本文主要是介绍RAPTOR:树组织检索的递归抽象处理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
RAPTOR: RECURSIVE ABSTRACTIVE PROCESSING FOR TREE-ORGANIZED RETRIEVAL
Title:树组织检索的递归抽象处理
https://arxiv.org/pdf/2401.18059.pdf
摘要
检索增强语言模型可以更好的融入长尾问题,但是现有的方法只检索短的连续块,限制了整个文档上下文的整体理解。
文本提出方法:递归对文本块进行向量化,聚类,摘要,从下到上构建一棵具有不同摘要级别的树。
介绍
要解决的问题是,大多数现有的方法只检索几个短的、连续的文本块,这限制了它们表示和利用大规模话语结构的能力。
这与需要整合文本多个部分知识的主题问题特别相关,前k个检索到的短连续文本将不包含足够的上下文来回答问题。
为了解决这个问题,我们设计了一个索引和检索系统,该系统使用树结构来捕获文本的高级和低级细节。

相关工作
1.为什么需要检索:
模型往往没有充分利用长期上下文,并且随着上下文长度的增加,尤其是当相关信息嵌入到长上下文中时,性能会下降。此外,实际上,使用长上下文既昂贵又缓慢。
2.检索方法:
基于术语的方法(TFIDF,BM25)到基于深度学习的策略。
检索增强大模型包含多个组件:检索模块,阅读器,端到端系统训练。
向量化的检索方法缺点:连续分割可能无法捕捉到文本的完整语义深度。阅读从文件中提取的片段可能缺乏重要的上下文,使其难以阅读,甚至具有误导性。
3.递归总结:
摘要技术提供了文档的浓缩视图,使您能够更集中地处理内容。使用段落的摘要和片段,提高了大多数数据集的正确性,但有时可能是一种有损的压缩方式。
递归抽象摘要模型采用任务分解来总结较小的文本块,然后将其集成以形成较大部分的摘要。虽然这种方法可以有效地捕捉更广泛的主题,但它可能会错过细微的细节。
LlamaIndex通过类似地总结相邻的文本块,但也保留中间节点,从而存储不同级别的细节,保持细粒度的细节,从而缓解了这一问题。
然而,由于这两种方法都依赖邻接来对相邻节点进行分组或汇总,它们仍然可能忽略文本中遥远的相互依存关系。
方法
总体结构通过构建递归树结构来解决阅读中的语义深度和连接问题,该结构平衡了更广泛的主题理解和细粒度的细节,并允许根据语义相似性而不仅仅是文本中的顺序对节点进行分组。
step1.将语料库文本进行切分,每个切片大小为100个字符,但会保持句子的完整性。使用sbert对每个切片进行向量嵌入,切片和向量会形成树的叶子结点。
step2.使用聚类方法对切片进行分组,分组后的切片组使用LLM进行摘要总结。这样嵌入、聚类、总结循环进行,直到聚类不可行。最后生成了文档的树形结构表示。
step3.树的查询使用两种策略:树遍历和折叠树。树遍历方法逐层遍历树,每层进行树修剪并选择最相关的点。折叠树方法对所有层的节点进行集中评估。
聚类方法
聚类方法的一个独特要求是使用软集群,其中节点可以属于多个集群,而不需要固定数量的集群。这种灵活性至关重要,因为单个文本片段通常包含各种主题相关的信息,从而保证将其包含在多个摘要中。
本文使用混合高斯聚类方法(GMM),是一种软聚类方法,每个样本可以根据概率属于多个聚类簇。本文还使用了分层聚类(全部聚类和局部聚类),分两步进行的聚类过程捕获了文本数据之间的广泛关系,从广泛的主题到特定的细节。
基于模型的总结
摘要步骤将潜在的大量检索信息浓缩为可管理的大小。虽然摘要模型通常会产生可靠的摘要,但一项重点注释研究显示,约4%的摘要包含轻微幻觉。这些不会传播到父节点,也不会对问答任务产生明显影响。
查询
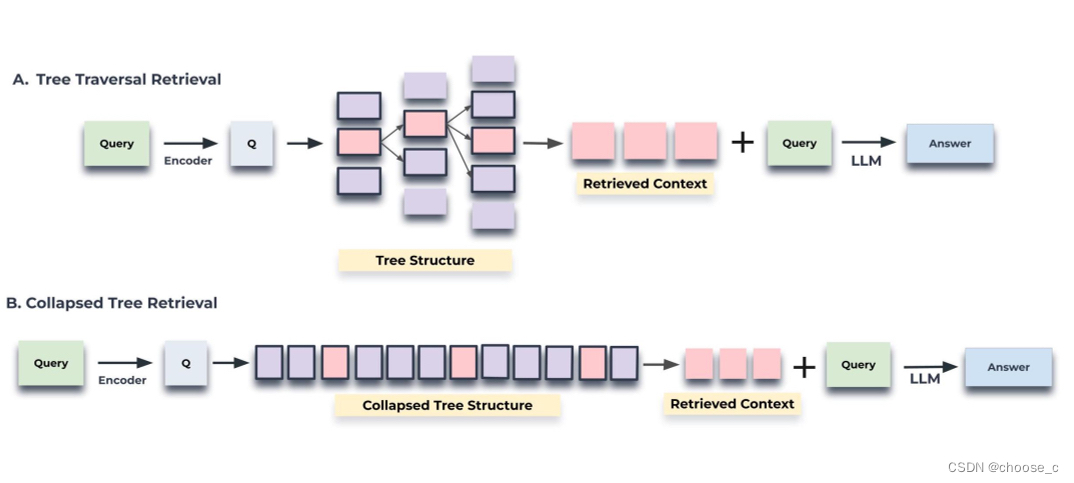
树遍历
树遍历方法首先基于前k个最相关的根节点与查询嵌入的余弦相似性来选择它们。在下一层考虑这些所选节点的子节点,并且基于它们与查询向量的余弦相似性再次从该池中选择前k个节点。重复此过程,直到我们到达叶节点。最后,将所有选定节点的文本连接起来,形成检索到的上下文。通过调整在每一层选择的深度d和节点k的数量,树遍历方法提供了对所检索信息的特异性和广度的控制。该算法从广阔的前景开始,通过考虑树的顶层,并在向下穿过较低层时逐渐关注更精细的细节。
折叠树
折叠树方法提供了一种更简单的方法,通过同时考虑树中的所有节点来搜索相关信息。这种方法不是一层一层地进行,而是将多层树扁平化为一层,基本上将所有节点放在同一级别进行比较。
实验
详情见论文。
总结
在本文中,我们提出了RAPTOR,这是一种新颖的基于树的检索系统,它利用不同抽象级别的上下文信息增强了大型语言模型的参数知识。通过使用递归聚类和摘要技术,RAPTOR创建了一个分层树结构,能够合成检索语料库各个部分的信息。在查询阶段,RAPTOR利用这种树结构进行更有效的检索。我们的对照实验表明,RAPTOR不仅优于传统的检索方法,而且在几个问答任务上设置了新的性能基准。
这篇关于RAPTOR:树组织检索的递归抽象处理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



