本文主要是介绍python爬虫和信息处理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
rquests模块
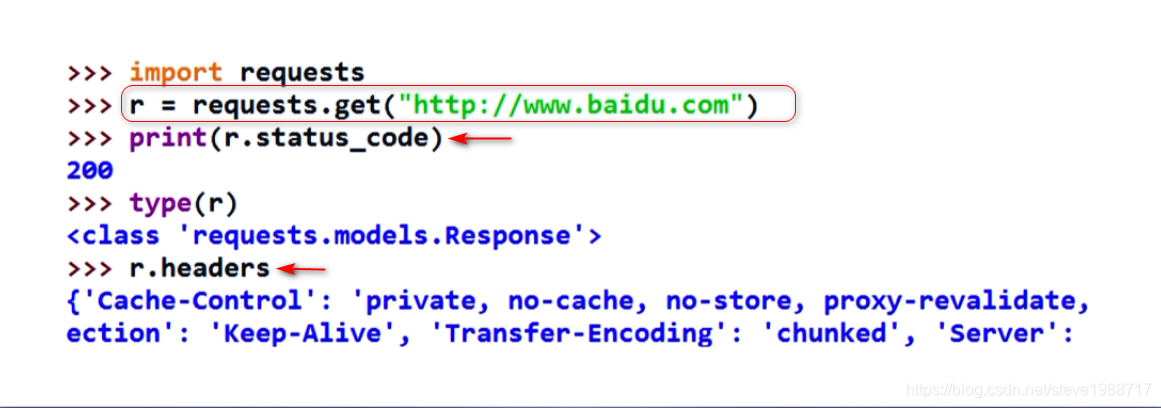


get 方法 获得网页资源
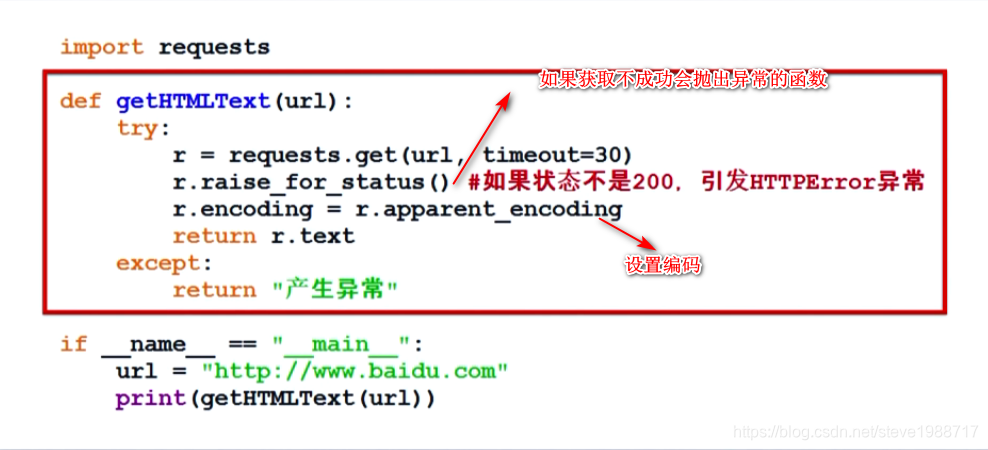
head方法,获取网页的头部信息,节省带宽;分析大概内容
put方法,向URL上存放资源,URL上原来的资源会全部被覆盖掉
patch方法,也是想url上存放资源,只是改变部分数据,其他数据不受影响


