本文主要是介绍Exploring Deep Anomaly Detection Methods Based on Capsule Net论文阅读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
探索基于胶囊网的深度局部异常检测方法
abstract
文章中开发和探索了基于CapsNet的图像深度异常检测技术。由于CapsNet能够编码局部和整体之间的内在空间关系,因此它既可以被用作分类器,又可以用作深度自编码器。这启发我们设计一个基于预测概率和基于重构错误的正态性评分函数来评估未见图像的离群度。在三个数据集上结果表明,基于预测概率的方法性能同样很好,而基于重构错误的方法对带标记图像和未带标记图像的相似度相对敏感。另外,这两种基于CapsNet的方法在很多情况下都比原有的基准测试方法更好。
introduction
学习变换在计算机视觉领域是一个困难的任务。卷积神经网络是卷积操作的一种层次结构,作为一种高效的图像分类技术已被广泛应用。它有一个限制,神经元不能充分捕捉实体的属性,如位置、方向、大小以及它们的部分整体关系。CapsNet在保持这些信息方面具有一定的优势。实验证明,CapsNet能够保持图像特征之间的层次位姿(位置、大小和方向)关系,对于给定的图像,CapsNet使用一种迭代的协议路由机制,可以自动动态的对仿射变换和部分整体关系建模。
得益于CapsNet的这种特性,作者进行了后续研究。主要贡献有以下几点
- 基于CapsNet的特点,提出了两个良好的正态性评分函数,这是CapsNet进行异常检测的第一次尝试
- 将现有的异常检测思路分为基于边界的和基于分布的两类,为今后的研究奠定基础
- 将我们的方法与原则性的基准方法进行对比,并评估了它们检测深度异常的能力
CapsNet-Based Normality Score Functions
两种正太评分函数都是用来判断异常程度的。
基于预测概率正态性评分函数
数字胶囊在CapsNet的最后一层的激活概率表示输入样本属于类的概率。然而与softmax不同,所有数字胶囊的激活概率之和不一定为1.假设网络训练的足够好,对于一个正态测试图像应该有且只有一个接近1的概率,表示该图像属于其真类的可能性。
然而当网络无法解释异常样本时,数字胶囊的所有激活概率都很低。这个特征启发我们基于预测概率定义正态性评分函数。
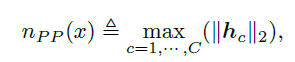
基于重建误差的正态性评分函数
在CapsNet中,重构误差通过解码器组件作为正则化术语使用,分类器也是一个用于解纠缠表示学习的编码器。在这个函数中,使用归一化平方误差(NSE)来衡量重建的质量。使用NSE而不是MSE的原因是不同图像中的不同对象在纯背景下会有不同数量的非零像素。使用MSE可以明显的减弱输入图像和重建图像之间的实际差值。例如图像1比图像8所占用的像素少很多,使用MSE图像1的重构损失比图像8的减少程度要大
这篇关于Exploring Deep Anomaly Detection Methods Based on Capsule Net论文阅读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




