本文主要是介绍页面单跳转换率统计案例分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
需求说明
页面单跳转化率
计算页面单跳转化率,什么是页面单跳转换率,比如一个用户在一次 Session 过程中访问的页面路径 3,5,7,9,10,21,那么页面 3 跳到页面 5 叫一次单跳,7-9 也叫一次单跳, 那么单跳转化率就是要统计页面点击的概率。 比如:计算 3-5 的单跳转化率,先获取符合条件的 Session 对于页面 3 的访问次数(PV) 为 A,然后获取符合条件的 Session 中访问了页面 3 又紧接着访问了页面 5 的次数为 B, 那么 B/A 就是 3-5 的页面单跳转化率。

功能实现
数据准备:
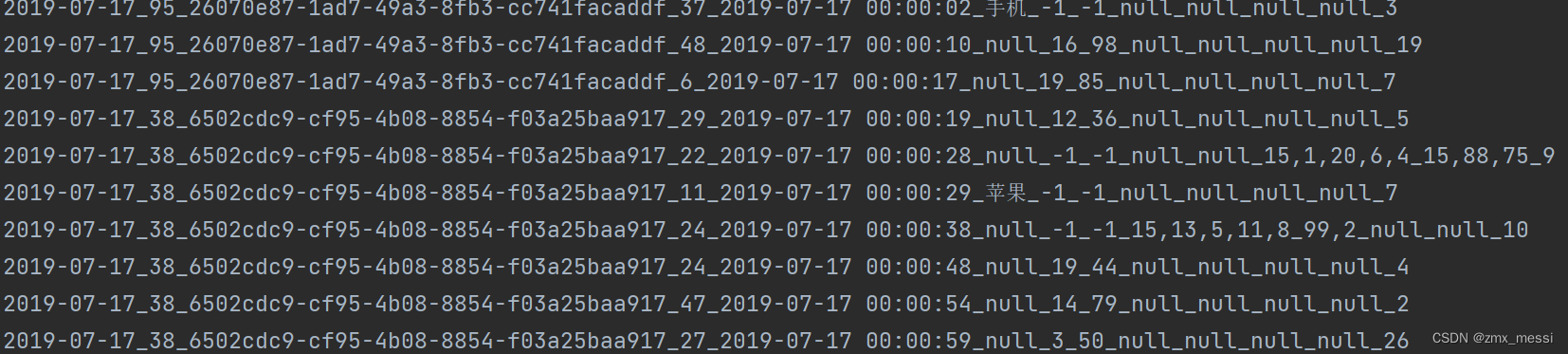
// TODO : Top10热门品类val sparkConf = new SparkConf().setMaster("local").setAppName("HotCategoryTop10Analysis")val sc = new SparkContext(sparkConf)val actionRDD = sc.textFile("data/user_visit_action.txt")data/user_visit_action.txt :
定义一个用户访问动作类:
case class UserVisitAction(date: String,//用户点击行为的日期user_id: Long,//用户的 IDsession_id: String,//session 的 IDpage_id: Long,//某个页面的 IDaction_time: String,//动作的时间点search_keyword: String,//用户搜索的关键词click_category_id: Long,//某一个商品品类的 IDclick_product_id: Long,//某一个商品的 IDorder_category_ids: String,//一次订单中所有品类的 ID 集合order_product_ids: String,//一次订单中所有商品的 ID 集合pay_category_ids: String,//一次支付中所有品类的 ID 集合pay_product_ids: String,//一次支付中所有商品的 ID 集合city_id: Long //城市 id)然后将每行数据封装成UserVisitAction对象,运用map转换算子:
val actionDateRDD = actionRDD.map( //每行数据封装成UserVisitAction对象action => {val datas = action.split("_")UserVisitAction(datas(0),datas(1).toLong,datas(2),datas(3).toLong,datas(4),datas(5),datas(6).toLong,datas(7).toLong,datas(8),datas(9),datas(10),datas(11),datas(12).toLong)})由于统计所有的页面跳转数据量过于庞大,这里就指定一下:
//TODO 对指定页面连续跳转进行统计//1-2,2-3,3-4,4-5,5-6,6-7val ids = List[Long](1, 2, 3, 4, 5, 6, 7)val okflowIds = ids.zip(ids.tail) //List((1, 2), (2, 3), (3, 4), (4, 5), (5, 6), (6, 7))接下来统计每个页面的被查看的次数,也就是分母,actionDateRDD里面封装的是一个个UserVisitAction对象,运用filter转换算子过滤出List所包含的页面,再用map转换算子将一个UserVisitAction对象转换成(action.page_id, 1L),便于后续的reduceByKey作统计,而toMap方法是将RDD中的数据转换为一个Map对象,需要将所有的数据收集到Driver端,并在Driver端构建Map对象。因此,需要使用collect方法将RDD中的数据拉取到Driver端的内存中,以便在Driver端进行toMap操作。
//TODO 计算分母(计算每个页面的被查看的次数)val pageidToCountMap = actionDateRDD.filter( //过滤出List里面的页面action => {ids.contains(action.page_id)}).map(action => {(action.page_id, 1L)}).reduceByKey(_ + _).collect().toMapprintln("pageidToCountMap: ")pageidToCountMap.foreach(println)接下来统计分子,首先根据session_Id进行分组:
val sessionRDD = actionDateRDD.groupBy(_.session_id)再将UserVisitAction对象根据访问时间action_time排序,然后用map算子只保留对象的page_id,再用zip拉链:
val mvRDD = sessionRDD.mapValues(iter => {val sortList = iter.toList.sortBy(_.action_time)val flowIds = sortList.map(_.page_id)val pageflowIds = flowIds.zip(flowIds.tail)将不满足条件的页面跳转进行过滤:
val mvRDD = sessionRDD.mapValues(iter => {val sortList = iter.toList.sortBy(_.action_time)val flowIds = sortList.map(_.page_id)val pageflowIds = flowIds.zip(flowIds.tail)//将不合法的页面跳转进行过滤pageflowIds.filter(t=>{okflowIds.contains(t)}).map(t => {(t, 1)})})mvRDD大致格式长这样:

sessionid对于我们来说没有用,只需计算后面的页面跳转内容即可,用map算子处理,再用flatmap扁平化处理,便于后续的reduceByKey聚合:
//((1,2),1)val flatRDD = mvRDD.map(_._2).flatMap(list => list)//((1,2),sum)val dataRDD = flatRDD.reduceByKey(_ + _)最终计算:
//计算单跳转换率 分子/分母dataRDD.foreach{case ((page1,page2),sum)=>{val cnt = pageidToCountMap.getOrElse(page1, 0L)println(s"页面${page1}到页面${page2}单跳转换率为: "+(sum.toDouble/cnt))}}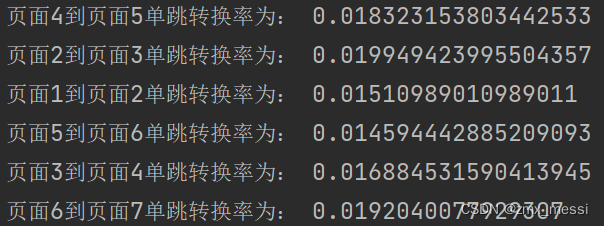
这篇关于页面单跳转换率统计案例分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




