本文主要是介绍商汤科技一面,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1介绍一下你的项目吧
2后端语言你用什么??
3hr说你的csdn好像还不错?
4说一下你项目的增删改查,你通常都是什么思路去做项目的呢?
5数据库设计表结构,你怎么优化的,后期数据维护这你怎么做的?如果数据量很大的话你怎么优化呢?
【数据量大如何处理】
首先明确一点,真实情况不会存海量数据到mysql的,知道吗,大数据nosql---mongodb啊,hbase啊,
如果说的就是那种”大“数据(大相对于mysql来讲的话),那就是考虑一下几种方法
优化顺序
第一,优化你的sql和索引;
想实现一个查询,可以写出很多种查询语句,不同的语句,根据你选择的引擎、表中数据的分布情况、索引情况、数据库优化策略、查询中的锁策略等因素,最终查询的效率相差很大;优化要从整体去考虑,有时你优化一条语句后,其它查询反而效率被降低了,所以要取一个平衡点。
第二,加缓存,memcached,redis,es;
es【在mysql io的限制下以及redis内存的限制下,出来的es】
https://blog.csdn.net/aisemi/article/details/80212836
实际项目开发中,几乎每个系统都会有一个搜索的功能,数据量少时可以直接从主数据库中比如Mysql搜索,但当搜索做到一定程度时,比如系统数据量上了10亿、100亿条的时候,传统的关系型数据库的I/O性能和统计分析性能就难以满足用户需要了。所以很多公司都会把搜索单独做成一个独立的模块,用ElasticSearch等来实现。虽然内存缓存数据库的读写性能很高,但完全把数据放在内存中是不太现实的,比如到PB级别的数据,按照每个节点96G内存计算,在内存完全装满的数据情况下,需要的机器是:1PB=1024T=1048576G ,节点数就是1048576/96=10922个 ,再考虑到数据备份,节点数还需要翻倍,成本巨大决定了其不现实!
第三,主从复制或主主复制,读写分离;
第四 ,先删,在汇总(这是面试官给出的idea)
第五,分库分表,我认为就是数据库服务器集群
【优化表结构】
很多人都将 数据库设计范式 作为数据库表结构设计“圣经”,认为只要按照这个范式需求设计,就能让设计出来的表结构足够优化,既能保证性能优异同时还能满足扩展性要求。殊不知,在N年前被奉为“圣经”的数据库设计3范式早就已经不完全适用了。这里我整理了一些比较常见的数据库表结构设计方面的优化技巧,希望对大家有用。
由于MySQL数据库是基于行(Row)存储的数据库,而数据库操作 IO 的时候是以 page(block)的方式,也就是说,如果我们每条记录所占用的空间量减小,就会使每个page中可存放的数据行数增大,那么每次 IO 可访问的行数也就增多了。反过来说,处理相同行数的数据,需要访问的 page 就会减少,也就是 IO 操作次数降低,直接提升性能。此外,由于我们的内存是有限的,增加每个page中存放的数据行数,就等于增加每个内存块的缓存数据量,同时还会提升内存换中数据命中的几率,也就是缓存命中率。
数据类型选择
数据库操作中最为耗时的操作就是 IO 处理,大部分数据库操作 90% 以上的时间都花在了 IO 读写上面。所以尽可能减少 IO 读写量,可以在很大程度上提高数据库操作的性能。
我们无法改变数据库中需要存储的数据,但是我们可以在这些数据的存储方式方面花一些心思。下面的这些关于字段类型的优化建议主要适用于记录条数较多,数据量较大的场景,因为精细化的数据类型设置可能带来维护成本的提高,过度优化也可能会带来其他的问题:
