本文主要是介绍python基础查缺补漏,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
模块名=包名+模块名,

IO编程
1,由磁盘或者网络读入到内存里面的过程叫做读入 input ,由内存把数据发送到网络或者写入到磁盘的过程叫做 出 output
2,流相当于水管,但是是单向的,浏览器和服务器如果想写入和写出,需要建立两条水管,即搭建两个流通道
3,在磁盘上读写数据的接口由操作系统提供的,操作系统不允许程序直接更改磁盘数据,程序需要向操作系统申请,操作系统来分配接口,才能操作磁盘上的数据。
f = open('/Users/michael/test.txt', 'r') #这是向操作系统申请一个读文件的操作,通过python内置的open函数,如果找不到文件会抛异常
默认的open读的是utf-8编码的文件,如果不是utf-8编码的文件呢?open函数提供第三个参数,来指明读取文件时的编码
>>> f = open('/Users/michael/gbk.txt', 'r', encoding='gbk')
>>> f.read()f.read() #申请接口成功后,就可以读文件数据了,read()函数一次性把内容都读取了,如果文件很小,可以一次性读取,文件很大,不能一次性读取,而是设置一次读取的大小,然后循环读取,read(1024),或者一行行的读取,readlines() 返回的是list列表,元素是每一行的数据
文件对象接口,由操作系统来分配的,会占用操作系统的资源,所以,用完这个接口,必须关闭
f.close()
每次调用操作文件接口,太繁琐,python提供了自动调用close()的方法,with
with open('/path/to/file', 'r') as f:print(f.read())
这样,就不用自己调用close()函数了
②写文件和读文件是一样的,唯一区别是调用open()函数时,传入标识符’w’或者’wb’表示写文本文件或写二进制文件:
>>> f = open('/Users/michael/test.txt', 'w')
>>> f.write('Hello, world!')
>>> f.close()
你可以反复调用write()来写入文件,但是务必要调用f.close()来关闭文件。当我们写文件时,操作系统往往不会立刻把数据写入磁盘,而是放到内存缓存起来,空闲的时候再慢慢写入。只有调用close()方法时,操作系统才保证把没有写入的数据全部写入磁盘。忘记调用close()的后果是数据可能只写了一部分到磁盘,剩下的丢失了。所以,还是用with语句来得保险:
with open('/Users/michael/test.txt', 'w') as f:f.write('Hello, world!')
要写入特定编码的文本文件,请给open()函数传入encoding参数,将字符串自动转换成指定编码。
细心的童鞋会发现,以’w’模式写入文件时,如果文件已存在,会直接覆盖(相当于删掉后新写入一个文件)。如果我们希望追加到文件末尾怎么办?可以传入’a’以追加(append)模式写入。
>>> f = open('/Users/michael/gbk.txt', 'w', encoding='gbk') #以gbk编码形式写入文件with open('/Users/michael/test.txt', 'a') as f: #a的作用是不用覆盖文件里面已经有的,而是在后面继续写入f.write('Hello, world!')
StringIO和BytesIO
io模块中的类 from io import StringIO
内存中,开辟一个文本模式的buffer,可以像文件对象一样操作它
当close方法被调用的时候,这个buffer会被释放
>>> from io import StringIO
>>> sio = StringIO() # 这是在内存中开辟一个空间,像文件对象一样操作
#下面是写入数据,返回值是写入了几个字符
>>> sio.write("hello,world!")
12
#是读取一行
>>> sio.readline()
'hello,world!'
>>> sio.getvalue() # 无视指针,输出全部内容
'hello,world!'
