本文主要是介绍360全景超分学习记录,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
360 Panorama SR
- 鱼眼镜头成像原理
- 一些名词
- 相关论文
- 360 Panorama SR using Deep Convolutional Networks
- Abstract
- A single frame and multi-frame joint network for 360-degree panorama video SR
- Abstract
- 具体网络结构
鱼眼镜头成像原理
鱼眼镜头比一般镜头能抓取的视野更广,但同时也会导致一些畸变的存在,图像中心畸变最小,边缘畸变最大,如下图所示
鱼眼镜头现在多用于VR的全景拍摄中,是一种焦距为16mm或更短的并且视角接近或等于180°的镜头。为使镜头达到最大的摄影视角,这种摄影镜头的前镜片直径很短且呈抛物状向镜头前部凸出,与鱼的眼睛颇为相似,“鱼眼镜头”因此而得名。

鱼眼镜头成像是先让三维物体X投射到一个半球体q点上,再将q点通过不同方式(现在常见的有四种,具体可以看鱼眼投影方式)投影到成像平面上。传统的镜头是直线投影( θ d = θ \theta_d=\theta θd=θ),鱼眼镜头则是为了能扩大视野,强行“掰弯”,使得折射角小于入射角(也是模拟了光从空气进入水中的过程),在图中可以看到 θ d < θ \theta_d<\theta θd<θ

一些名词
- SRCNN
转载:SRCNN讲解
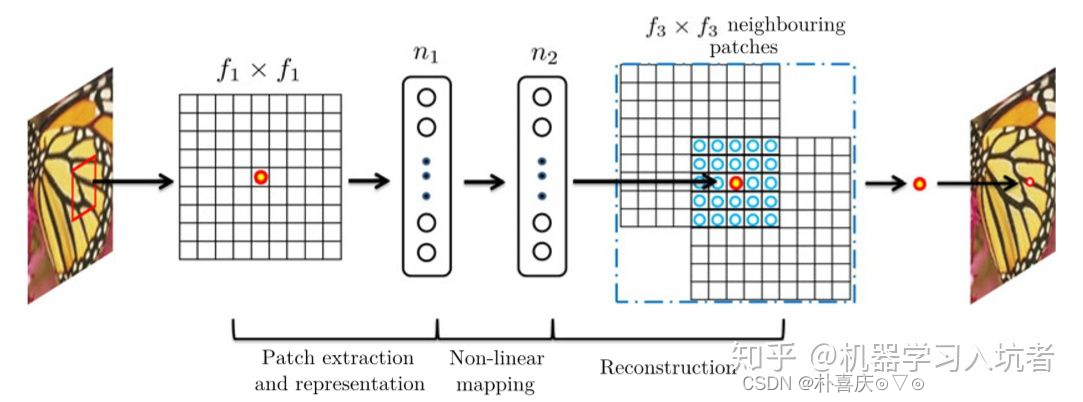
Patch extraction and representation:提取特征-卷积+激活 丛飞低分辨率图像中提取多个patch,经过卷积变为多维向量,所有特征向量组成特征矩阵
Non-linear mapping:卷积+激活,将n1维特征矩阵转化为n2维特征矩阵
Reconstruction:卷积,将特征矩阵还原为超分图像
损失函数:MSE
-
Equirectangular projection:ERP
等距柱状投影图:将球形的经度和纬度坐标,直接投影到水平和垂直坐标的一格,这个网格的高度大约为宽的两倍。因此从赤道到两极,横向拉伸不断加剧,南北两个极点被拉伸成了扁平的网格在整个上部和下部边缘。 Equirectangular可以现实整个水平和竖直的360全景。
-
Cubemap projection: CMP
CMP投影讲解立方体投影:Cubemap Projection(CMP)将球面全景图像映射到了立方体的6个面上,如下图。

