本文主要是介绍法国亚马逊商品采集Python爬虫,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
看着身边做亚马逊铺货的朋友,花大时间收集商品信息,学着写个脚本帮忙解决下问题。他们日常主要是抓取商品价格,商品图片,商品介绍等。
商品图片应该是最难获取的到的。可以在js里可以获取到完整的商品大图
这个文章主要参考二爷记博客的文章:https://blog.csdn.net/minge89/article/details/106417047/
1、商品标题的获取
其实直接取title应该更简单,我这里是取得页面内容的标题。
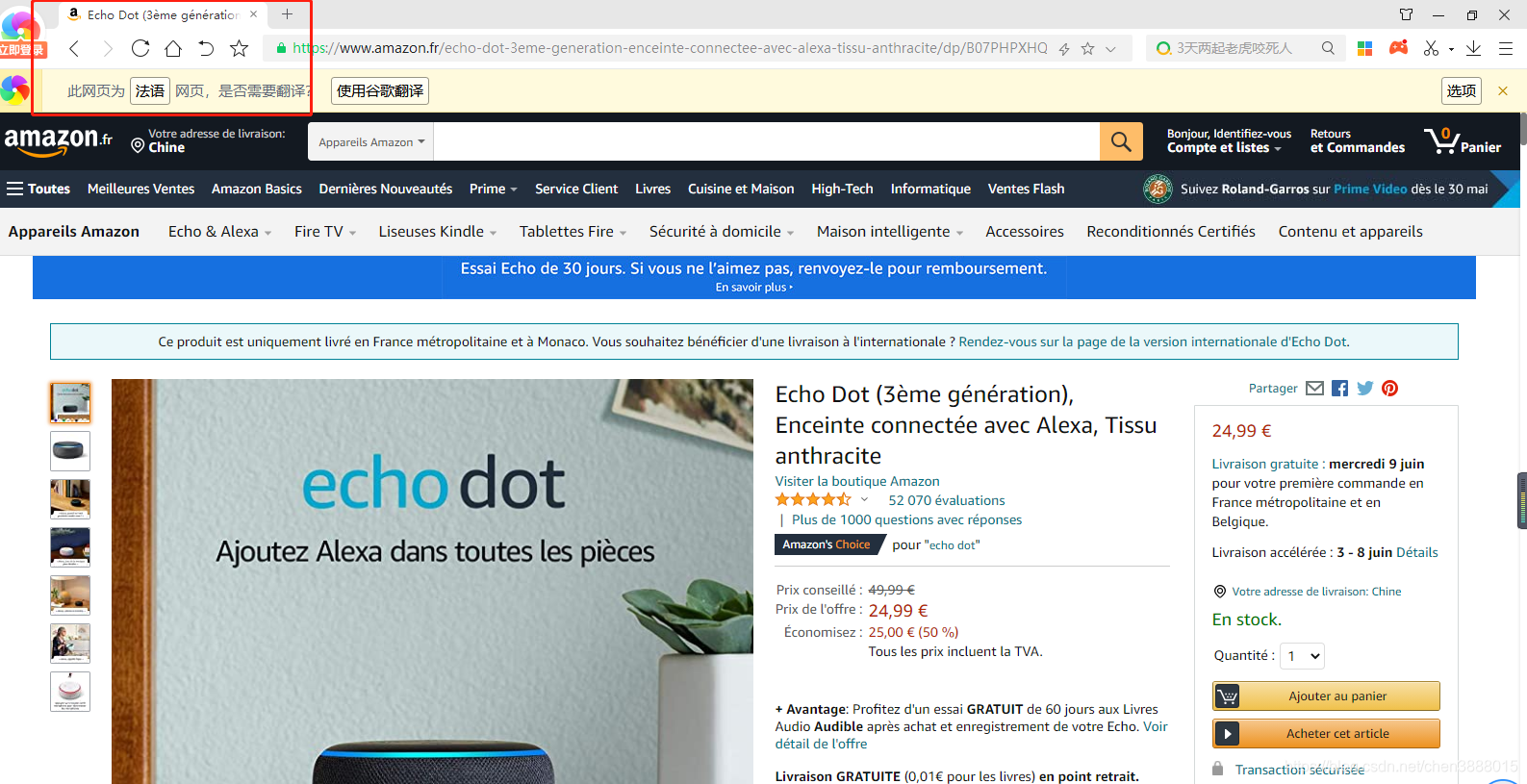

亚马逊商品页面html标题代码:<title>Echo Dot (3ème génération), Enceinte connectée avec Alexa, Tissu anthracite: Amazon.fr</title>
商品标题的获取:req.xpath('//h1[@id="title"]/span[@id="productTitle"]/text()')
2、商品属性的获取
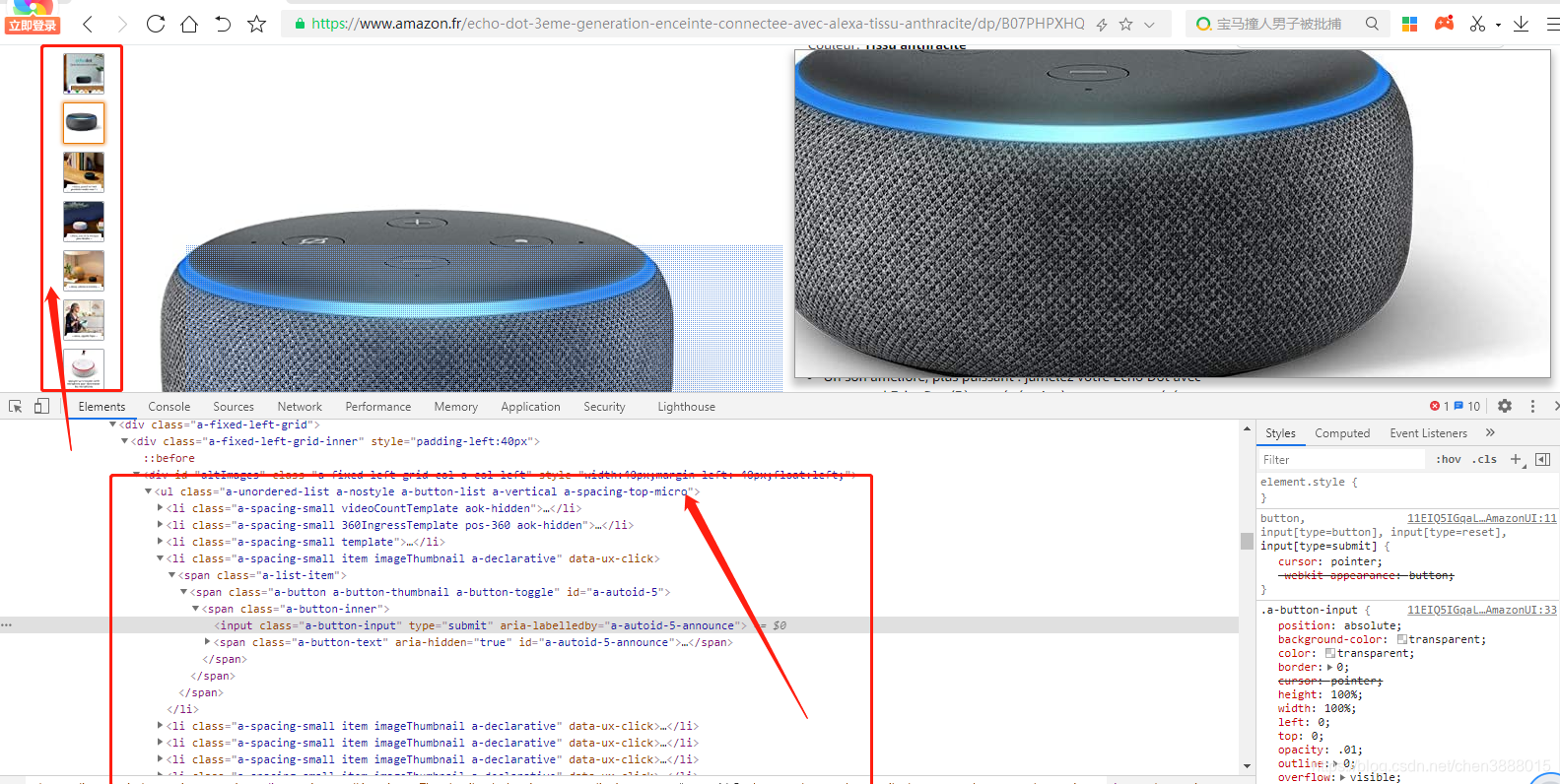
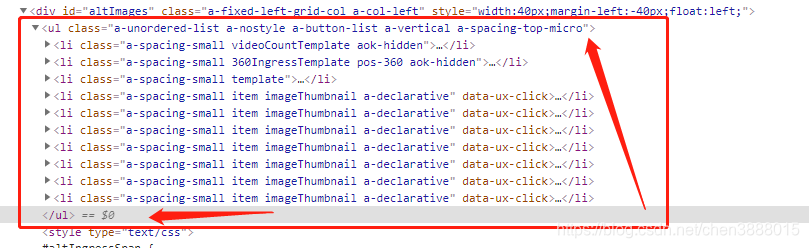
| <ul class="a-unordered-list a-nostyle a-button-list a-vertical a-spacing-top-micro"> <li class="a-spacing-small videoCountTemplate aok-hidden"><span class="a-list-item"> <li class="a-spacing-small template"><span class="a-list-item"> |
