本文主要是介绍Business Intelligence商业智能:概念、数据仓库、相关工具,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、前言
datawarehouse data marts, and data lakes

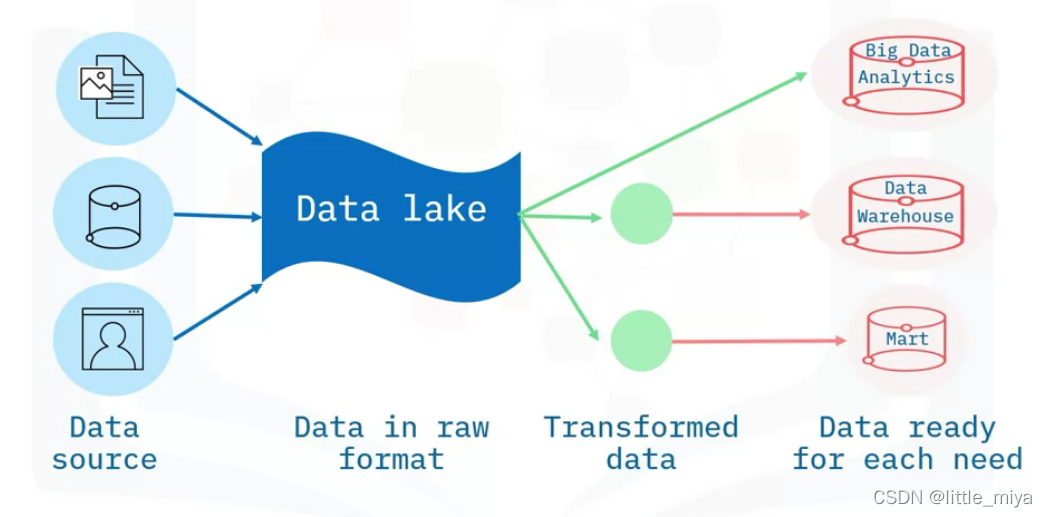






data warehouses
Enterprise Data Warehouse 通用架构:

data cube:

slicing:
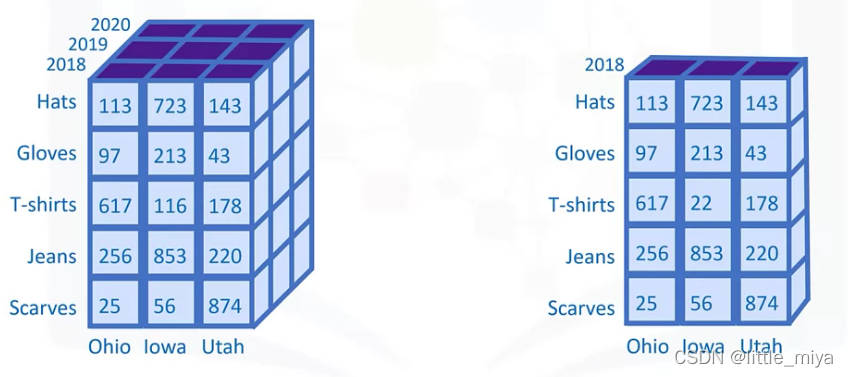
dicing:

drilling:

pivoting:

rolling up(aggregate):

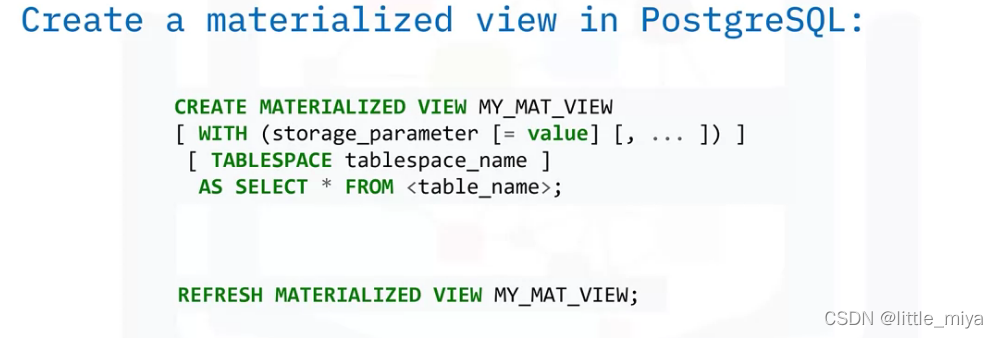
meterialized views

可以设置不同的refresh option:
never: creation的时候常用
upon request: manually 或者scheduled
immediately: automatically after every statement
举个例子:

