本文主要是介绍A Combination of RNN and CNN for Attention-based Relation Classification论文阅读笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要
关系分类在自然语言处理(NLP)领域中起着重要作用。先前有关关系分类的研究已经证明了使用卷积神经网络(CNN)和递归神经网络(RNN)的有效性。在本文中,我们提出了一个结合RNN和CNN的模型(RCNN),这将充分发挥它们各自的优势:RNN可以学习时间和上下文特征,尤其是两个实体之间的长期依赖性,而CNN可以捕捉更多潜在功能。我们在SemEval-2010 Task 8数据集1上进行了实验,结果表明我们的方法优于大多数现有方法。
1、Introduction
关系分类的任务是提取两个实体之间的语义关系。通常,该任务仅考虑两个实体的关系。因此,任务的输入是带有已注释的成对实体的句子。而输出是两个实体之间的关系。例如,以下面的句子为例。
The <e1> deficits </e1> are caused by <e2> people </e2> saving too much of their money.
<e1>和<e2>是Cause-Effect的关系
传统方法的弊端:
传统的基于词汇资源手动特征的分类方法通常利用模式匹配,难以实现高性能。
这些方法的缺点是,许多传统的NLP系统(如命名实体,词性标签和最短依赖路径)用于提取高级特征,从而导致计算成本增加和附加的累积错误。
另一个缺点是手动设计功能很耗时,并且由于训练数据集的覆盖率较低,因此泛化性能很差。
做的工作:
本文提出了一种新的名为RCNN的关系分类模型。我们的模型首先将输入句子映射到低维向量。然后,我们利用双向长期短期记忆网络(BLSTM)来捕获句子中单词的上下文和时间特征。另一方面,在BLSTM之后,我们使用CNN捕获更多功能。结果,CNN的输入就是BLSTM的输出。该模型仅利用NLTK工具获得的POS标签功能。
2、模型

图1-网络结构
模型主要由六个部分组成。
-
输入层:原始输入。有些句子包含标记的实体。
-
嵌入层:将句子映射到低维向量,主要由单词嵌入,位置嵌入和POS标签嵌入组成。
-
LSTM层:使用LSTM获得包含时间和上下文信息的高级功能。
-
注意层:通过乘以权重向量来注意不同的单词。
-
卷积层:在关注层之后,将词级特征向量馈入CNN中,以获得更丰富的特征。
-
完全连接的层和softmax层:遍历各层之后,我们可以从结果中确定最终关系
2.1输入表示
模型的输入是句子的原始单词。在嵌入层中,将句子映射到低维向量。我们利用三个通道来表示向量,它们分别是单词,位置和POS标签。
2.1.1词嵌入。词嵌入的目的是将词转换为低维且密集的向量。对于两个相似的词,它们对应的词向量也相似。因此,词向量技术可以捕获词的句法和语义信息。给定一个由m个单词组成的句子x:x={w1,w2...,wm},每个词wi由实值向量表示。然后将句子映射到嵌入矩阵![]() ,其中V是固定大小的词汇表,长度是词汇表的大小。
,其中V是固定大小的词汇表,长度是词汇表的大小。
至于如何生成单词嵌入,我们首先使用Word2Vec2在大型Wiki语料库中训练了单词嵌入。保留它们的权重和参数,然后我们继续在训练和测试数据集上对嵌入进行训练,以得到最终的嵌入。
2.1.2位置嵌入。定位嵌入旨在告诉我们这对实体的确切位置。以下面的相同句子为例:
The <e1> deficits </e1> are caused by <e2> people </e2> saving too much of their money.
我们定义了两个位置嵌入,因为有两个实体。假设实体的位置为0。
以嵌入的第一个位置为例,字缺陷的位置为0。前面的单词是-1、-2...,后面的单词是1,2,..,其余单词可以相同的方式进行。然后,我们将这些数字映射到一个低维向量中,本文将其维数设置为10。
2.2双向LSTM(BLSTM)网络
作为序列化,句子被视为LSTM网络中单词的有序序列。但是,在大多数情况下,相反的顺序可能会对结果有很大帮助。为了充分考虑句子的有序性和单词之间的相关性,提出了双向LSTM来解决此问题。 Tang等人4提出了一种基于LSTM的语义关系分类学习模型,发现BLSTM比LSTM可以发现更丰富的语义信息并充分利用上下文信息。 Zhou等人5利用BLSTM从单词嵌入中获得了高级语义信息特征,并完成了句子级关系分类。
LSTM是一种特殊的递归神经网络。 LSTM单元由一个单元和三个门(输入,输出和遗忘)组成。通过这种特殊的结构,LSTM可以选择忘记或记住哪些信息。在时间t,LSTM单元组件更新如下:

