本文主要是介绍降噪自动编码机 Denoising Autoencoder,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
自动编码机(Auto-encoder)属于非监督学习,不需要对训练样本进行标记。自动编码机(Auto-encoder)由三层网络组成,其中输入层神经元数量与输出层神经元数量相等,中间层神经元数量少于输入层和输出层。在网络训练期间,对每个训练样本,经过网络会在输出层产生一个新的信号,网络学习的目的就是使输出信号与输入信号尽量相似。自动编码机(Auto-encoder)训练结束之后,其可以由两部分组成,首先是输入层和中间层,我们可以用这个网络来对信号进行压缩;其次是中间层和输出层,我们可以将压缩的信号进行还原。
首先来看看Bengio论文中关于dAE的示意图,如下:
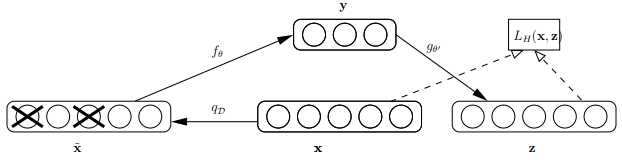
由上图可知,样本x按照qD分布加入随机噪声后变为 ,按照文章的意思,这里并不是加入高斯噪声,而是以一定概率使输入层节点的值清为0,这点与神经网络中 dropout 的机制很类似,只不过dropout作用在隐含层。此时输入到可视层的数据变为,隐含层输出为y,然后由y重构x的输出z,注意此时这里不是重构 ,而是x.
Bengio对dAE的直观解释为:1.dAE有点类似人体的感官系统,比如人眼看物体时,如果物体某一小部分被遮住了,人依然能够将其识别出来,2.多模态信息输入人体时(比如声音,图像等),少了其中某些模态的信息有时影响也不大。3.普通的autoencoder的本质是学习一个相等函数,即输入和重构后的输出相等,这种相等函数的表示有个缺点就是当测试样本和训练样本不符合同一分布,即相差较大时,效果不好,明显,dAE在这方面的处理有所进步。
当然作者也从数学上给出了一定的解释。
- 流形学习的观点。一般情况下,高维的数据都处于一个较低维的流形曲面上,而使用dAE得到的特征就基本处于这个曲面上,如下图所示。而普通的autoencoder,即使是加入了稀疏约束,其提取出的特征也不是都在这个低维曲面上(虽然这样也能提取出原始数据的主要信息)。
 2. 自顶向下的生成模型观点的解释。3.信息论观点的解释。4.随机法观点的解释。这几个观点的解释数学有一部分数学公式,大家具体去仔细看他的paper。
2. 自顶向下的生成模型观点的解释。3.信息论观点的解释。4.随机法观点的解释。这几个观点的解释数学有一部分数学公式,大家具体去仔细看他的paper。
当在训练深度网络时,且采用了无监督方法预训练权值,通常,Dropout和Denoise Autoencoder在使用时有一个小地方不同:Dropout在分层预训练权值的过程中是不参与的,只是后面的微调部分引入;而Denoise Autoencoder是在每层预训练的过程中作为输入层被引入,在进行微调时不参与。另外,一般的重构误差可以采用均方误差的形式,但是如果输入和输出的向量元素都是位变量,则一般采用交叉熵来表示两者的差异。
用途
Denoising Autoencoder 被广泛应用的 pre-train 阶段,主要用于对原始样本的去噪。
以下是Are Large-scale Datasets Necessary for Self-Supervised Pre-training? 这篇文章对其应用的介绍。
Pre-training with autoencoders has a long history in
deep learning, where it was initially used as a greedy layer-wise method to improve optimization [25, 26, 27, 28, 29]. In the context of unsupervised feature learning for image classification, different tasks related to denoising autoencoders have been considered, such as in-painting [30], colorization [31] or de-shuffling of image patches [32]. In natural language processing, denoising autoencoders have been applied by masking or randomly replacing some tokens of the input, and reconstructing the original sequence, leading to the BERT model [23]. Similar methods have been proposed to pre-train sequence-to-sequence models, by considering additional kind of noises such as word shuffling or deleting [33, 34].
There has been efforts to adopt such successful ideas in
NLP to computer vision, but with limited success. Chen
et al. [35] proposed iGPT, a transformer-based autoregressive model that operates over image pixels, while Atito et al. [36] trained a ViT model on denoising of images where the noise is applied at pixel level. More recently, Bao et al. [24] introduced the Masked Image Modeling loss in computer vision, where image patches are masked, and the goal is to predict the discretized label of the missing patches corresponding to their visual words as defined by a pre-trained discrete VAE [37].
参考:
https://www.cnblogs.com/tornadomeet/p/3261247.html
https://blog.csdn.net/n1007530194/article/details/78369429/
这篇关于降噪自动编码机 Denoising Autoencoder的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