还有多种排列组合

相关论文
360 Panorama SR using Deep Convolutional Networks
Abstract
base on SRCNN
input sub-images (randomly), crop training images
A single frame and multi-frame joint network for 360-degree panorama video SR
Abstract
ERP format
weighted loss aims to increase the wieghts of the equatorial regions while decreasing the eights of the polar regions
SMFN: single frame and multi-frame joint network
- single frame SR network - spatial information, 多个卷积+ReLU激活
- multi-frame network - temporal information
- dual network - constrain solution space, transfer SR image back into LR space
- fusion model
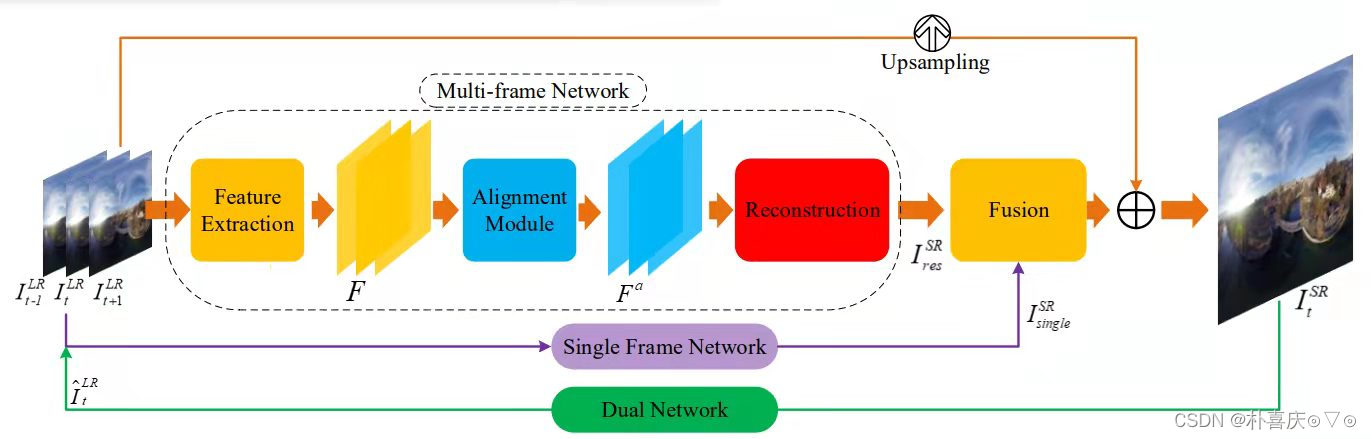
具体网络结构
Multi-frame Network:
(1) Shallow Feature Extraction: residual block (Conv+Relu+Conv)
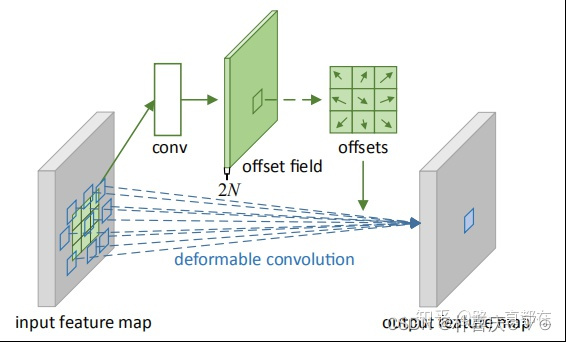
(2) Alignment Module: deformable conv network可形变对齐 - input: target features and neighboring features - learn: offsets 学到offset后进行变形卷积 查看转载讲解:可变形卷积
(3) Reconstruction Module: deep feature extraction + fusion + mixed attention + upscale module
i) deep feature extraction and fusion: RDB(residual dense block)
ii) mixed attention: channel attention (CA) & space attention (SA)
input separately fed into CA & SA - add CA maps and SA maps - multiply mixed attetion maps and initial input features
iii) upscale module: sub-pixel 讲解转载:sub-pixel
iv) fusion module(没有具体说明如何操作): conv layers x3
Output = fusion后的 + bilinear(LR)
Dual Network: 两层卷积,步长为2
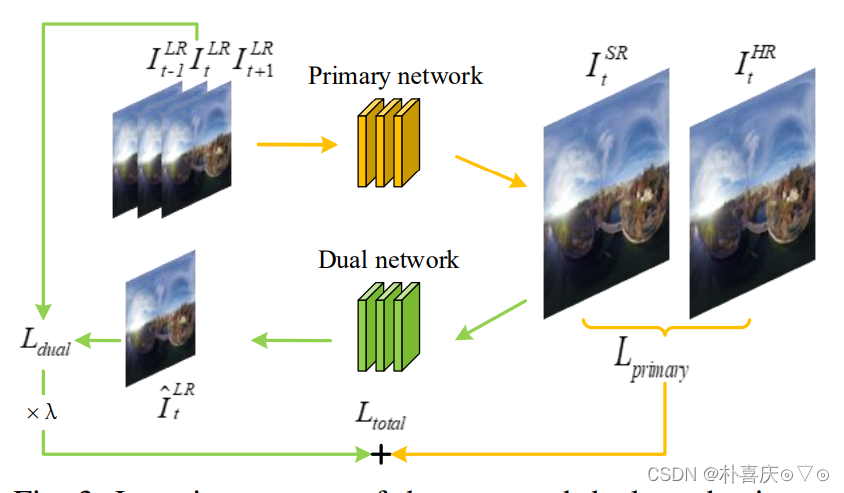
Loss function: weighted mean square loss
纬度越低,weights越高
这篇关于360全景超分学习记录的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