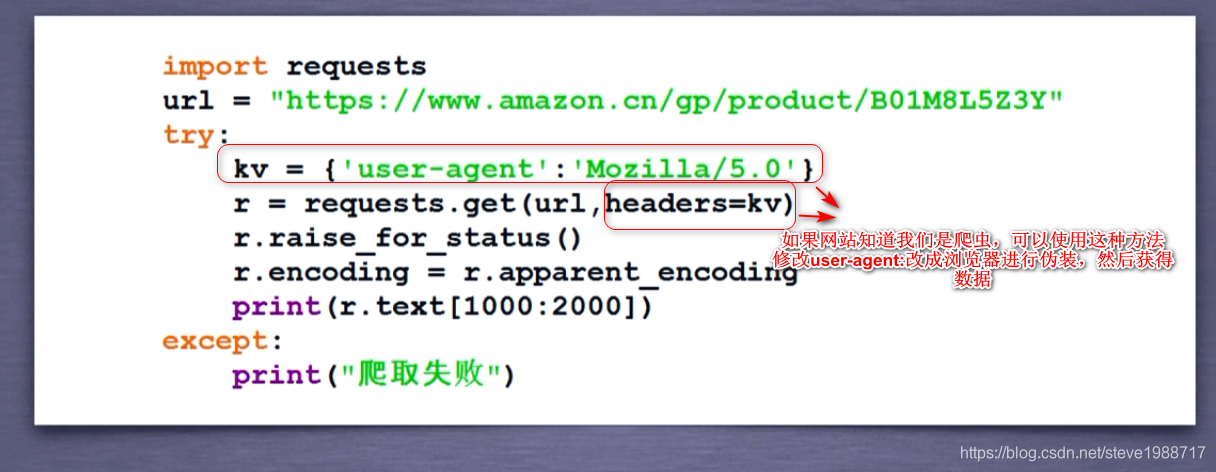
如果服务器知道我们是爬虫,可以通过伪装头部信息,来获取数据
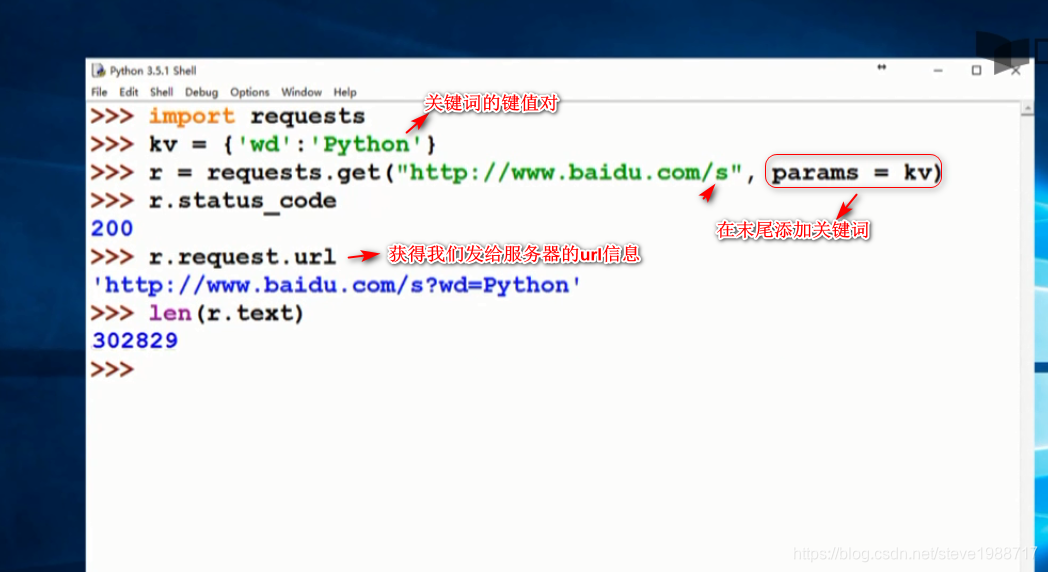
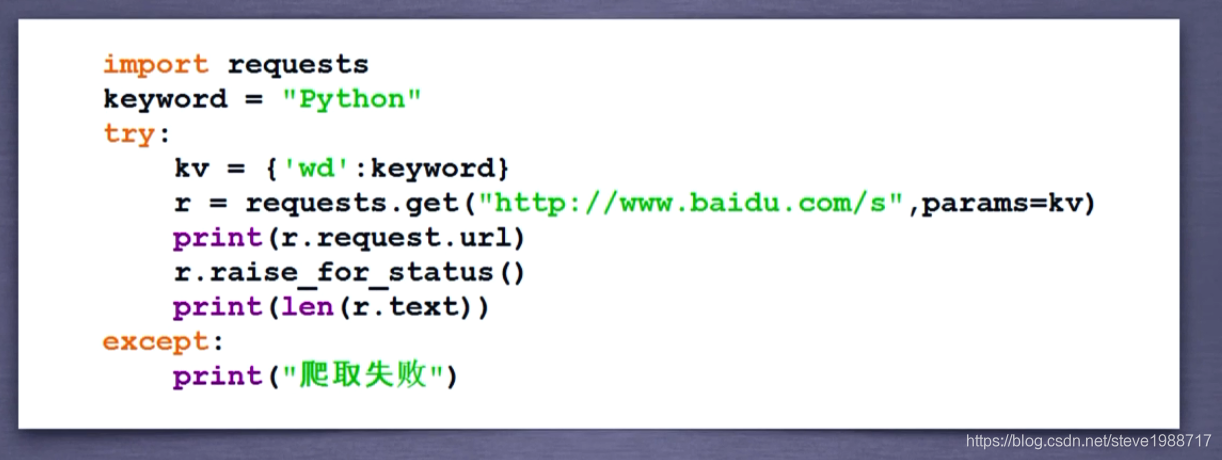
向百度360提交关键词获得搜索结果的方法
1,百度 360都提供了关键词搜索接口

