本文主要是介绍seatunnel数据集成(一)简介与安装,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
seatunnel数据集成(一)简介与安装
seatunnel数据集成(二)数据同步
seatunnel数据集成(三)多表同步
seatunnel数据集成(四)连接器使用
1、背景
About Seatunnel | Apache SeaTunnel
- SeaTunnel 是一个简单易用的数据集成框架。
- SeaTunnel的前身是 Waterdrop(中文名:水滴)自 2021 年 10 月 12日更名为 SeaTunnel。
- 2021 年 12 月 9 日,SeaTunnel 正式通过 Apache 软件基金会的投票决议,以全票通过的优秀表现正式成为 Apache 孵化器项目。
- 2022 年 3 月 18 日社区正式发布了首个 Apache 版本v2.1.0。
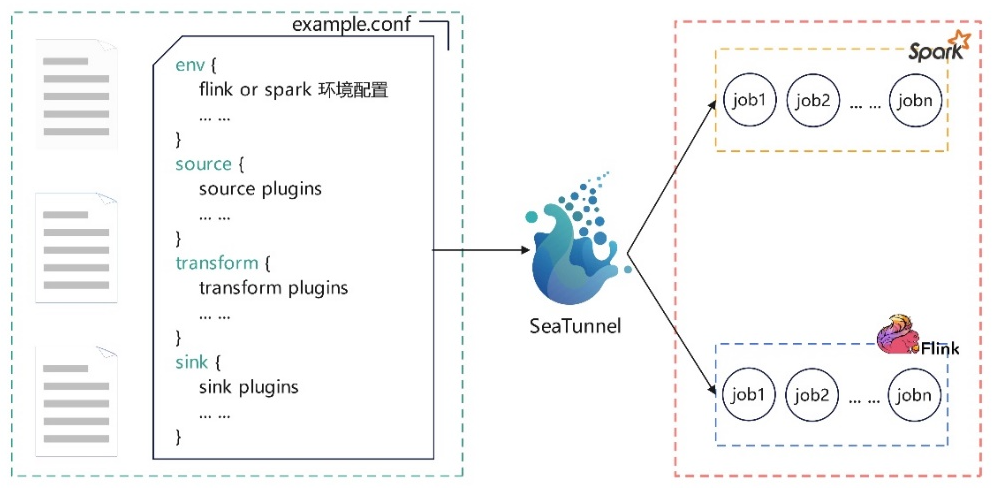
2、 应用场景
- 海量数据的同步
- 海量数据的集成
- 海量数据的ETL
- 海量数据聚合
- 多源数据处理
3、 特点
- 基于配置的低代码开发,易用性高,方便维护。
- 支持实时流式传输
- 离线多源数据分析
- 高性能、海量数据处理能力
- 模块化的插件架构,易于扩展
- 支持用SQL进行数据操作和数据聚合
- 支持Sparkstructured streaming
- 支持Spark 2.x
4、优势
- 丰富的连接器
- 批流一体、多种开发模式
- 转换海量数据
- 易管理维护
5、安装部署
下载解压
https://dlcdn.apache.org/incubator/SeaTunnel/2.3.1/apache-SeaTunnel-incubating-2.3.1-bin.tar.gz
下载完毕之后上传到服务器上面并解压
# 解压tar -zxvf apache-SeaTunnel-incubating-2.3.1-bin.tar.gz下载对应的connector
在Apache的仓库下载相应的connector,下载时每个jar包在不同的路径下面,放到/SeaTunnel-2.3.1/connectors/SeaTunnel目录下
https://repo.maven.apache.org/maven2/org/apache/SeaTunnel/
配置安装SeaTunnel的插件
vim SeaTunnel-2.3.1/config/plugin_config安装SeaTunnel
sh bin/install-plugin.sh 2.3.16、简单使用
bin目录下
install-plugin.sh --安装连接器脚本seatunnel-cluster.sh -–集群模式启动脚本seatunnel-cluster.sh --本地模式启动脚本start-seatunnel-flink-13-connector-v2.sh –-flink1.12-1.14版本引擎启动脚本start-seatunnel-flink-15-connector-v2.sh –-flink1.15-1.16版本引擎启动脚本start-seatunnel-spark-2-connector-v2.sh –-saprk2.x版本引擎启动脚本start-seatunnel-spark-3-connector-v2.sh –-saprk3.x版本引擎启动脚本stop-seatunnel-cluster.sh -–集群模式关闭脚本- 默认引擎seatunnel.sh。
- 提交spark任务用start-seatunnel-spark.sh。
- 提交flink任务则用start-seatunnel-flink.sh。
可以指定3个参数
分别是:
--config 应用配置的路径
--variable 应用配置里的变量赋值
--check 检查config语法是否合法
这篇关于seatunnel数据集成(一)简介与安装的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