数字类型:非万不得已不要使用DOUBLE,不仅仅只是存储长度的问题,同时还会存在精确性的问题。同样,固定精度的小数,也不建议使用DECIMAL,建议乘以固定倍数转换成整数存储,可以大大节省存储空间,且不会带来任何附加维护成本。对于整数的存储,在数据量较大的情况下,建议区分开 TINYINT / INT / BIGINT 的选择,因为三者所占用的存储空间也有很大的差别,能确定不会使用负数的字段,建议添加unsigned定义。当然,如果数据量较小的数据库,也可以不用严格区分三个整数类型。
字符类型:非万不得已不要使用 TEXT 数据类型,其处理方式决定了他的性能要低于char或者是varchar类型的处理。定长字段,建议使用 CHAR 类型,不定长字段尽量使用 VARCHAR,且仅仅设定适当的最大长度,而不是非常随意的给一个很大的最大长度限定,因为不同的长度范围,MySQL也会有不一样的存储处理。
时间类型:尽量使用TIMESTAMP类型,因为其存储空间只需要 DATETIME 类型的一半。对于只需要精确到某一天的数据类型,建议使用DATE类型,因为他的存储空间只需要3个字节,比TIMESTAMP还少。不建议通过INT类型类存储一个unix timestamp 的值,因为这太不直观,会给维护带来不必要的麻烦,同时还不会带来任何好处。
ENUM & SET:对于状态字段,可以尝试使用 ENUM 来存放,因为可以极大的降低存储空间,而且即使需要增加新的类型,只要增加于末尾,修改结构也不需要重建表数据。如果是存放可预先定义的属性数据呢?可以尝试使用SET类型,即使存在多种属性,同样可以游刃有余,同时还可以节省不小的存储空间。
LOB类型:强烈反对在数据库中存放 LOB 类型数据,虽然数据库提供了这样的功能,但这不是他所擅长的,我们更应该让合适的工具做他擅长的事情,才能将其发挥到极致。在数据库中存储 LOB 数据就像让一个多年前在学校学过一点Java的营销专业人员来写 Java 代码一样。
字符编码
字符集直接决定了数据在MySQL中的存储编码方式,由于同样的内容使用不同字符集表示所占用的空间大小会有较大的差异,所以通过使用合适的字符集,可以帮助我们尽可能减少数据量,进而减少IO操作次数。
纯拉丁字符能表示的内容,没必要选择 latin1 之外的其他字符编码,因为这会节省大量的存储空间
如果我们可以确定不需要存放多种语言,就没必要非得使用UTF8或者其他UNICODE字符类型,这回造成大量的存储空间浪费
MySQL的数据类型可以精确到字段,所以当我们需要大型数据库中存放多字节数据的时候,可以通过对不同表不同字段使用不同的数据类型来较大程度减小数据存储量,进而降低 IO 操作次数并提高缓存命中率
适当拆分
有些时候,我们可能会希望将一个完整的对象对应于一张数据库表,这对于应用程序开发来说是很有好的,但是有些时候可能会在性能上带来较大的问题。
当我们的表中存在类似于 TEXT 或者是很大的 VARCHAR类型的大字段的时候,如果我们大部分访问这张表的时候都不需要这个字段,我们就该义无反顾的将其拆分到另外的独立表中,以减少常用数据所占用的存储空间。这样做的一个明显好处就是每个数据块中可以存储的数据条数可以大大增加,既减少物理 IO 次数,也能大大提高内存中的缓存命中率。
上面几点的优化都是为了减少每条记录的存储空间大小,让每个数据库中能够存储更多的记录条数,以达到减少 IO 操作次数,提高缓存命中率。下面这个优化建议可能很多开发人员都会觉得不太理解,因为这是典型的反范式设计,而且也和上面的几点优化建议的目标相违背。
适度冗余
为什么我们要冗余?这不是增加了每条数据的大小,减少了每个数据块可存放记录条数吗?