图片爬取代码

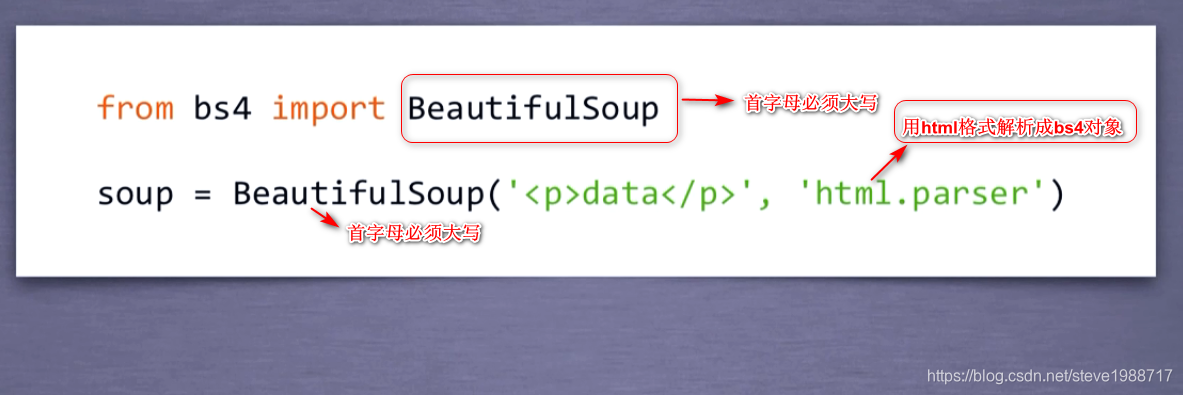
beautifulsoup 介绍

在cmd命令行 输入 pip install beautifulsoup4来安装bs4
然后如下图一样,在模块里面进行引用
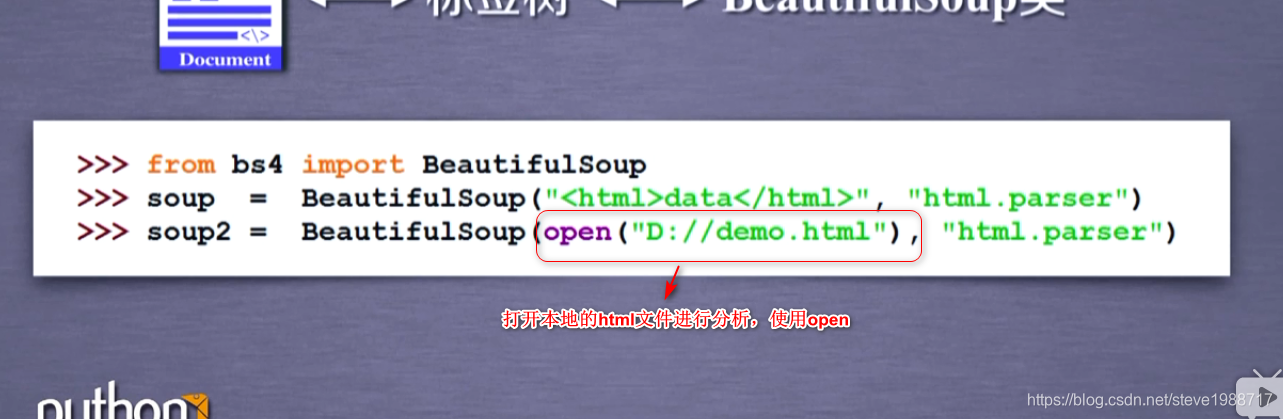

