本文主要是介绍奥美中国签约斯图飞腾Stratifyd,用数据讲述更有意义的品牌故事,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

2020年12月,整合创意网络奥美中国(Ogilvy China)宣布正式签约Stratifyd,奥美希望借助Stratifyd增强智能数据分析平台帮助客户高效挖掘消费者反馈数据背后的故事,发现购买动机,掌握市场潮流和竞争动态,营造更有价值的品牌传播。
自1948年大卫·奥格威创立以来,奥美始终致力于为客户的品牌,打造极具影响力及代表性的营销传播作品。时至今日,奥美作为屡获殊荣的整合创意网络, 其遍布 83 个国家的 131个办公室秉持“让品牌更有意义”的宗旨,为众多财富五百强公司及本土企业效力。通过为品牌运筹帷幄、创造体验、树立名声,奥美以六项核心专长:品牌策略、广告、消费者互动及销售、公关及影响力、数字化转型、战略合作,在每个维度里提供服务,满足品牌的需求。

服务客户的过程中,奥美发现,许多客户都面临着消费者洞察的难题。在多触点、多渠道、随时在线的新消费时代,消费者乐于在社交媒体、电商平台、智能终端等不同渠道发表自己对于所购买产品或服务的观点和看法,这些数据对于品牌方了解消费者心理、洞察市场发展趋势具有非常大的参考价值。
如何将分散在各个渠道的消费者反馈数据串联整合?如何从中提炼有价值的洞察,精准把握消费者心理?如何迎合消费者喜好,推出更能激发消费者情感的品牌故事?
这一系列问题是奥美决定与Stratifyd寻求合作的重要契机。
挖掘数据背后的故事
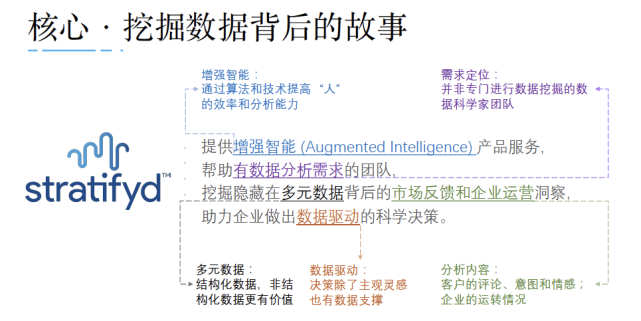
Stratifyd提供AI驱动的增强智能数据分析平台,帮助有数据分析需求的团队高效挖掘隐藏在多元数据背后的市场反馈和企业运营洞察,助力企业做出数据驱动的科学决策。此次签约合作,奥美将充分发挥Stratifyd在数据智能领域的技术和行业经验,帮助更多客户从第三方数据和客户自有数据中提炼出有价值的故事洞察,以此驱动精准而有影响力的市场营销。
用数据讲好故事
怎样理解“讲好故事”?
给人留下深刻印象的故事除了要求故事传递者讲求故事讲述手法,“讲好”故事,还要有引起共鸣的内容价值,讲出“好故事”。

Tips
讲好故事 x 讲好故事
“讲好”故事需要感人心扉的陈述,需要艺术色彩的渲染,需要阅人耳目的呈现,需要多元媒介的传载;同样,讲“好故事”也需要有迎合听众需求的共鸣,有精心雕琢的理论研究以及科学依据和数据的强力支撑!
所以,品牌方在向外界传播信息的同时也要思考自己是否向消费者传递了好的故事?
企业在找寻“好故事”的过程中会遇到多方面的问题,比如,怎样才能让客户觉得是个好故事?如何在有限的时间内快速捕捉到好的故事情节?
Stratifyd不仅可以帮助企业挖掘数据背后的故事,还可以帮助企业用数据讲好故事!
如果说一首动人的曲子离不开灵动的音符,那么一段美妙的故事也离不开扣人心弦的情节,而这些情节正是源自消费者的原生生活。企业应该从消费者的原声中去寻找灵感,将发现的知识点编织成动人的故事讲给消费者听,源自消费者心声的故事可以直击消费者心灵,引发情感共振,让消费者心甘情愿的为产品买单。
Stratifyd 从电商评论、社交媒体等一手、自发的消费者反馈中直接寻找体验和诉求,让故事更科学更有据可依。
另外,Stratifyd搭载自然语言处理和理解(NLP & NLU)、定向监控模型等AI底层技术,通过可交互的 BI 可视化实现抽象数据的具象表达,帮助企业从嘈杂的信息中快速梳理出有意义的规律洞察,让故事更丰满更动人!
奥美中国与Stratifyd此次强强联合将为更多有消费者洞察需求的客户带来福音。依托Stratifyd强大的技术支持和成熟的商业实践,奥美中国帮助客户精准把脉消费者购物旅程中每一个环节的体验,让客户知道消费者所思所想;同时,分析竞争对手占领消费者的心智点,找到差异化可能性,并在营销策略中找到突破口,打造更有意义的传播爆点。
成立至今,Stratifyd已签约包括欧唯特中国、联想集团、惠普、微软、礼来制药、梅赛德斯奔驰、万事达卡、花旗银行在内的众多财富500强企业,客户分布在快消、零售、金融、医药、软件、电子、制造、能源、咨询服务等多个行业,遍及美国、中国、澳大利亚、新西兰、日本、新加坡等十多个国家。
未来,Straitfyd致力于将成功的行业标杆案例复制给更多客户,让更多企业可以享受前沿AI算法带来的技术红利,实现数据驱动的高效运营和决策!
加群交流
为了方便用户及时获取Stratifyd培训信息、行业洞察白皮书/Gartner报告等干货资料,与数据同行交流经验,Stratifyd开通官方粉丝交流群!关注微信公众号并在后台回复“粉丝群”即可加入!快来互动吧~
END
关于斯图飞腾(Stratifyd Inc)
北京斯图飞腾科技有限公司(Stratifyd, Inc.)总部位于美国南部金融重镇夏洛特,是全球领先的增强智能(Augmented Intelligence)数据分析服务提供商。公司拥有强大的非结构化数据语义分析能力,致力于推进AI在企业数据分析以及商业智能领域的进步。Stratifyd增强智能平台通过整合多个数据源的结构化和非结构化数据,深入洞察消费者反馈数据背后的故事场景,在短时间内呈现出价值非凡的商业见解,助力企业提高客户体验和满意度,提升客户转化与留存,实现高质量的收入增长。Stratifyd增强智能平台已开放试用,访问官网(www.stratifyd.cn)或关注Stratifyd微信公众号,了解更多内容。
这篇关于奥美中国签约斯图飞腾Stratifyd,用数据讲述更有意义的品牌故事的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