在postgreSQL中,我们使用如下命令:
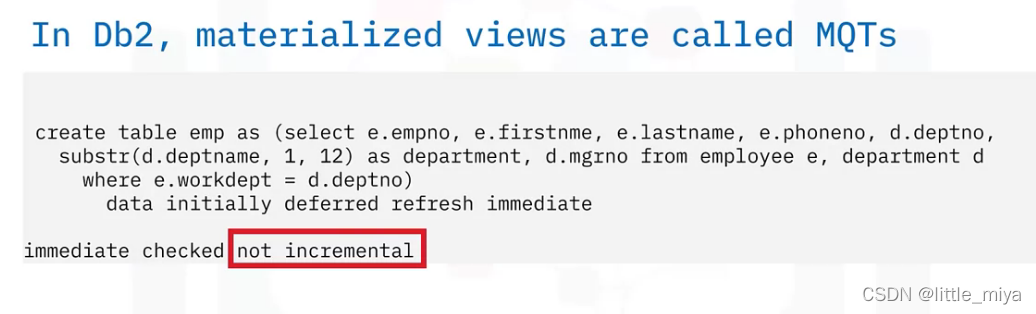
在Db2 被称为MQT:
facts and dimensions table
我的理解:
基本就是facts tables 是带primary key的table,通过各种foreign key和dimesions table连接在一起.
facts 是一个中枢,dimension是这套data的多个维度.
从这里可以衍生出来两个概念, star schema, 和 snowflake schema
如下图, 这是一个pos 机销售数据.红框部分是最开始设计的star schema, 之后往外长出来的 snowflake schema


staging area
定义:
是ETL过程中的中间存储站
是搭建在data sources 和 target system之间的桥梁
有时候只是短暂存在
有时可以用于归档,用于troubleshooting
也可以用来优化和监控ETL jobs
 举个例子:
举个例子:

functions:
- integration
- change detaction
- scheduling
- cleansing data
- aggregation
- normalization
data quality

python的生成数据质量报告的模板:
import os
import psycopg2
import pandas as pd
from tabulate import tabulateimport mytests
# import the data quality checks
from dataqualitychecks import check_for_nulls
from dataqualitychecks import check_for_min_max
from dataqualitychecks import check_for_valid_values
from dataqualitychecks import check_for_duplicates
from dataqualitychecks import run_data_quality_check# connect to database
pgpassword = os.environ.get('POSTGRES_PASSWORD')
conn = psycopg2.connect(user = "postgres",password = pgpassword,host = "localhost",port = "5432",database = "billingDW")print("Connected to data warehouse")#Start of data quality checks
results = []
tests = {key:value for key,value in mytests.__dict__.items() if key.startswith('test')}
for testname,test in tests.items():test['conn'] = connresults.append(run_data_quality_check(**test))#print(results)
df=pd.DataFrame(results)
df.index+=1
df.columns = ['Test Name', 'Table','Column','Test Passed']
print(tabulate(df,headers='keys',tablefmt='psql'))
#End of data quality checks
conn.close()
print("Disconnected from data warehouse")其中 mytest 内容包括:
from dataqualitychecks import check_for_nulls
from dataqualitychecks import check_for_min_max
from dataqualitychecks import check_for_valid_values
from dataqualitychecks import check_for_duplicatestest1={"testname":"Check for nulls","test":check_for_nulls,"column": "monthid","table": "DimMonth"
}test2={"testname":"Check for min and max","test":check_for_min_max,"column": "monthid","table": "DimMonth","minimum":1,"maximum":12
}test3={"testname":"Check for valid values","test":check_for_valid_values,"column": "category","table": "DimCustomer","valid_values":{'Individual','Company'}
}test4={"testname":"Check for duplicates","test":check_for_duplicates,"column": "monthid","table": "DimMonth"
}populating a data warehouse
前提:

具体步骤:

建立relationship就是建外键, 如下是sql语法.
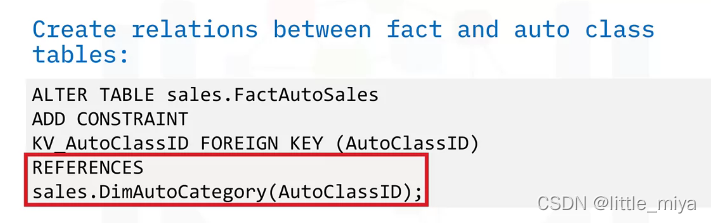
在db2中创建MQT的的sql语法:
CREATE TABLE avg_customer_bill (customerid, averagebillamount) AS
(select customerid, avg(billedamount)
from factbilling
group by customerid
)DATA INITIALLY DEFERREDREFRESH DEFERREDMAINTAINED BY SYSTEM;
querying the data
面向star schema, 通过join的方式,可以将真实想要看到的内容呈现出来. 让内容更加可读.
同样的关键字包括rollup,与cube稍微不同. 严格按照group的column顺序来, 如果没有第一个col,就不会再做展示.
我们可以创建staging table from materialized views , 实现渐进的刷新(incrementally refresh)
data warehouse analysis
BI tools

工具list:

基本就是这个模式:
- get connected
- prepare your data
- build visualization
- find patterns
- generate reports
- gain insights
这篇关于Business Intelligence商业智能:概念、数据仓库、相关工具的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