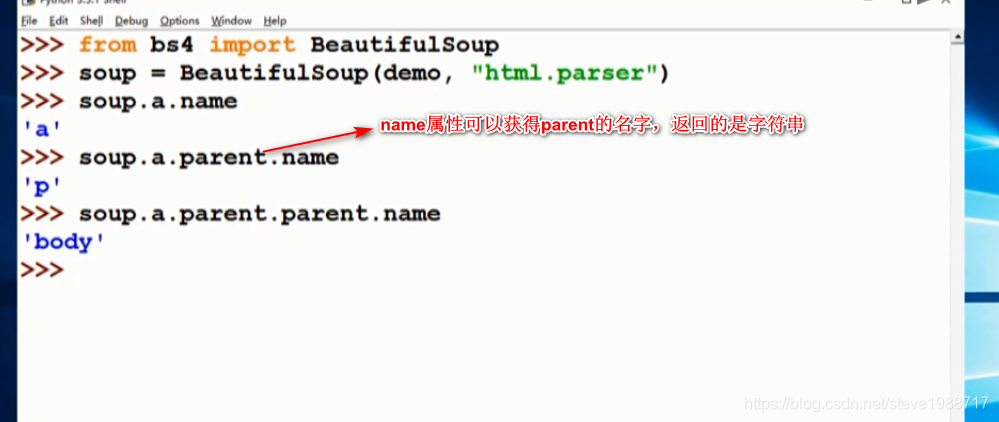





让我们的html显示易读的格式
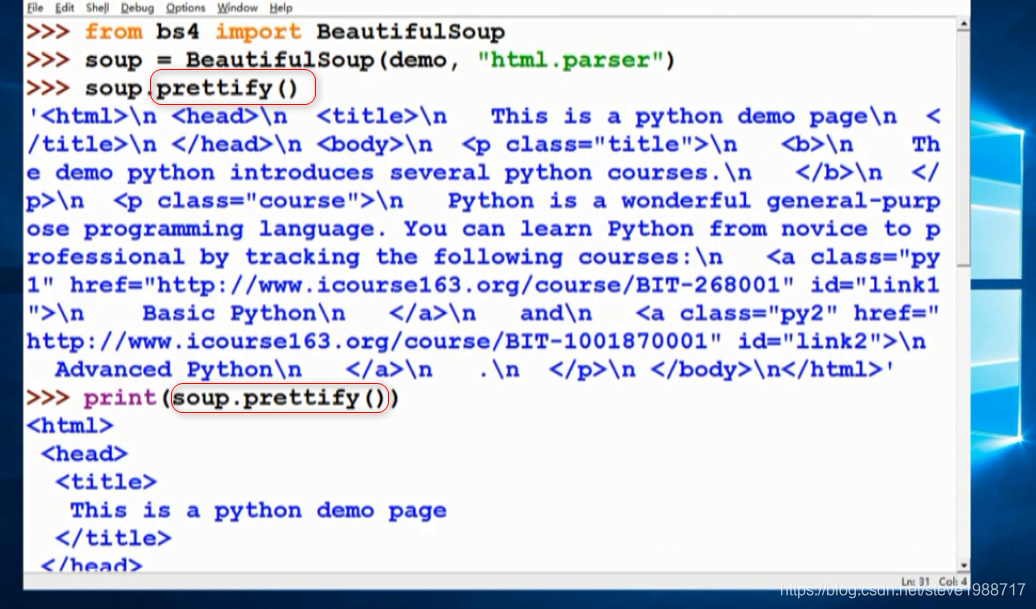
prettify()函数,给html文件标签后面添加换行,当使用print()函数打印时候,显示出来的是标准格式,容易阅读
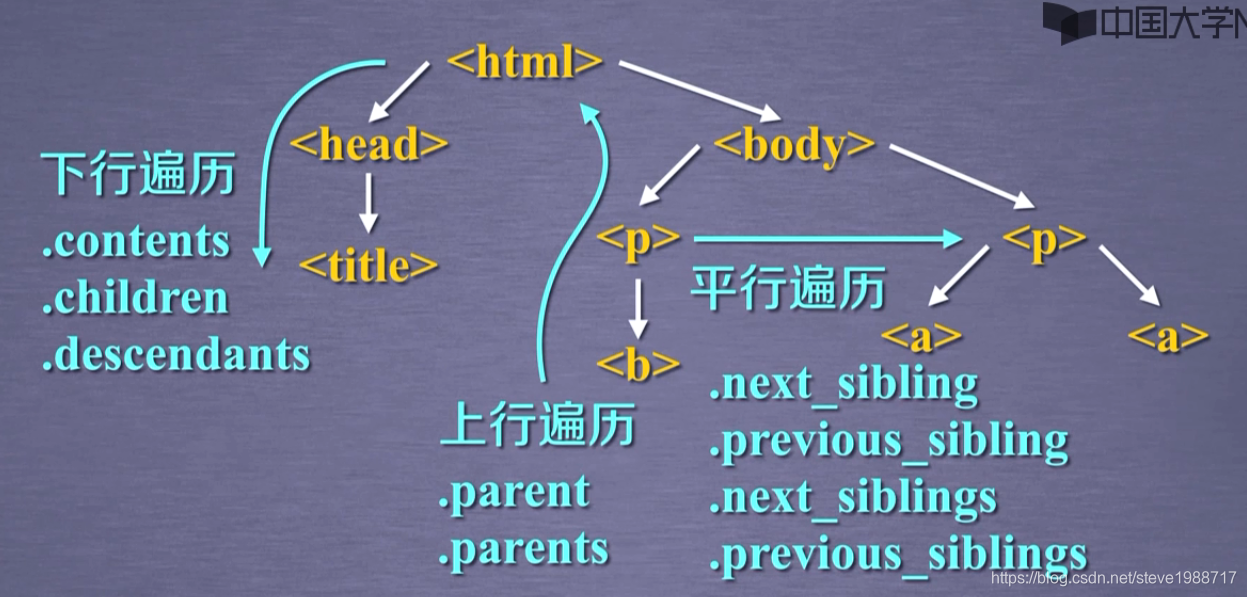
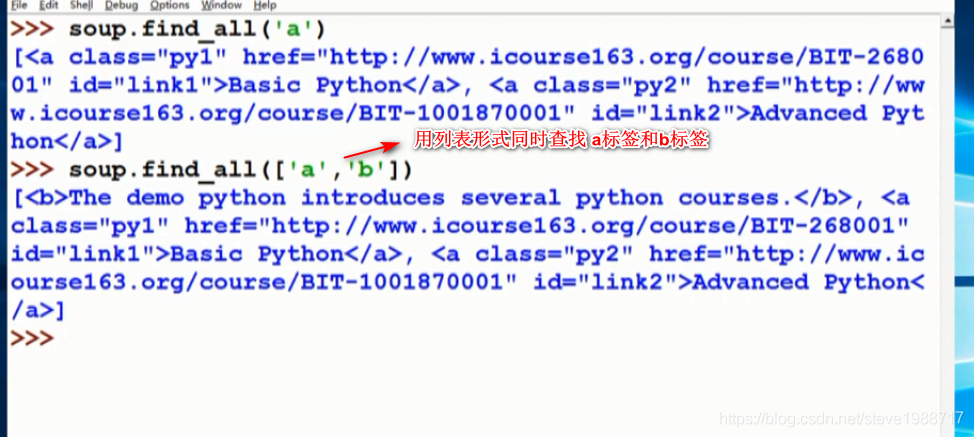
查找html文件中想要查找的内容,使用bs4的 find_all()函数,返回查找的标签列表

