4个小时才能完成,那么其他 3 台机器执行完毕也要等待机器 1 执行完毕后才算整体将任务完成;所以在实际的工作中,出现这种情况比较好的解决方案就是下边要讲解的—rebalance(内部使用 round robin 方法将数据均匀打散。这对于数据倾斜时是很好的选择。)
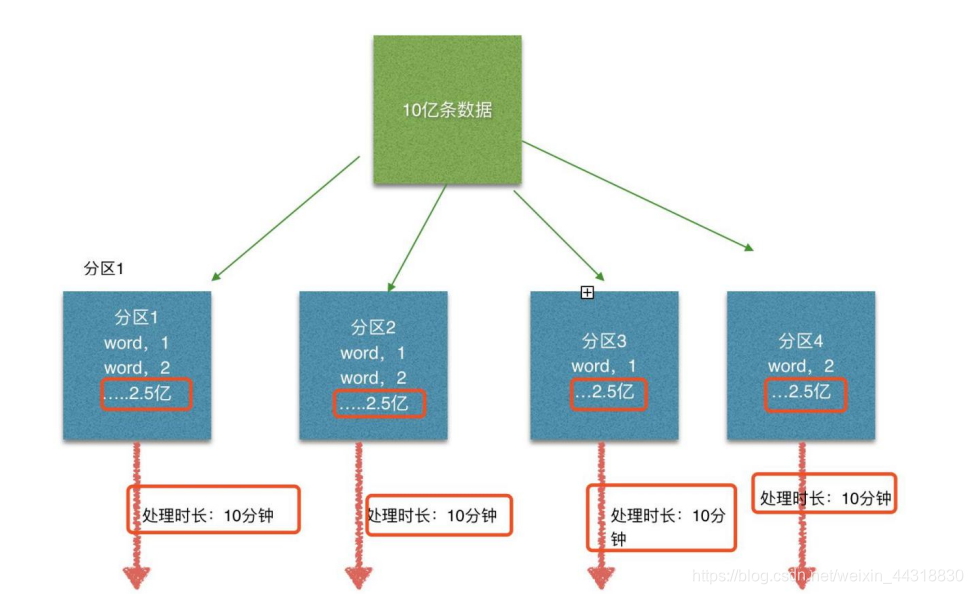
步骤
1)构建批处理运行环境
2)使用 env.generateSequence 创建 0-100 的并行数据
3)使用 fiter 过滤出来 大于 8 的数字
4)使用 map 操作传入 RichMapFunction ,将当前子任务的 ID 和数字构建成一个元组
5)在 RichMapFunction 中可以使用 getRuntimeContext.getIndexOfThisSubtask 获取子任务序号
6)打印测试
举例:
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.api.scala._
/** @Author: Alice菌* @Date: 2020/7/8 21:00* @Description: */object BatchRebalanceDemo {def main(args: Array[String]): Unit = {// 1、构建批处理运行环境val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment// 2、使用 env.generateSequence 创建 0 - 100 的并行数据val source: DataSet[Long] = env.generateSequence(0,100)// 3、 使用 filter 过滤出来 大于 8 的数字val filter: DataSet[Long] = source.filter(_>8)// 使用 rebalance 进行处理数据【防止数据倾斜】val rebalance: DataSet[Long] = filter.rebalance()// 4、使用 map 操作传入 RichMapFunction , 将当前子任务的 ID 和数字构建成一个元组val result: DataSet[(Int, Long)] = rebalance.map(new RichMapFunction[Long, (Int, Long)] {override def map(value: Long): (Int, Long) = {(getRuntimeContext.getIndexOfThisSubtask,value)}})result.print()// 结果跟核数有关}
}小结
本篇博客,博主为大家介绍并展示了Flink之DataSet常见的16种Transformation算子操作。当然还有很多算子,因为文章篇幅受限,没能在这里一一展示。有心的朋友们可以收藏了,把博客中所罗列的这16种算子熟悉了,对于Flink会有更深的理解!下一篇博客,菌哥将为大家带来的是Flink的广播变量,分布式缓存,累加器等知识,敬请期待!!!
如果以上过程中出现了任何的纰漏错误,烦请大佬们指正😅
受益的朋友或对大数据技术感兴趣的伙伴记得点赞关注支持一波🙏
希望我们都能在学习的道路上越走越远😉

这篇关于快速入门Flink (5) ——DataSet必知必会的16种Transformation操作(超详细!建议收藏!)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