确实,这样做是会增大每条记录的大小,降低每条记录中可存放数据的条数,但是在有些场景下我们仍然还是不得不这样做:
被频繁引用且只能通过 Join 2张(或者更多)大表的方式才能得到的独立小字段
这样的场景由于每次Join仅仅只是为了取得某个小字段的值,Join到的记录又大,会造成大量不必要的 IO,完全可以通过空间换取时间的方式来优化。不过,冗余的同时需要确保数据的一致性不会遭到破坏,确保更新的同时冗余字段也被更新
尽量使用 NOT NULL
NULL 类型比较特殊,SQL 难优化。虽然 MySQL NULL类型和 Oracle 的NULL 有差异,会进入索引中,但如果是一个组合索引,那么这个NULL 类型的字段会极大影响整个索引的效率。此外,NULL 在索引中的处理也是特殊的,也会占用额外的存放空间。
很多人觉得 NULL 会节省一些空间,所以尽量让NULL来达到节省IO的目的,但是大部分时候这会适得其反,虽然空间上可能确实有一定节省,倒是带来了很多其他的优化问题,不但没有将IO量省下来,反而加大了SQL的IO量。所以尽量确保 DEFAULT 值不是 NULL,也是一个很好的表结构设计优化习惯。
6协程,线程,进程的理解吧,c10k?高并发?
面试官和我讲他们那里,主要是用python和go一般都使用的是协程,协程是比线程开销更小的单位,我心里默默想,怪不得py/go那么快呢
【什么是进程和线程】
进程是什么呢?
直白地讲,进程就是应用程序的启动实例。比如我们运行一个游戏,打开一个软件,就是开启了一个进程。
进程拥有代码和打开的文件资源、数据资源、独立的内存空间。
线程又是什么呢?
线程从属于进程,是程序的实际执行者。一个进程至少包含一个主线程,也可以有更多的子线程。
线程拥有自己的栈空间。
有人给出了很好的归纳:
对操作系统来说,线程是最小的执行单元,进程是最小的资源管理单元。
什么是协程
协程,英文Coroutines,是一种比线程更加轻量级的存在。正如一个进程可以拥有多个线程一样,一个线程也可以拥有多个协程。
最重要的是,协程不是被操作系统内核所管理,而完全是由程序所控制(也就是在用户态执行)。
这样带来的好处就是性能得到了很大的提升,不会像线程切换那样消耗资源。
既然协程这么好,它到底是怎么来使用的呢?
由于Java的原生语法中并没有实现协程(某些开源框架实现了协程,但是很少被使用),所以我们来看一看python当中对协程的实现案例,同样以生产者消费者模式为例:
这段代码十分简单,即使没用过python的小伙伴应该也能基本看懂。
代码中创建了一个叫做consumer的协程,并且在主线程中生产数据,协程中消费数据。
其中 yield 是python当中的语法。当协程执行到yield关键字时,会暂停在那一行,等到主线程调用send方法发送了数据,协程才会接到数据继续执行。
但是,yield让协程暂停,和线程的阻塞是有本质区别的。协程的暂停完全由程序控制,线程的阻塞状态是由操作系统内核来进行切换。
因此,协程的开销远远小于线程的开销。
协程的应用
有哪些编程语言应用到了协程呢?我们举几个栗子:
Lua语言
Lua从5.0版本开始使用协程,通过扩展库coroutine来实现。
Python语言
正如刚才所写的代码示例,python可以通过 yield/send 的方式实现协程。在python 3.5以后,async/await 成为了更好的替代方案。
Go语言
Go语言对协程的实现非常强大而简洁,可以轻松创建成百上千个协程并发执行。
Java语言
如上文所说,Java语言并没有对协程的原生支持,但是某些开源框架模拟出了协程的功能,有兴趣的小伙伴可以看一看Kilim框架的源码:
7项目上线你干的?那你说下反向代理吧,负载均衡的策略你说下吧,面试官主要想看我有没有真的用过?