>>> sio.close()
一般来说,磁盘的操作比内存的操作要慢得多,内存足够的情况下,一般的优化思路是少落地,减少磁盘IO的过程,可以大大提高程序的运行效率
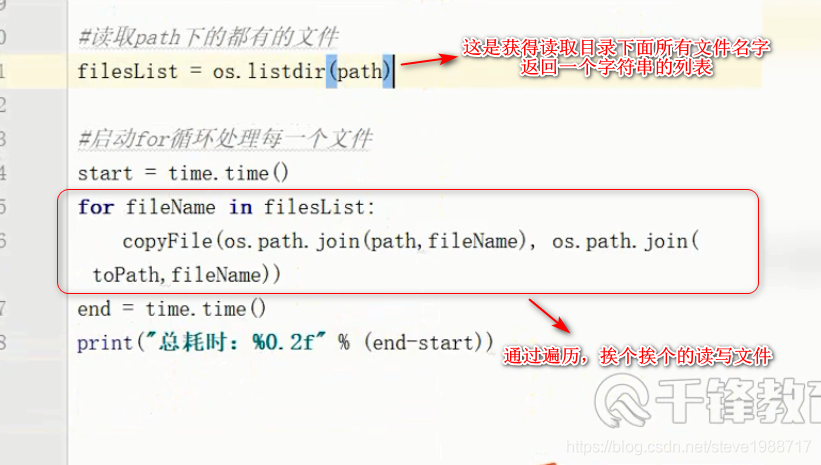
1,得到一个文件夹内所有的文件和文件夹的名字,并且返回一个列表,使用os.listdir(文件夹的路径)
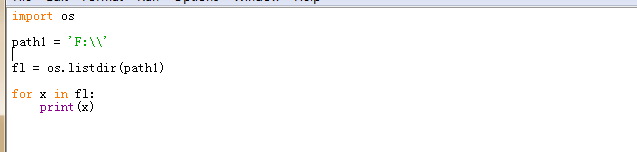
2,把两个路径合成一个时,不要直接拼字符串,而要通过os.path.join()函数,这样可以正确处理不同操作系统的路径分隔符。

上图其实就是路径字符串的拼接

上图其实是路径字符串的拆分
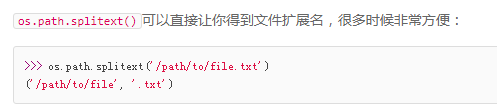
上图甚至还可以把一个路径字符串的扩展名拆分出来
注意:这些合并、拆分路径的函数并不要求目录和文件要真实存在,它们只对字符串进行操作。
上面是拼接的目录字符串,下面拿到拼接好的目录字符串,创建一个真正的目录了
# 然后创建一个目录:
>>> os.mkdir('/Users/michael/testdir')