![]()
RNN结构:


LSTM:

其中σ代表sigmoid形激活函数;![]() 代表element-wise multiplication(逐元素乘法);x是时间t的输入向量;ht代表隐藏状态;Wxi Wxf Wxc Wxo分别是Xt不同门的权重矩阵;Whi Whf Whc Who是ht不同门的权重矩阵;bi bf bc bo是每个栅极的偏置偏移。it ft ct ot分别代表输入门,遗忘门,存储单元状态和输出门。
代表element-wise multiplication(逐元素乘法);x是时间t的输入向量;ht代表隐藏状态;Wxi Wxf Wxc Wxo分别是Xt不同门的权重矩阵;Whi Whf Whc Who是ht不同门的权重矩阵;bi bf bc bo是每个栅极的偏置偏移。it ft ct ot分别代表输入门,遗忘门,存储单元状态和输出门。
从图1中的LSTM模型的结构可以看出,序列信息从前向后传播。单向机制仅包含序列中当前单词的先前信息,但是不涵盖以后的信息。基于此,BLSTM解决了这个问题。BLSTM在隐藏层中具有正LSTM和反向LSTM。 LSTM捕获上述特征信息,而反向LSTM捕获以下特征信息。然后,我们通过使用逐元素求和来组合前向和后向特征。
![]()
2.3 Attention
注意机制的目的是让模型知道在训练过程中输入数据的哪一部分是重要的,以便模型密切关注信息。
我们从LSTM层获得T hi。在这里,我们将它们放在一起,得到矩阵H:
![]()
其中T是输入句子的长度。然后,我们通过将加权值 i 乘以每个hi来获得Mr
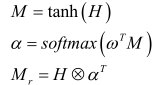
在这里,![]() 是LSTM单位隐藏数的维数,
是LSTM单位隐藏数的维数,![]() 是要训练的参数向量,
是要训练的参数向量,![]() 是其转置。
是其转置。![]() 的维度分别是
的维度分别是![]() 。最后,我们得到矩阵Mr,其形状为
。最后,我们得到矩阵Mr,其形状为![]()
2.4 卷积神经网络
构建部分连接的神经网络,每个神经元不再与上层所有神经元相连,而是连接某部分。另外还能通过权值共享来减少参数数量,一组连接共享权重而不必每个连接权重都不同。除此之外,还能通过池化来减少每层的样本数,从而减少参数数量。结合以上特点,卷积神经网络就是这样的一种网络。
看一个卷积神经网络示意图,它包含了若干卷积层、池化层和全连接层。
2.5辍学策略和二级监管
深度神经网络的一个问题是,由于参数众多,它们很容易过拟合。在本文中,我们使用辍学和l2正则化来减少训练过程中的过拟合。本节主要介绍辍学策略。
辍学策略最早由Srivastava提出。它在训练过程中会随机省略网络中的特征检测器,并且可以获得更少的相互依赖的网络元素,以实现更好的性能。

