本文主要是介绍莫烦 强化学习视频整理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
RL知识整理
RL分类
按是否理解环境分类:
- Model-free RL(不理解环境):
用模型表示环境,从环境中得到反馈,再学习;
只能一步一步等真实世界的反馈
算法:Q Learning, Sarsa, Policy Gradients - Model-Based RL(理解环境):
可以模拟现实世界,有一个虚拟环境;
预判断反馈
算法:Q Learning, Sarsa, Policy Gradients
按思想分:
- Policy-Based RL(基于概率):
输出行动概率,然后根据概率采取行动(即使某一动作概率最大,也不一定会选择)
可以处理连续动作
算法:Policy Gradients - Value-Based RL(基于价值):
输出所有动作的价值,根据最高价值选择(就是选价值最高的)
无法处理连续动作
算法:Q Learning, Sarsa - Actor-Critic(二者结合)
Actor基于概率做出动作,Critic给出动作的价值
按更新方式分:
-
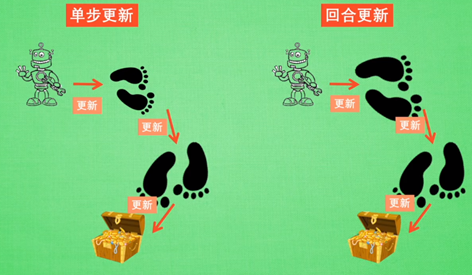
Monte-Carlo update(回合更新):
游戏开始后等待游戏结束,再更新
算法:基础版Policy Gradients, Monte-Carlo Learning -
Temporal-Difference update(单步更新):
游戏进行的每一步都进行更新
算法:Q-Learning, Sarsa, 升级版Policy Gradients
按是否离线分:
- On-Policy(在线学习):只能本人玩
算法:Sarsa - Off-Policy(离线学习):可以看着别人玩,从过往经验学习
算法Q Learning, Deep Q Network
Q Learning
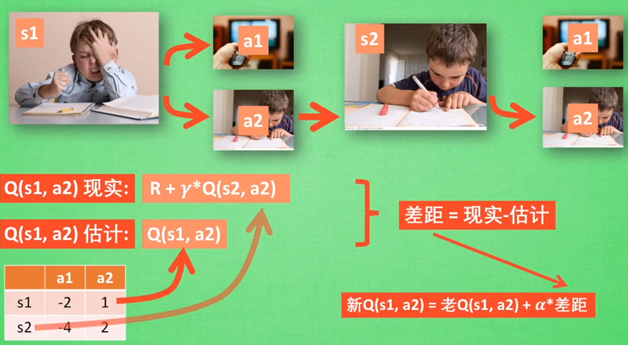
每一个决策过程都会有一个潜在奖励(建立Q表),Q值相当于采取动作时能够获得收益的期望,可用于评价在特定状态下采取某个动作的优劣。
首先根据state和Q table选择action(ε-greedy);执行action后,得到新的state和Q值以及奖励值;通过前一步的预测值和现在的真实值进行更新(见公式)
Q-learning的主要优势就是使用了时间差分法(融合了蒙特卡洛和动态规划)能够进行off-policy的学习,使用贝尔曼方程可以对马尔科夫过程求解最优策略


Sarsa
Q Learning在s_2估计选哪个动作会带来更大的奖励,Sarsa在s_2估计的动作就是要选择的动作
更新方式也变了,Sarsa选择离危险更远(on policy 胆子更小),Q Learning选择离成功更近

Q Learning:Off policy

Sarsa(𝝀)
𝝀:脚步衰减值(离奖励越远的步,越不重要)
Sarsa(0):单步更新法,只关注得到reward的前一步
Sarsa(1):回合更新,所有步更新力度一样
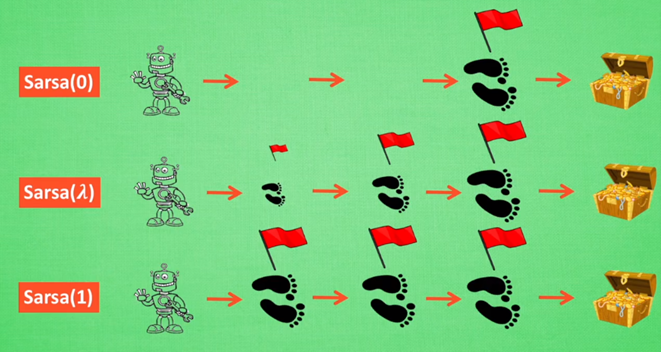
特点是需要额外维护一张E表,来衡量一个Episode内个体早期经过的状态对后续状态行为价值贡献的重要程度。