# 删掉一个目录:
>>> os.rmdir('/Users/michael/testdir')
进程和线程
对于操作系统来说,一个任务就是一个进程(Process),比如打开一个浏览器就是启动一个浏览器进程,打开一个记事本就启动了一个记事本进程,打开两个记事本就启动了两个记事本进程,打开一个Word就启动了一个Word进程。
有些进程还不止同时干一件事,比如Word,它可以同时进行打字、拼写检查、打印等事情。在一个进程内部,要同时干多件事,就需要同时运行多个“子任务”,我们把进程内的这些“子任务”称为线程(Thread)。
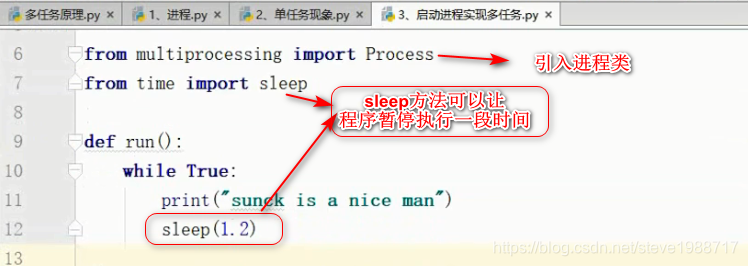
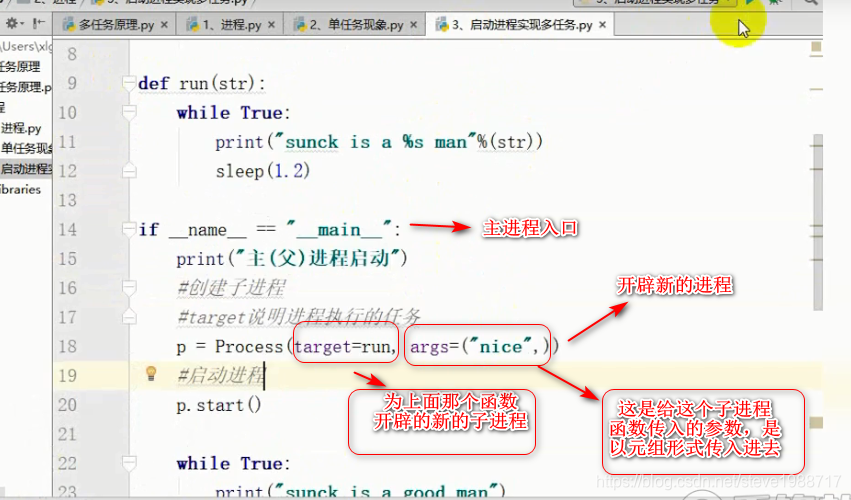
创建进程以后,通过.start()方法启动进程,子进程不会影响下面主进程的执行
子进程和父进程互相一般不影响,有时主进程结束了,子进程还在执行。那么我们想等子进程结束以后,父进程才结束怎么办?可以让子进程对象调用join()函数,这样主进程最后才结束,因为开发程序时候,主进程不做什么,都是开了多个子进程让他们工作,所有子进程结束以后,主进程结束,