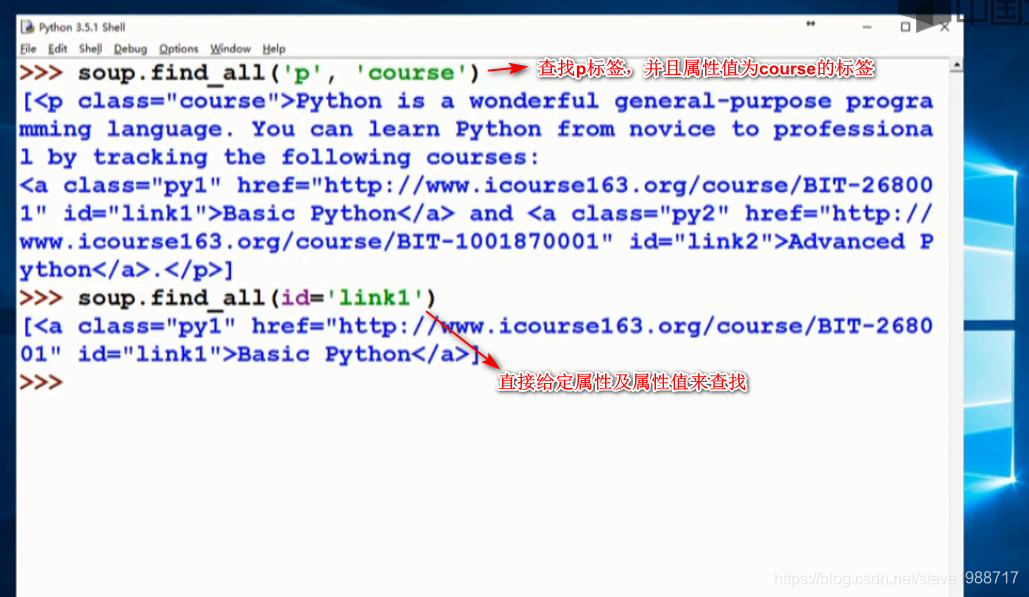
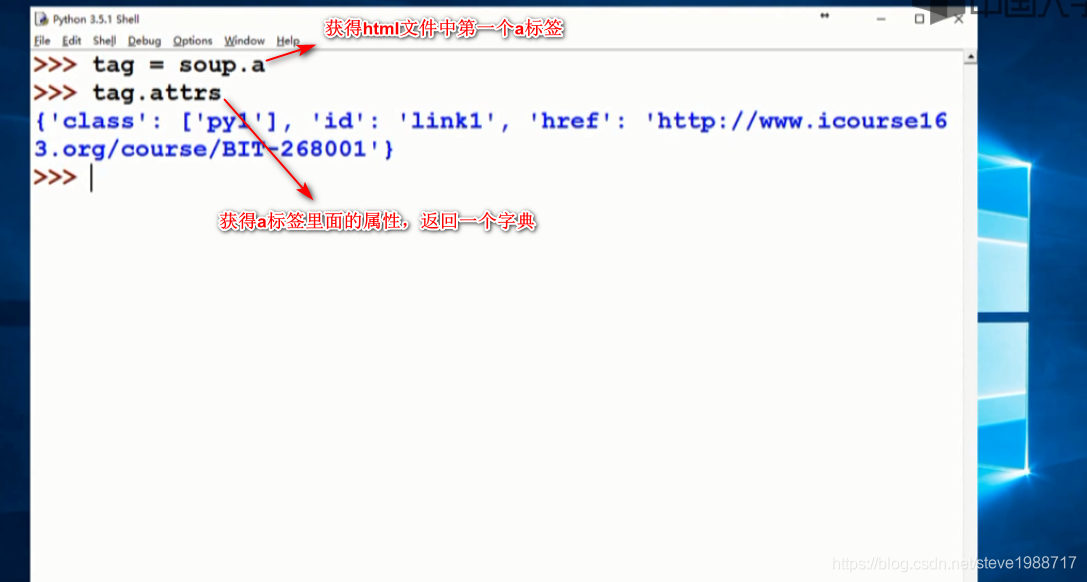
获得标签后,提取里面属性值的方法,使用get() 比如get('href')可以获得对于的url字符串
find_all()函数非常常用,所以出现了简写方式就是比如 soup.find_all()可以简写成 soup()就可以了
select()函数,可以通过选择器进行选择一段标签,css的选择器一般都可以放入里面使用,可以返回一个选中的标签列表
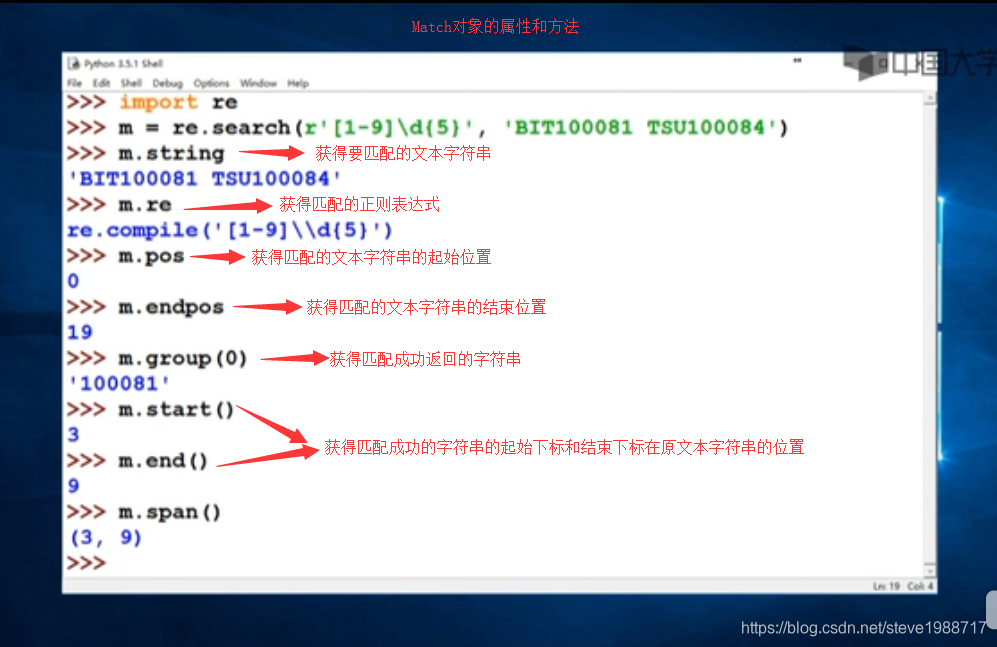
正则表达式
import re
注意:在正则表达式中,出现反斜杠的一般使用原始字符串,比如在字符串前面加r 表示字符串里面的所有字符都是原意