给你两个vue项目,nginx怎么配置静态文件,你一般配置的是servers还是appilcation
【配置静态文件】
在 Nginx 启动后,会有一个 master 进程和多个 worker 进程。master 进程主要用来管理 worker 进程,包含:接收来自外界的信号,向各 worker 进程发送信号,监控 worker 进程的运行状态,当 worker 进程退出后(异常情况下),会自动重新启动新的 worker 进程。而基本的网络事件,则是放在 worker 进程中来处理的。多个 worker 进程之间是对等的,他们同等竞争来自客户端的请求,各进程互相之间是独立的。一个请求,只可能在一个 worker 进程中处理,一个 worker 进程,不可能处理其它进程的请求。worker 进程的个数是可以设置的,一般我们会设置与机器 cpu 核数一致,这与 Nginx 的进程模型以及事件处理模型有关。
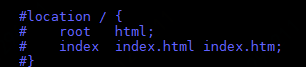
配置一下root就好了。。。。。。。。。。。小哥哥问那要是两个静态目录呢?
那就把所有的项目都放在html目录下,然后配上项目名访问呗,然后旺哥给出的解法是在配置一个location,改下访问路径和静态文件目录。。。。。。
/p1
/p2

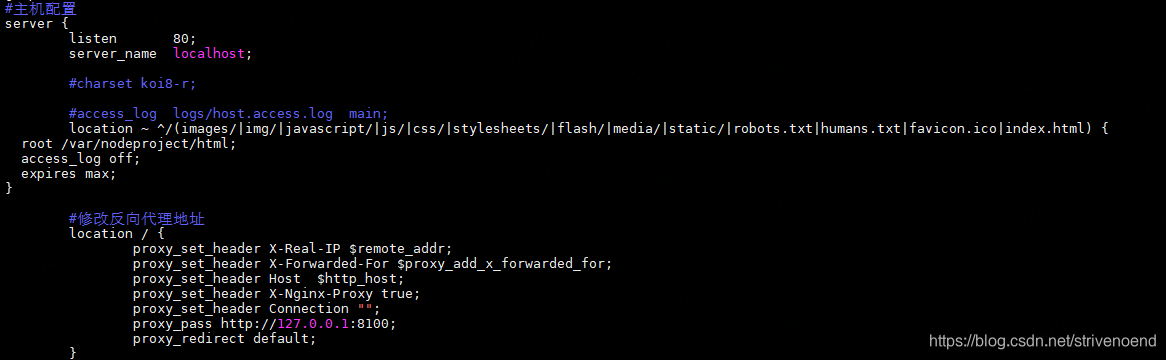
【负载均衡策略->随机+轮询+权重+最少连接+ip&hash)
NO.1—— Random 随机
这是最简单的一种,使用随机数来决定转发到哪台机器上。
优点:简单使用,不需要额外的配置和算法。
缺点:随机数的特点是在数据量大到一定量时才能保证均衡,所以如果请求量有限的话,可能会达不到均衡负载的要求。
NO.2—— Round Robin 轮询
这个也很简单,请求到达后,依次转发,不偏不向。每个服务器的请求数量很平均。
缺点:当集群中服务器硬件配置不同、性能差别大时,无法区别对待。引出下面的算法。
NO.3—— Weighted Round Robin 加权轮询
这种算法的出现就是为了解决简单轮询策略中的不足。在实际项目中,经常会遇到这样的情况。
比如有5台机器,两台新买入的性能等各方面都特别好,剩下三台老古董。这时候我们设置一个权重,让新机器接收更多的请求。物尽其用、能者多劳嘛!
这种情况下,“均衡“就比较相对了,也没必要做到百分百的平均。
NO.4—— Least Connections 最少连接
这是最符合负载均衡算法的一个。需要记录每个应用服务器正在处理的连接数,然后将新来的请求转发到最少的那台上。
NO.5—— Source Hashing 源地址散列
根据请求的来源ip进行hash计算,然后对应到一个服务器上。之后所有来自这个ip的请求都由同一台服务器处理
8消息队列用过嘛mq,c10k,高并发?