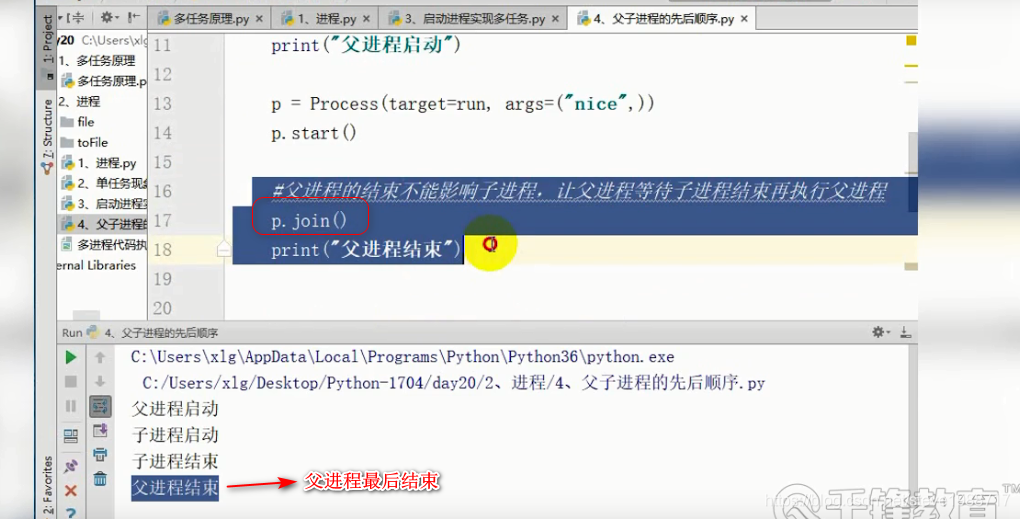
1,各进程之间,不能共用全局变量;当子进程创建时候,会复制一个全局变量作为自己的变量,在自己的进程函数内改变变量的值,不会影响其他进程内变量的值(不同进程不能共享全局变量)
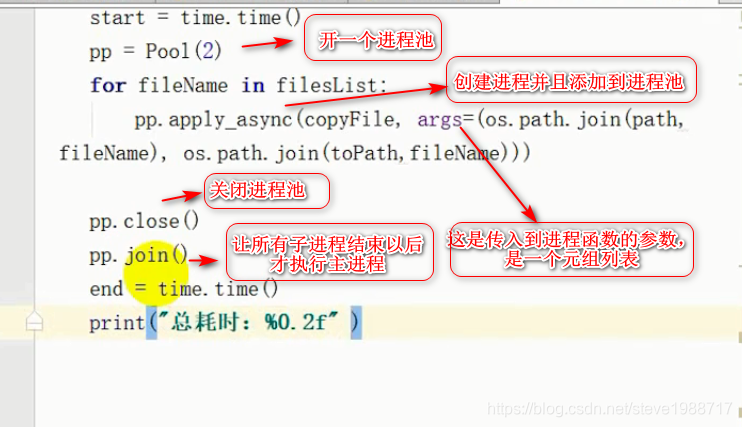
2,当我们创建很多个进程时候,不应该再用p = process(target=run)来一个个创建了,我们可以使用进程池,来创建多个进程,便于管理
首先引入进程池 from multiprocessing import pool
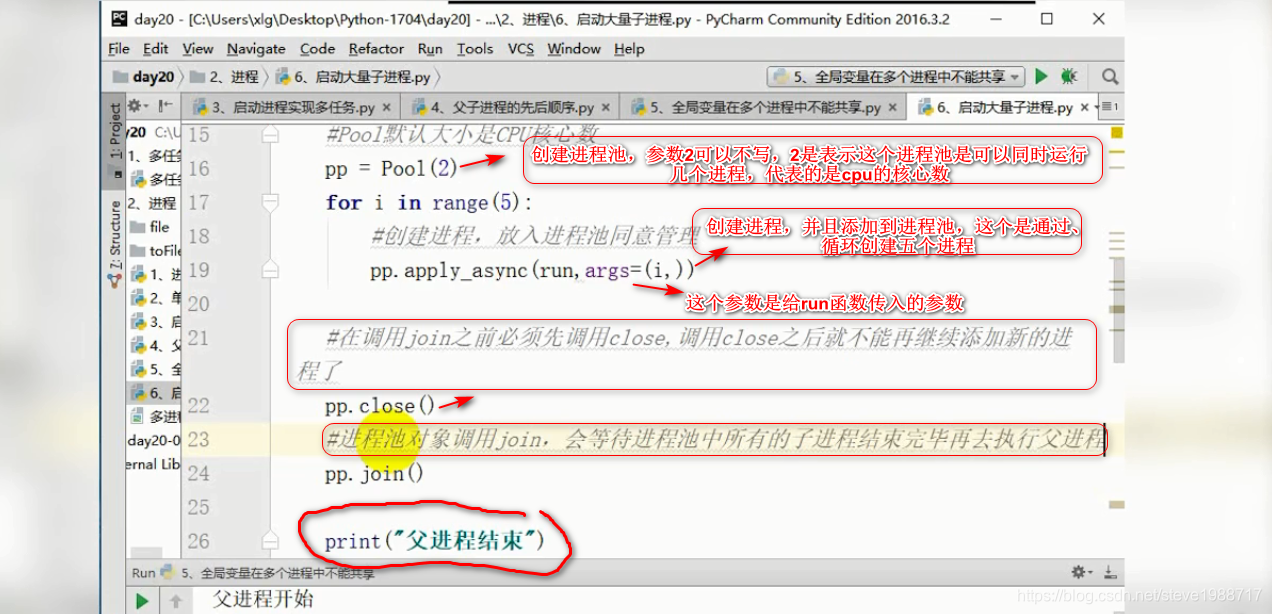
上图,循环创建的五个进程,都是执行的相同的run函数,如果想每个进程执行不同的函数,可以不用写循环的,
练习,复制一个文件夹下面所有文件到另一个文件夹下(一般写法)
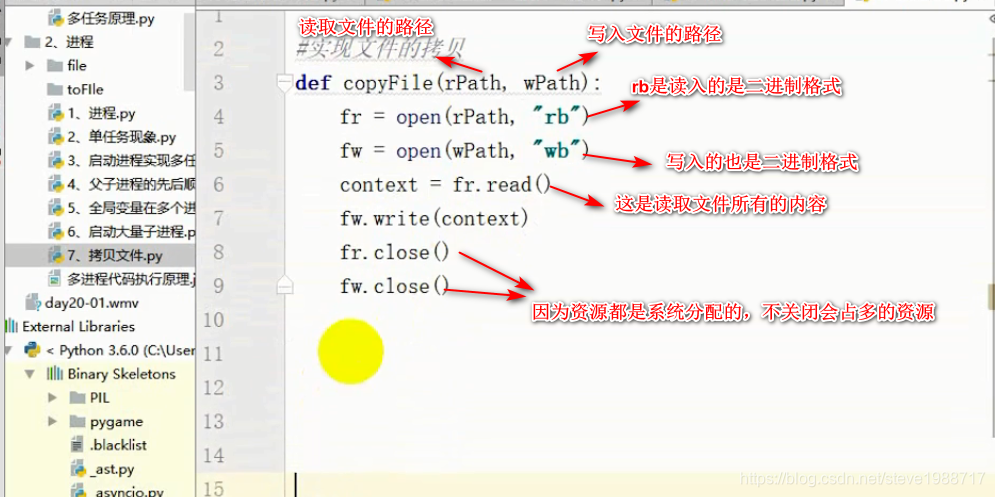