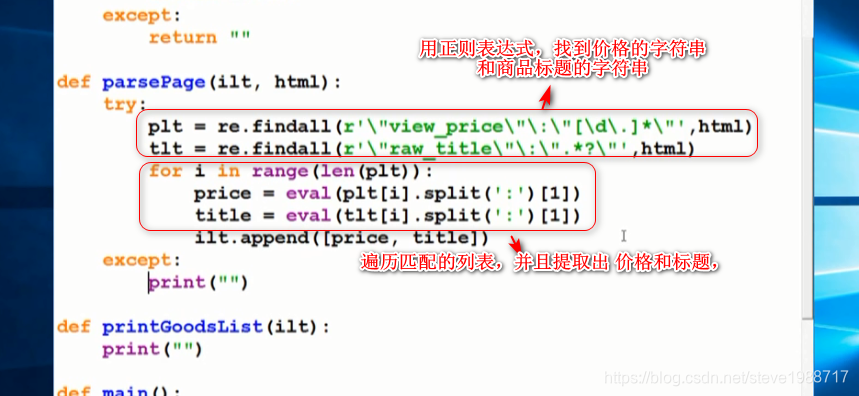
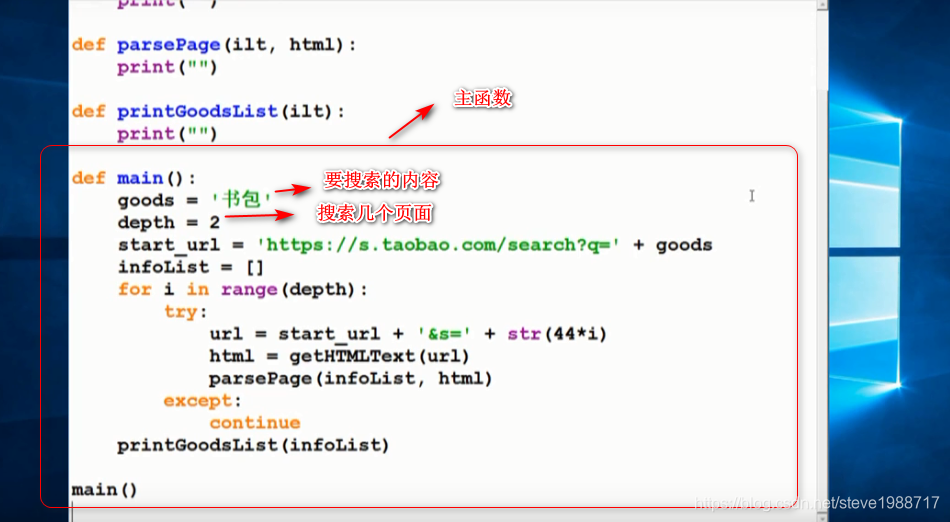
爬取淘宝产品的价格和标题


