本文主要是介绍Power Pivot 系列 (4) - DAX 查询,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Power Pivot 通过 DAX 查询可以实现从不同的视角查看数据。但在 Excel 中编写 DAX 查询却不太方便,所以本篇在讲解 DAX 查询用法的时候,以 DAX Studio 作为工具。关于 DAX Studio 请自行在网上搜索,我的上一篇也有介绍。
本篇的示例数据来自 《DAX 圣经》这本书,示例数据我已经上传到 github,文章的末尾有链接,方便大家学习。
查询表的所有数据
DAX 查询一般从 EVALUATE 关键字开始,可以把 DAX 查询语句理解为 EVALUATE 关键字引导的表达式构成的语句。比如我要查询 Sales 表的所有数据,DAX 查询语句为:
-- 查询 Sales 表所有数据
EVALUATE Sales

相当于 SQL 语句的 SELECT * FROM Sales; 第一行是注释。
字段排序
DAX 查询的 ORDER BY 关键字引导的表达式对查询结果进行排序。升序为 ASC,降序为DESC 。
-- 按 Order Date字段排序
EVALUATE
Sales ORDER BY [Order Date] ASC
DAX 支持按多个字段排序:
EVALUATE
Sales
ORDER BY[Order Date] ASC,[CustomerKey] ASC
选择指定字段
SQL 语句选择指定字段很直观:SELECT A, B FROM sometable。DAX 查询选择指定字段用 SUMMARIZE 函数。SUMMARIZE 函数第一个参数为 table 的名称,后面跟若干个字段,即可以选择指定的列:
EVALUATE
SUMMARIZE ( 'Sales', [ProductKey], [OrderDateKey], [Quantity], [Unit Price] )
DAX 查询结果的界面:

数据筛选
数据筛选用 FILTER 函数,FILTER 函数第一个参数为 table 名称,第二个参数为筛选表达式,返回值为 table。比如我们要筛选出 Product 表中所有 Class 为 Economy 的数据:
EVALUATE
FILTER ( 'Product', Product[Class] = "Economy")
分组计算
数据透视表就是分组计算,如果我们要数据透视表的逻辑,但并不需要数据透视表的格式,使用 DAX 查询的分组计算作为输出就非常合适。分组计算用到 SUMMARIZE 函数的标准用法。SUMMARIZE 函数语法如下:
SUMMARIZE(<table>, <groupBy_columnName>[, <groupBy_columnName>]…[, <name>, <expression>]…)
函数的第一个参数是 table 名称;第二组参数是一系列列名称,根据列名进行分组,比如先按照客户,再按照产品名称等等;第三组参数由 name 和 expression 成对构成,比如 name 为 toal quantity, expression 为 SUM([Quantity],就根据 Quantity 列来计算合计数。假设我们需要按客户来计算销售的数量:
EVALUATE
SUMMARIZE ( Sales, [CustomerKey], "Total Sales", SUM ( Sales[Quantity] ) )
多字段分组:先按照客户,再按照产品分组计算销售数量的合计:
EVALUATE
SUMMARIZE (Sales,[CustomerKey],[ProductKey],"Total Quantity", SUM ( Sales[Quantity] )
)
ORDER BY [CustomerKey]
基于多表的操作
前面的示例都是基于一个表,接下来讲解多表关联的 DAX 查询。Power Pivot 中表的关系在关系图视图中维护,关系维护好后,在 DAX 查询时,表的关系都为左连接且不能修改为其它连接方式。这种机制虽然降低了灵活性,但却让 DAX 基于多表的查询语法变得非常简单。
比如我们要查询基于客户名称和产品名称的销售数量明细。我们刚才讲过,返回指定字段用 SUMMARIZE 函数:
EVALUATE