辍学层定义如下。
![]()
其中r是与x共享相同形状的矩阵。 r的每个元素在概率为p时为0,在概率为1-p时为1。
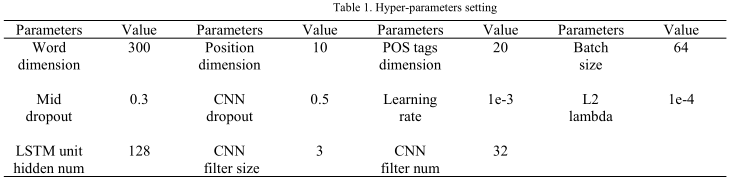
我们在嵌入层,LSTM层,中间层和输出层上设置辍学层。它们的概率p分别为0.3、0.3、0.3、0.5
通常,正则化方法可以防止过度拟合以提高泛化能力。我们只是在成本函数中添加了L2规则。成本函数是带有真实类别标签 ti 的负对数似然函数。
其中是L2正则化超参数。
(注:Dropout可以作为训练深度神经网络的一种trick供选择。在每个训练批次中,通过忽略一半的特征检测器(让一半的隐层节点值为0),可以明显地减少过拟合现象。这种方式可以减少特征检测器(隐层节点)间的相互作用,检测器相互作用是指某些检测器依赖其他检测器才能发挥作用。
Dropout说的简单一点就是:我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征,如图1所示。
2.1 Dropout具体工作流程
假设我们要训练这样一个神经网络,如图2所示。
图2:标准的神经网络
输入是x输出是y,正常的流程是:我们首先把x通过网络前向传播,然后把误差反向传播以决定如何更新参数让网络进行学习。使用Dropout之后,过程变成如下:
(1)首先随机(临时)删掉网络中一半的隐藏神经元,输入输出神经元保持不变(图3中虚线为部分临时被删除的神经元)
图3:部分临时被删除的神经元
(2) 然后把输入x通过修改后的网络前向传播,然后把得到的损失结果通过修改的网络反向传播。一小批训练样本执行完这个过程后,在没有被删除的神经元上按照随机梯度下降法更新对应的参数(w,b)。
(3)然后继续重复这一过程:
. 恢复被删掉的神经元(此时被删除的神经元保持原样,而没有被删除的神经元已经有所更新)
. 从隐藏层神经元中随机选择一个一半大小的子集临时删除掉(备份被删除神经元的参数)。
. 对一小批训练样本,先前向传播然后反向传播损失并根据随机梯度下降法更新参数(w,b) (没有被删除的那一部分参数得到更新,删除的神经元参数保持被删除前的结果)。
不断重复这一过程。)
https://blog.csdn.net/zouxy09/article/details/24971995(L2范数规则化)
3、Expement
数据集和评估指标
为了评估建议的RCNN模型,使用SemEval-2010 Task8公共数据集16进行了实验,该数据集近年来已广泛用作标准数据集。它包含十种类型的关系,其中九种具有方向,例如以下两个语句
S1: The <e1>battery</e1> of the <e2>mobile phone</e2> is made in China.
S2: <e1>Human</e1> has two <e2>eyes</e2>.
S1和S2中两个实体e1和e2之间的关系类型是组件整体关系。但是,由于e1和e2包含不同的方向,因此无法将这两个句子归为同一类别。此外,它包含一个无向的Other类,这意味着两个实体之间没有关系。因此共有19个类别。
数据集包含10717个带注释的示例,包括8000个句子用于训练,2717个用于测试。每个句子都有两个标记的实体及其关系。数据集提供了官方评估指标来评估系统。我们评估关系类别中每个类别的F1得分,并根据宏观平均F1得分(不包括其他关联类别)对它们进行平均。
超参数设置:表1显示了超参数的设置。
实验结果
表2显示了将我们的RCNN模型与其他有关关系分类任务的最新方法进行比较。该实验由著名的深度学习工具TensorFlow实施,TensorFlow是使用数据流图进行数值计算的开源软件库。我们提出的RCNN模型的F1分数达到83.7%。它仅使用POS标签就优于大多数现有竞争方法。但是,当不使用任何语义特征时,该模型的性能最佳。
4. Conclution
本文提出了一种在网络结构中结合RNN和CNN的模型RCNN进行关系分类。该模型继承了它们各自的优势。它不仅可以解决RNN长期依赖的问题,而且可以利用CNN提取更多丰富的功能。我们通过评估SemEval-2010关系分类任务中的模型证明了其有效性
参考
https://blog.csdn.net/wangyangzhizhou/article/details/76651116
https://blog.csdn.net/program_developer/article/details/80737724
https://blog.csdn.net/wangyangzhizhou/article/details/76034219
这篇关于A Combination of RNN and CNN for Attention-based Relation Classification论文阅读笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