scrapy框架介绍
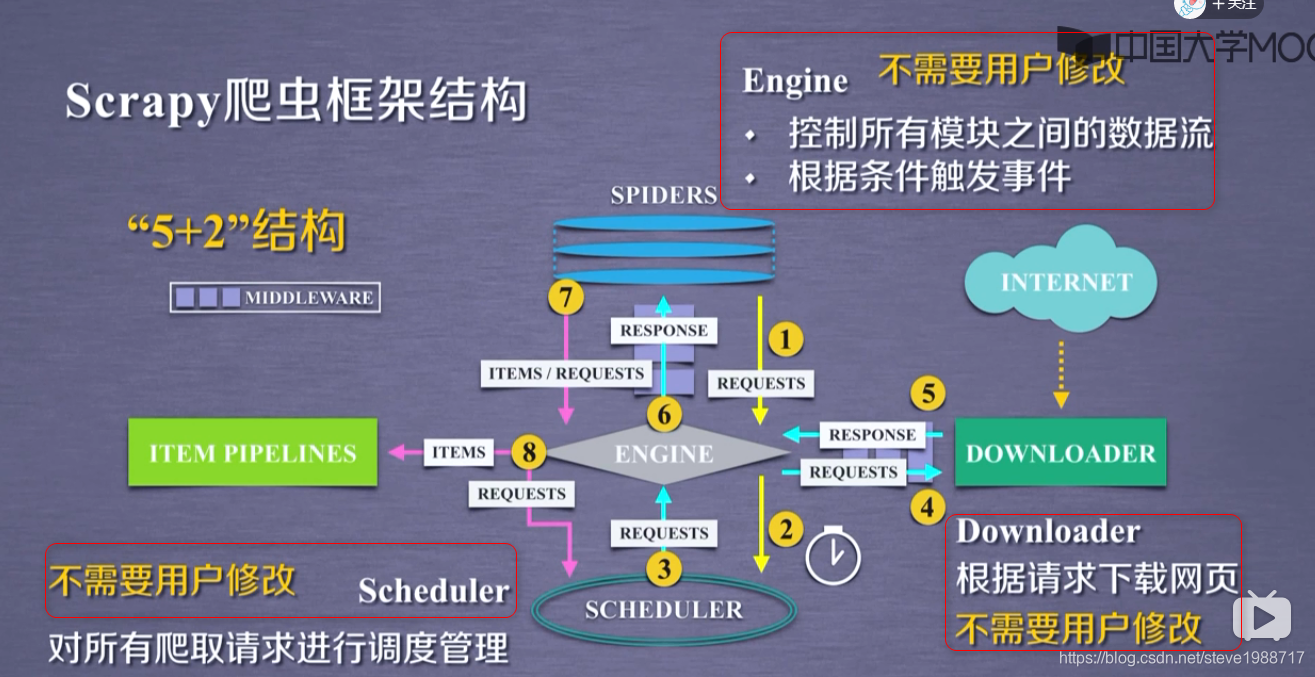
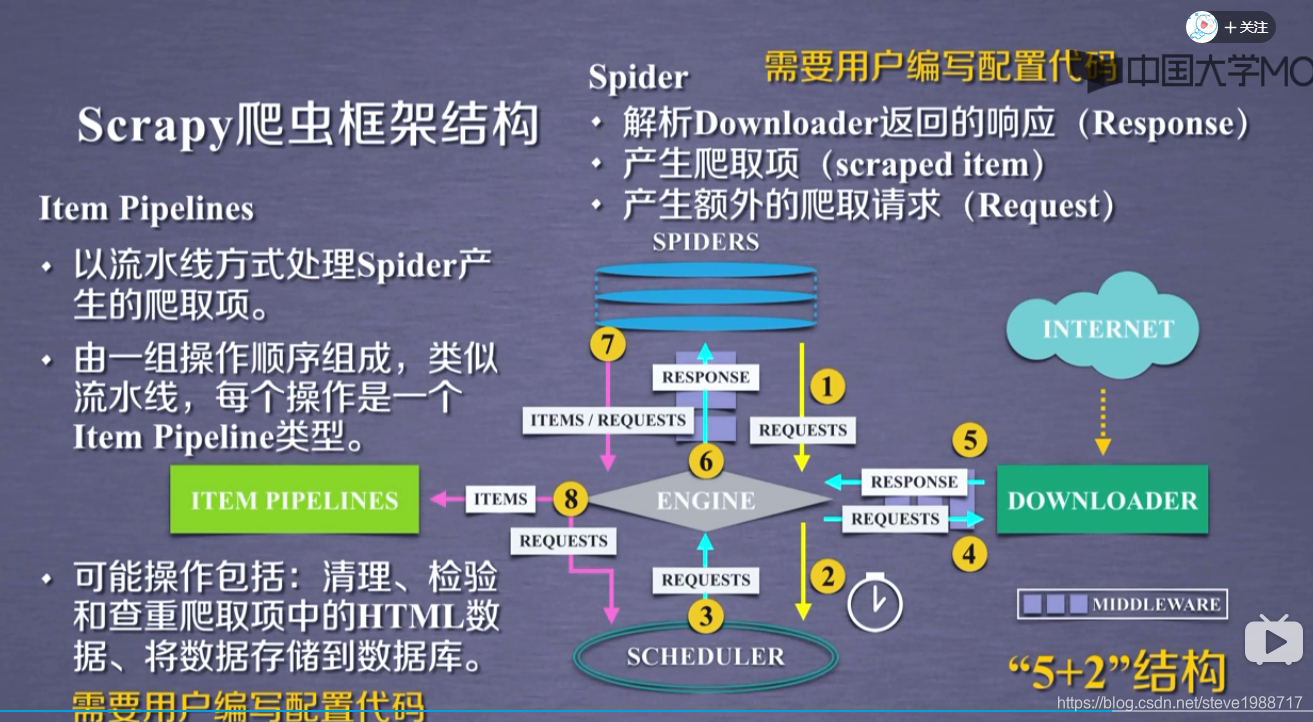

