本文主要是介绍数据集标注工具anylabeling解析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近帮助其他课题组的学姐标注数据集,课题组使用的是anylabeling软件,相比于其他数据标注软件,例如labelme等,anylabeling软件使用时可以选择不同的模型,可以做到在图片上点几个点的轮廓,模型将自动识别出大致轮廓,可以大大节省时间,提高效率。
视频教程:https://www.bilibili.com/video/BV1mN411C7SC/?spm_id_from=333.788.recommend_more_video.1&vd_source=a37ca5b14367044bc8b8c9408ba13218
软件使用概述:
1.软件下载
代码和模型的下载都需要链接github,如果没有梯子可能速度太慢,下载不了模型,可以直接创建一个文件夹【路径不含有中文】存放anylabeling.exe,然后将medels文件夹复制到:C:\Users\用户名\anylabeling_data文件夹下,打开anylabeling.exe,选择工作文件夹,模型选择时选:segment anything(vit-l)【提供的models文件夹内指下载了该模型,因此如果用提供的models文件夹只能选用这个模型,别的模型需要另外下载。
网盘:
链接:https://pan.baidu.com/s/1TxqM0E-PIJC-w3VcaFqMPw?pwd=gtvv
提取码:gtvv
–来自百度网盘超级会员V5的分享
有特殊情况or想自己配置
1、创建一个文件夹anylabel放软件(路径不要有中文)
建议到网页安装软件 有gpu选择AnyLabeling-GPU.exe
pip install 可能失败
https://github.com/vietanhdev/anylabeling/releases
2、启动软件点击Auto-Labeling,选择模型,会自动下载到C:\Users\用户名\anylabeling_data下【此步骤如果出现闪退状况很可能是因为没有梯子】
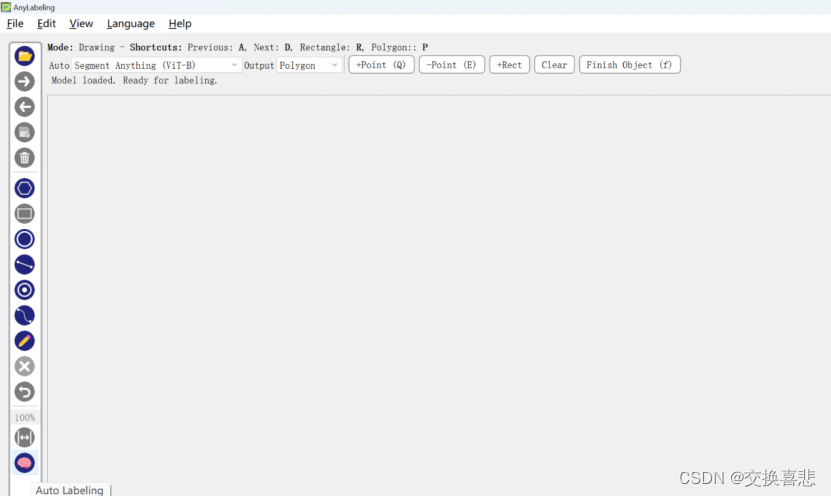
软件的具体使用方法可以参考上面的视频教程,讲述的比较详细,下面mark一些常用快捷键:
A D :上一张 下一张
Ctrl+滚轮:放大缩小
f:保存并打标签名
backspace:删除多边形边框的点
标注生成的是json格式的文件,提供一个脚本来整合json文件和原图,结果是全黑的,如果想要查看标注结果,可以将代码中的注释放入代码中,标注的类别等信息可以根据自身的情况更改:
'''
把Anylabeling标注得到的json文件
转化成mask灰度图用于语义分割
0-背景 1-5类别:砖块brick,金属metal,石头stone,塑料plastic,木头wood
'''
import json
import argparse
import os
import os.path as osp
import warnings
import numpy as np
import PIL.Image
import yaml
from labelme import utils
import cv2
# 显示彩色的分割结果
# def show_img(img_gray):
# img_show = np.zeros((height, width, 3), np.uint8)
# for i in range(height):
# for j in range(width):
# if(img_gray[i, j] == 1):
# img_show[i, j, 0] = 255
# img_show[i, j, 1] = 0
# img_show[i, j, 2] = 0
# elif(img_gray[i, j] == 2):
# img_show[i, j, 0] = 0
# img_show[i, j, 1] = 255
# img_show[i, j, 2] = 0
# elif(img_gray[i, j] == 3):
# img_show[i, j, 0] = 255
# img_show[i, j, 1] = 255
# img_show[i, j, 2] = 0
# elif(img_gray[i, j] == 4):
# img_show[i, j, 0] = 0
# img_show[i, j, 1] = 0
# img_show[i, j, 2] = 255
# cv2.imshow('1', img_show)
# cv2.waitKey()if __name__ == '__main__':# 类别对应labelname_to_label = {'Metal': 1, 'Plastic': 2, 'Stone': 3, 'Wood': 4,'stone':5}# 保存json的文件夹json_file_path = 'D:/datalabel/8'# 保存label图片的文件夹save_path = 'D:/datalabel/'list = os.listdir(json_file_path)for json_file in list:print(json_file)if(os.path.basename(json_file.split('.')[1]) != 'json'):print('文件{}不是json文件,跳过'.format(json_file))continue# print(json_file)img_name = json_file.split('.')[0]+'.png'file_path = os.path.join(json_file_path, json_file)# 打开每个json文件遍历with open(file_path, 'r', encoding='utf8') as fp:data = json.load(fp)height = data['imageHeight']width = data['imageWidth']lbl, lbl_names = utils.shapes_to_label((height, width), data['shapes'], name_to_label)# 显示彩色分割图# show_img(lbl)cv2.imwrite(save_path+img_name, lbl)这篇关于数据集标注工具anylabeling解析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