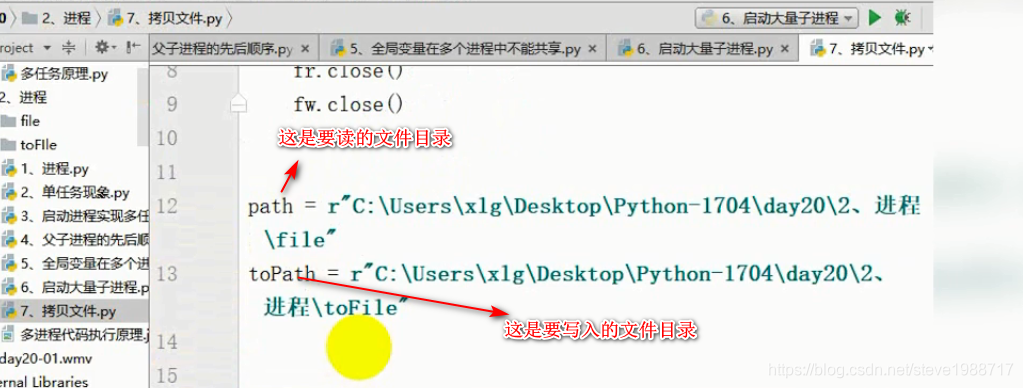
而多进程的写法如下图
线程
一个进程至少有一个线程,线程没有自己的独立空间,所有线程之间,共享一个变量,而进程有自己的独立空间,各进程之间不共享变量(只要启动一个进程,就会默认启动一个线程)
网络编程
TCP/ip协议
ip协议就是每一台电脑都有唯一的ip, 路由器把IP包给转发出去,IP包按一块块的发送,途径哪个路线哪个路由器不一定,不能保证到达,也不能保证按顺序到达
TCP协议,就是给每一个ip包编号,让他们按顺序到达,如果丢失了某个IP包,会自动重新发送
端口
在两台计算机通信时,只发IP地址是不够的,因为同一台计算机上跑着多个网络程序。一个TCP报文来了之后,到底是交给浏览器还是QQ,就需要端口号来区分。每个网络程序都向操作系统申请唯一的端口号,这样,两个进程在两台计算机之间建立网络连接就需要各自的IP地址和各自的端口号
这篇关于python基础查缺补漏的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