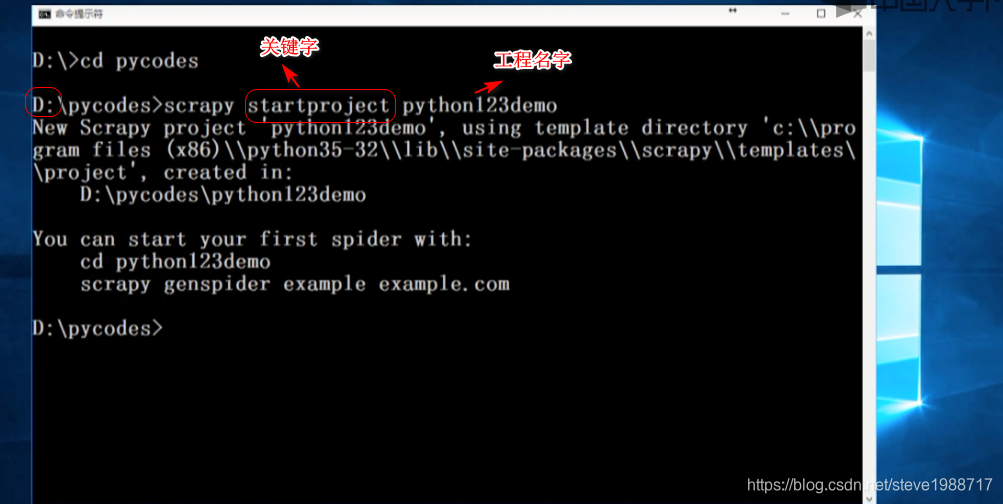
使用scrapy先创建一个工程

会在指定的目录下面生成文件
开发scrap爬虫的步骤


并在stocks.py里面对spiders模块进行编程处理


顺便说一下 生成器
通过列表生成式,我们可以直接创建一个列表。但是,受到内存限制,列表容量肯定是有限的。而且,创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。
如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就不必创建完整的list,从而节省大量的空间。在Python中,这种一边循环一边计算的机制,称为生成器:generator。
就是一个列表,长度只有运行时候才生成
generator和函数的执行流程不一样。函数是顺序执行,遇到return语句或者最后一行函数语句就返回。而变成generator的函数,在每次调用next()的时候执行(或者循环过程中的一次),遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行。


其实是遍历一个列表,但是这个列表是动态生成的,只有执行时,才往里面一个一个的放元素,迭代函数,一般和循环连用

上面的迭代函数,就可以写成这种普通写法
这篇关于python爬虫和信息处理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