DQN
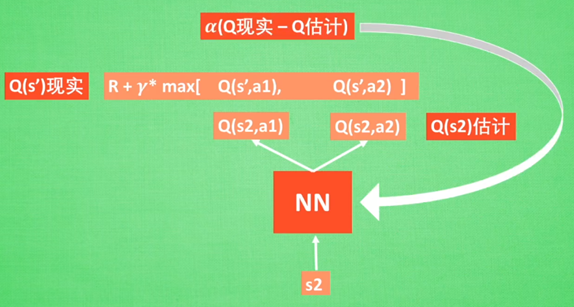
Deep Q Network:融合了神经网络+Q Learning
原因:状态太多了,全部用表格存储内存不够,且搜索耗时
过程:输入state和action,神经网络输出Q值;或者只输入state,输出所有动作值,直接选择最大值的动作

-
Experience replay
记忆库,用于重复学习
每次 DQN 更新的时候, 随机抽取一些之前的经历进行学习。随机抽取这种做法打乱了经历之间的相关性, 也使得神经网络更新更有效率 -
Fixed Q-targets
暂时冻结q_target参数,切断相关性;使神经网络更容易收敛
也是一种打乱相关性的机理, 如果使用 fixed Q-targets, 我们就会在 DQN 中使用到两个结构相同但参数不同的神经网络, 预测 Q 估计的神经网络具备最新的参数, 而预测 Q 现实的神经网络使用的参数则是很久以前的。 -
Q-Learning中用来计算target和预测值的Q是同一个Q,也就是说使用了相同的神经网络。这样带来的一个问题就是,每次更新神经网络的时候,target也都会更新,这样会容易导致参数不收敛。在有监督学习中,标签label都是固定的,不会随着参数的更新而改变。
-
因此DQN在原来的Q网络的基础上又引入了一个target Q网络,即用来计算target的网络。它和Q网络结构一样,初始的权重也一样,只是Q网络每次迭代都会更新,而target Q网络是每隔一段时间才会更新
-
改进:使用了卷积神经网络来逼近行为值函数;使用了target Q network来更新target;使用了经验回放Experience replay
Policy Gradient
特点:不通过分析奖励值,直接输出action,能够在连续区间内选择;
反向传递:大幅度提升高奖励action下一次被选择的概率,小幅度提升低奖励下一次被选中的概率
回合更新

Actor Critic
结合以值为基础和以概率为基础的算法。
Actor ->Policy Gradients 支持连续空间;
Critic-> Value-Based 能单步更新,提高学习效率
相当于actor选择下一步要做的行为,critic评判这个动作好不好
缺点:涉及到两个神经网络,且都是在连续状态中更新;导致神经网络学不到东西
=> Actor Critic + DQN = Deep Deterministic Policy Gradient
DDPG
优势:能在连续动作上有效学习
Deep + Deterministic Policy Gradient( Deterministic +Policy Gradient )
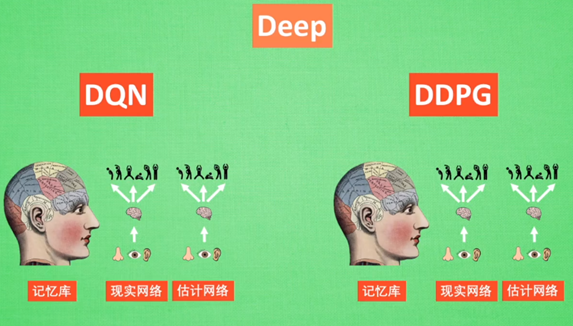
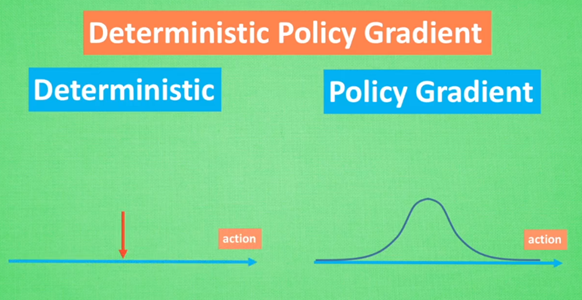
从DDPG网络整体上来说:他应用了 Actor-Critic 形式的, 所以也具备策略 Policy 的神经网络 和基于 价值 Value 的神经网络,因为引入了DQN的思想,每种神经网络我们都需要再细分为两个, Policy Gradient 这边,我们有估计网络和现实网络,估计网络用来输出实时的动作, 供 actor 在现实中实行,而现实网络则是用来更新价值网络系统的。再看另一侧价值网络, 我们也有现实网络和估计网络, 他们都在输出这个状态的价值, 而输入端却有不同, 状态现实网络这边会拿着从动作现实网络来的动作加上状态的观测值加以分析,而状态估计网络则是拿着当时 Actor 施加的动作当做输入。

这篇关于莫烦 强化学习视频整理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