先把所有轮播图的列表属性给提取出来,class=样式内容会根据商品品类不同会有变化:
req.xpath('//ul[@class="a-unordered-list a-nostyle a-button-list a-vertical a-spacing-top-micro"]/li')
商品颜色属性的获取
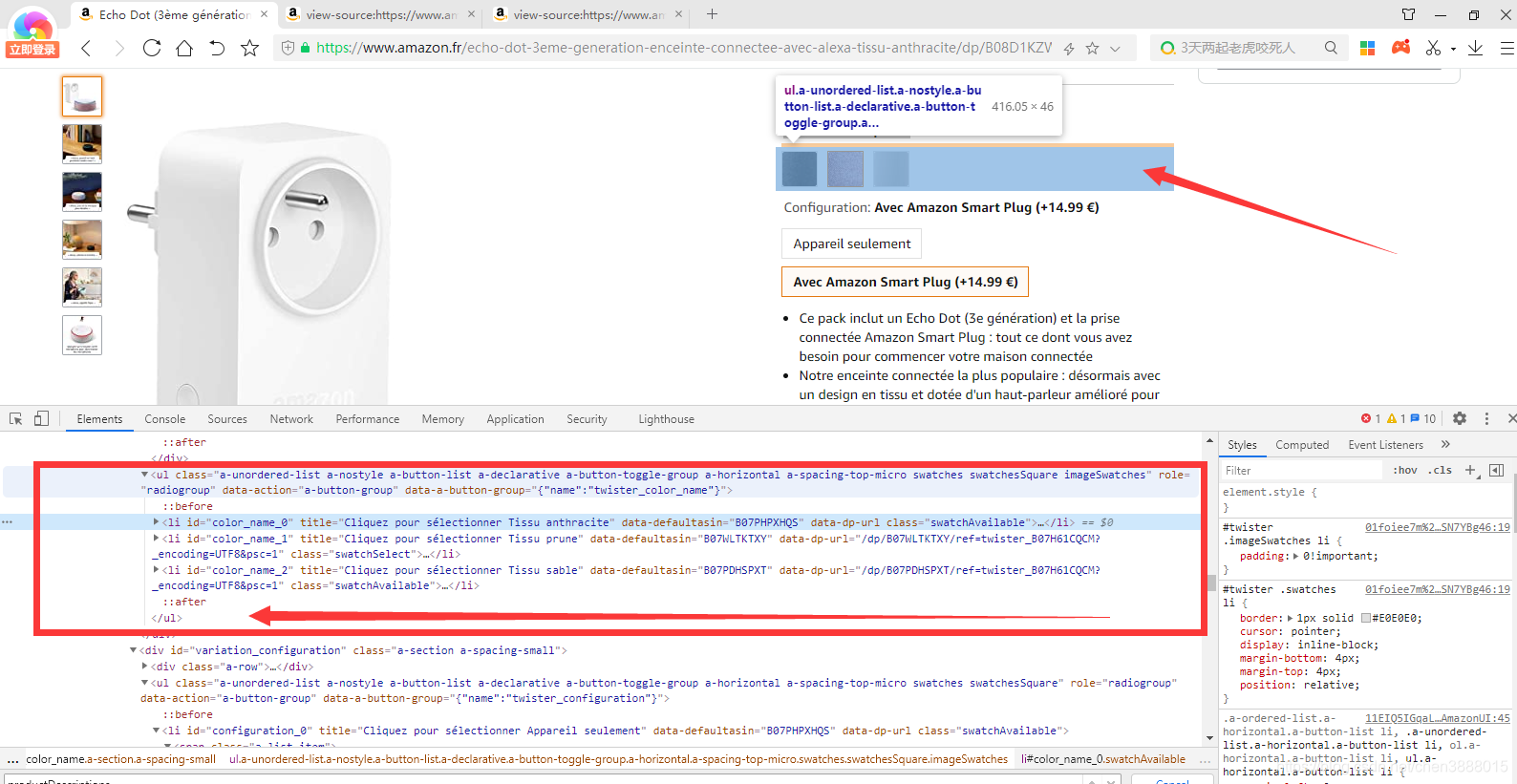
| <ul class="a-unordered-list a-nostyle a-button-list a-declarative a-button-toggle-group a-horizontal a-spacing-top-micro swatches swatchesSquare imageSwatches" role="radiogroup" data-action="a-button-group" data-a-button-group="{"name":"twister_color_name"}"> <li id="color_name_0" title="Cliquez pour sélectionner Tissu anthracite" data-defaultasin="B07PHPXHQS" data-dp-url="" class="swatchAvailable"><span class="a-list-item"> <span class="xoverlay"></span> <div class=" " style=""> </div> </div>