SUMMARIZE (Sales,Customer[Company Name],'Product'[Product Name],Sales[Quantity]
)
查询结果截图如下:
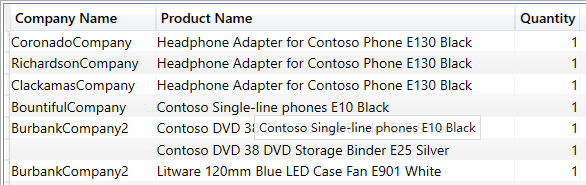
这个查询涉及到 3 个表的关联,相同功能的 SQL 语句要复杂得多。同理,基于多个表的分组计算,也是只需要选择某个表的字段,而不需要关注表的关系。我们来对基于客户和产品计算销售数量合计的查询进行变更:
EVALUATE
SUMMARIZE (Sales,Customer[Company Name],'Product'[Product Name],"Total Sales", SUM ( Sales[Quantity] )
)
查询的截图如下:
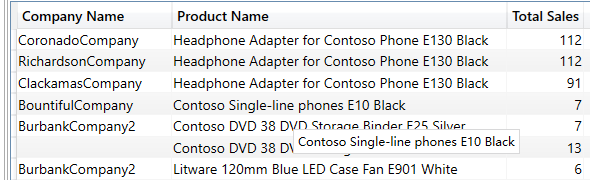
数据筛选也能自由地使用其他表的字段。比如下面的示例,查询 Sales 表,但筛选条件是 Product 的 Brand 为 Litware。需要用到 RELATED 函数:
EVALUATE
FILTER ( Sales, RELATED ( Product[Brand] ) = "Litware" )
基于多表筛选且选择指定字段
嵌套使用 FILTER 和 SUMMARIZE 函数能达到这种效果。先用 SUMMARIZE 函数返回一个包含指定列的表,然后用 FILTER 函数基于这个计算表进行筛选:
EVALUATE
FILTER (SUMMARIZE (sales,Customer[Country],Product[Brand],"Total Quantity", SUM ( Sales[Quantity] )),[Brand] = "Contoso"
)
添加列
添加列在 Power Pivot 中非常容易,但我们也可以在 DAX 查询中使用 ADDCOLUMNS 函数来添加列。ADDCOLUMNS 函数的语法如下:
ADDCOLUMNS(<table>, <name>, <expression>[, <name>, <expression>]…)
根据函数的语法,我们知道,可以一次添加多个列。下面的示例添加了一个计算列:计算出每一行的销售金额(单价 * 数量):
EVALUATE
ADDCOLUMNS ( Sales, "Line Prcie", Sales[Quantity] * Sales[Unit Price] )
定义变量
在 DAX 查询中,可以使用 VAR 定义变量,使用变量能够简化 DAX 查询语句的编写。定义变量需要在 EVALUATE 之前用 DEFINE 关键字引导,用 VAR 定义变量。比如,我们先定义一个按客户的国别和产品品牌分组计算销售数量的表,将这个表保存在变量 groupedSales 中,然后对销售按品牌进行筛选:
DEFINEVAR groupedSales =SUMMARIZE (Sales,Customer[Country],'Product'[Brand],"Total Quantity", SUM ( Sales[Quantity] ))
EVALUATE
FILTER ( groupedSales, [Brand] = "Contoso" )
在 DAX 查询中定义度量值
DAX 查询也可以定义度量值。度量值用 MEASURE 关键字定义,MEASURE 返回一个标量值。比如我们要按照品牌计算出销售额,先定义一个度量值,然后再基于品牌来作为筛选上下文计算。这种方法相对难懂,仅为了介绍定义度量值的方法。注意下面 DAX 查询中度量值的表达方法。
DEFINEMEASURE Sales[salesamt] =SUMX ( Sales, Sales[Quantity] * Sales[Unit Price] )
EVALUATE
ADDCOLUMNS ( VALUES ( 'Product'[Brand] ), "Total Sales", 'Sales'[salesamt] )
示例数据
github - sample data
参考
- 理解EVALUATE语法
- Using DAX to retrieve tabular data
这篇关于Power Pivot 系列 (4) - DAX 查询的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