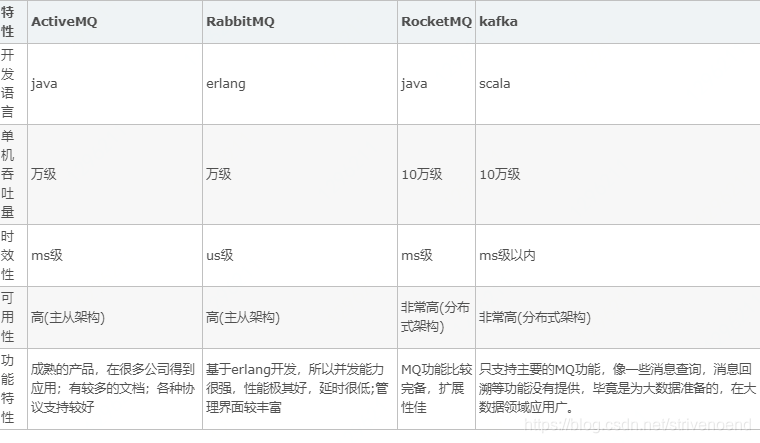
我们可以把消息队列比作是一个存放消息的容器,当我们需要使用消息的时候可以取出消息供自己使用。消息队列是分布式系统中重要的组件,使用消息队列主要是为了通过异步处理提高系统性能和削峰、降低系统耦合性。目前使用较多的消息队列有ActiveMQ,RabbitMQ,Kafka,RocketMQ,我们后面会一一对比这些消息队列。
消息通道通常以队列的形式存在,这种先进先出的数据结构无疑最为适合这种处理消息的场景。微软的MSMQ、IBM MQ、JBoss MQ以及开源的RabbitMQ、Apache ActiveMQ都通过队列实现了Message Channel模式。
就是一异步,防止大量数据同时对mysql造成的冲击,异步入库。。。。。。服务稳定解决方案=异步+负载均衡
削峰
传统模式
传统模式的缺点:
- 并发量大的时候,所有的请求直接怼到数据库,造成数据库连接异常
中间件模式:
中间件模式的的优点:
- 系统A慢慢的按照数据库能处理的并发量,从消息队列中慢慢拉取消息。在生产中,这个短暂的高峰期积压是允许的。
(1) 通过异步处理提高系统性能(削峰、减少响应所需时间)
通过异步处理提高系统性能
如上图,在不使用消息队列服务器的时候,用户的请求数据直接写入数据库,在高并发的情况下数据库压力剧增,使得响应速度变慢。但是在使用消息队列之后,用户的请求数据发送给消息队列之后立即 返回,再由消息队列的消费者进程从消息队列中获取数据,异步写入数据库。由于消息队列服务器处理速度快于数据库(消息队列也比数据库有更好的伸缩性),因此响应速度得到大幅改善。
通过以上分析我们可以得出消息队列具有很好的削峰作用的功能——即通过异步处理,将短时间高并发产生的事务消息存储在消息队列中,从而削平高峰期的并发事务。 举例:在电子商务一些秒杀、促销活动中,合理使用消息队列可以有效抵御促销活动刚开始大量订单涌入对系统的冲击。如下图所示:
合理使用消息队列可以有效抵御促销活动刚开始大量订单涌入对系统的冲击
因为用户请求数据写入消息队列之后就立即返回给用户了,但是请求数据在后续的业务校验、写数据库等操作中可能失败。因此使用消息队列进行异步处理之后,需要适当修改业务流程进行配合,比如用户在提交订单之后,订单数据写入消息队列,不能立即返回用户订单提交成功,需要在消息队列的订单消费者进程真正处理完该订单之后,甚至出库后,再通过电子邮件或短信通知用户订单成功,以免交易纠纷。这就类似我们平时手机订火车票和电影票。
9有什么想问我的么?
server挂了,内存不同步怎么办?面试官说再来一个监控?最好用已经成熟的框架稳定些。。。。
这篇关于商汤科技一面的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!