</span></li> <li id="color_name_1" title="Cliquez pour sélectionner Tissu prune" data-defaultasin="B07WLTKTXY" data-dp-url="/dp/B07WLTKTXY/ref=twister_B07H61CQCM?_encoding=UTF8&psc=1" class="swatchSelect"><span class="a-list-item"> <span class="xoverlay"></span> <div class=" " style=""> <li id="color_name_2" title="Cliquez pour sélectionner Tissu sable" data-defaultasin="B07PDHSPXT" data-dp-url="/dp/B07PDHSPXT/ref=twister_B07H61CQCM?_encoding=UTF8&psc=1" class="swatchAvailable"><span class="a-list-item"> <span class="xoverlay"></span> </ul> |
进行了简单的格式化处理
productColors=req.xpath('//li[@id="color_name_"]//text()')
productColor=''.join(Colors)
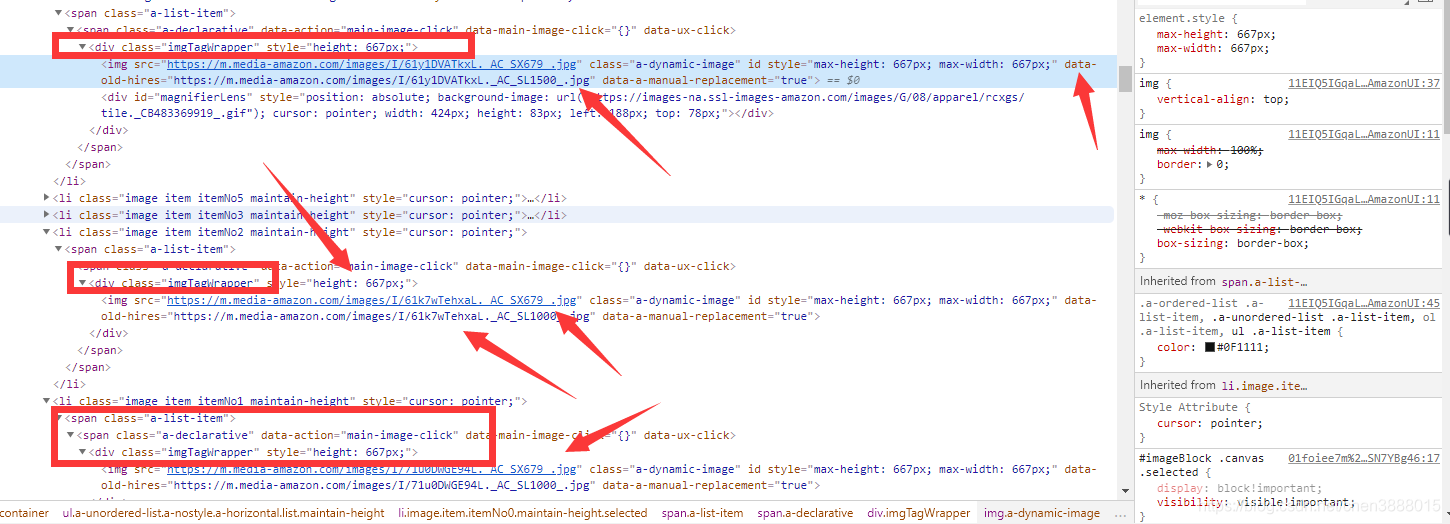
商品图片的的获取
主要是找到图片链接费了不少力气,写入到js中了,没办法,只能用正则获取到图片链接。
imgs_text=re.findall(r'ImageBlockATF(.+?)return data;',html,re.S)[0]
imgs=re.findall(r'"large":"(.+?)","main":',imgs_text,re.S)
图片有轮播图图片和鼠标划过的大图片

产品详情页面的图片

一个页面大概有3万多行代码,要挖掘出自己需要的数据,需要慢慢分析,最麻烦的应该是图片数据了。
附源码,仅供参考,学习,交流:
#法国亚马逊商品采集
#20200524 by 微信:huguo00289
#https://www.amazon.fr/dp/B07CNJTCBB/ref=twister_B07RVPW2GT?_encoding=UTF8&th=1
| # -*- coding=utf-8 -*- def get_data(url): if __name__ == '__main__': try: |
下面是美国亚马逊爬虫的参考代码
| # -*- coding: utf-8 -*- HEADERS = { 'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 10_1_1 like Mac OS X) AppleWebKit/602.2.14 (KHTML, like Gecko) Mobile/14B100 MicroMessenger/6.3.22 NetType/WIFI Language/zh_CN' def img_resize(infile,outfile):
if __name__ == '__main__': |
————————————————
版权声明:本文为CSDN博主「二爷记」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/minge89/article/details/106417047/
这篇关于法国亚马逊商品采集Python爬虫的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






