本文主要是介绍2021年IBM数据泄露成本报告:平均成本破纪录,达到424万美元,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
| 导读 | 由 IBM Security赞助、由 Ponemon Institute 进行分析的年度数据泄露成本报告已经到了第十七个年头。该报告在帮助组织了解和应对安全风险方面发挥着重要作用。 |
网络安全正变得比过往的任何时刻都重要,尤其是在这种专注于疫苗制造和病毒研究的特殊时期。最新的数据泄露成本报告显示,安全成本仍然在不断上升,这使得预防和对应网络威胁成为关键问题。

由 IBM Security赞助、由 Ponemon Institute 进行分析的年度数据泄露成本报告已经到了第十七个年头。该报告在帮助组织了解和应对安全风险方面发挥着重要作用。今年的报告研究了影响数据泄露成本的数十个因素,包括数百万员工远程登录访问数据和应用程序带来的影响。
就如同去年报告中预测的那样,数据泄露成本创下历史新高。由于疫情大流行导致的远程工作导致数据泄露的成本迅速上升,而且控制数据泄露所需的时间也变得越来越长。一些典型的数据如下所示:
- 数据泄露成本最高的国家是美国,可达到 905 万美元
- 数据泄露成本最高的行业是医疗,可达到 923 万美元
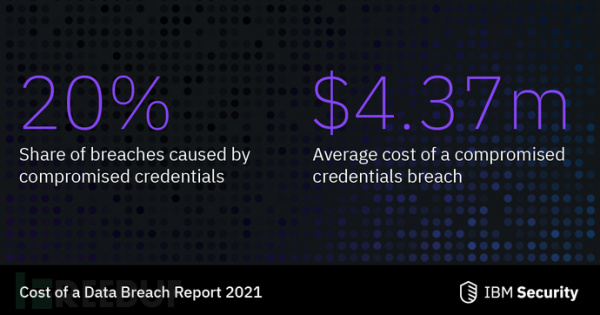
- 最常见的攻击向量是:凭据泄露(20%)、网络钓鱼(17%)和云配置错误(15%)
- 泄露数据在 5000 万到 6500 万条的泄露事件成本可达到 4 亿美元以上
- 最贵的个人记录可以卖到 180 美元/条
数据泄露成本
2021 年,数据泄露的平均成本增长了近 10%,达到了创纪录的 424 万美元。当远程工作被认为是导致数据泄露的一个因素时,数据泄露的平均成本会进一步上升到 496 万美元。
远程办公也影响了响应处置速度,控制数据泄露花费的时间越来越长。在远程工作超过 50% 的组织中,平均需要 316 天才能识别并控制违规行为。而平均情况是 287 天,远程工作似乎使控制数据泄露的时间延长了一个月。
不过,报告表示更快的响应时间会显著降低成本花费。如果能够在不到 200 天的时间内控制违规行动,可以节省近 30% 的成本。
新安全技术应用
尽管数据泄露成本逐渐变高、控制损失时间越来越长,但人工智能、安全自动化和零信任技术的应用在降低数据泄露成本上取得了令人欣喜的进展。这些手段有助于控制损失,也在更多的公司进行了部署。
报告发现,完全或者部分部署了安全人工智能/安全自动化的组织从 2020 年的 59% 上升至 65%。这些组织会最大可能地降低数据泄露成本,部署了安全人工智能/安全自动化的组织的平均成本会减少 381 万美元。没有使用安全自动化时,泄露平均成本为 671 万美元,而在部署安全自动化的组织中平均为 290 万美元,相差 79.3%。
零信任也有助于降低数据泄露成本,但目前只有 35% 的组织部署了零信任。没有部署零信任时,数据泄露的成本为 504 万美元,部署后可降低 42% 到 328 万美元。
云安全
混合云模型的平均成本最低。与公共云、私有云和内部部署的云相比,混合云的平均成本更低。混合云数据泄露的成本平均比公共云数据泄露低 119 万美元。云也有助于减少响应时间,但与此同时云迁移的成本也更高。成熟使用云的组织比刚开始使用云的组织能更好的遏制漏洞(可从从 329 天降低到 252 天)。
量化安全风险
CISO 和安全团队可以使用数据泄露成本报告等研究报告来推断其行业或地域的总体趋势和成本平均值,或者使用风险量化来了解其特定组织的风险。
作为风险管理综合策略的一部分,安全风险量化计算某些事件的概率并计算对业务的估计财务影响。网络风险影响业务价值举例就是在合并和收购时发生,被收购公司未披露的数据泄露可能导致公司价值损失。其他风险包括股票估值威胁、业务损失、业务中断以及监管和法律成本。
报告也强调信息风险因素分析(FAIR)的应用。FAIR 是一种网络风险建模的开放国际标准,结合威胁情报可以帮助组织通过财务预测和概率评估网络风险的潜在影响。
具体措施
在报告中,您还可以找到 IBM Security 提供的、更为具体的安全措施与建议,这些建议可以减少数据泄露造成的潜在财务和声誉损失。可采取的措施部分如下所示:
- 部署安全编排(SOAR)
- 使用自动化和响应技术和服务
- 制定和实施事件响应计划
- 管理远程员工的认证与访问
- 采用零信任安全模型来帮助阻止对敏感数据的未授权访问 更多Linux资讯请查看:https://www.linuxprobe.com
这篇关于2021年IBM数据泄露成本报告:平均成本破纪录,达到424万美元的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






