本文主要是介绍CPU vs GPU:不仅仅是一字之差,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
当今科学技术的飞速发展,社会已经迈入了信息时代的智能化阶段。人脸识别、智能客服、个性化推荐等应用已经深入到日常生活的各个方面。这些看得见的应用背后,是看不见的算力在默默地支撑着。在满足这些高算力需求的过程中,CPU 和 GPU 作为计算机的核心组件发挥着重要的承载作用。那么,CPU 和 GPU 到底是什么?它们又有什么区别?
随着数据成为五大生产要素之一,算力的作用变得愈发重要。算力即计算能力(Computing Power),更具体来说,算力是指数据中心的服务器通过对数据进行处理后实现结果输出的一种能力。
算力的概念起源于计算机的发明初期。最早的计算机是由机械装置完成计算任务,而算力指的就是这些机械装置的计算能力。随后,半导体技术的出现和发展,集成电路问世,开启了芯片时代。计算机在芯片的加持下,功能越来越强大,体积也越来越小,最终诞生了个人计算机(PC),成为人类最重要的算力工具。
而后人工智能和大数据技术的迅猛发展也带动了算力需求的飞速增长。无论是训练复杂的神经网络模型,还是进行大规模数据分析和处理,算力都扮演着至关重要的角色。如今,芯片已经成为算力的主要载体。当我们谈论算力时,实际上是在讨论 CPU 和 GPU 等芯片的计算能力。在计算机科学领域,CPU 和 GPU 作为计算机的核心组件,虽然名字只有“一字之差”,但其结构和功能却大不相同。
1 CPU vs GPU: 概念
CPU(Central Processing Unit),即中央处理器,是电脑、手机等众多电子产品的“心脏”。在我们日常生活的诸多场景中,如观看视频、玩游戏、聊天互动等,CPU 发挥着统一指挥和调度的关键作用。它主要负责执行程序指令、进行算术和逻辑运算以及控制和协调计算机各个部件。
为了满足处理各种不同数据的强大通用性能,CPU 的内部结构设计非常复杂。CPU 由多个核心组成,每个核心又包含算术逻辑单元、控制单元和高速缓存等组件,并且可以独立地执行任务。至今为止,所有的 CPU 都遵循冯·诺依曼体系结构的基本工作流程:取指令,指令译码,执行指令,数据回写,然后再取下一个指令、译码、执行、回写,重复进行直到程序结束。通过这种工作流程,CPU 能够有效地执行程序,并控制整个系统的运行。
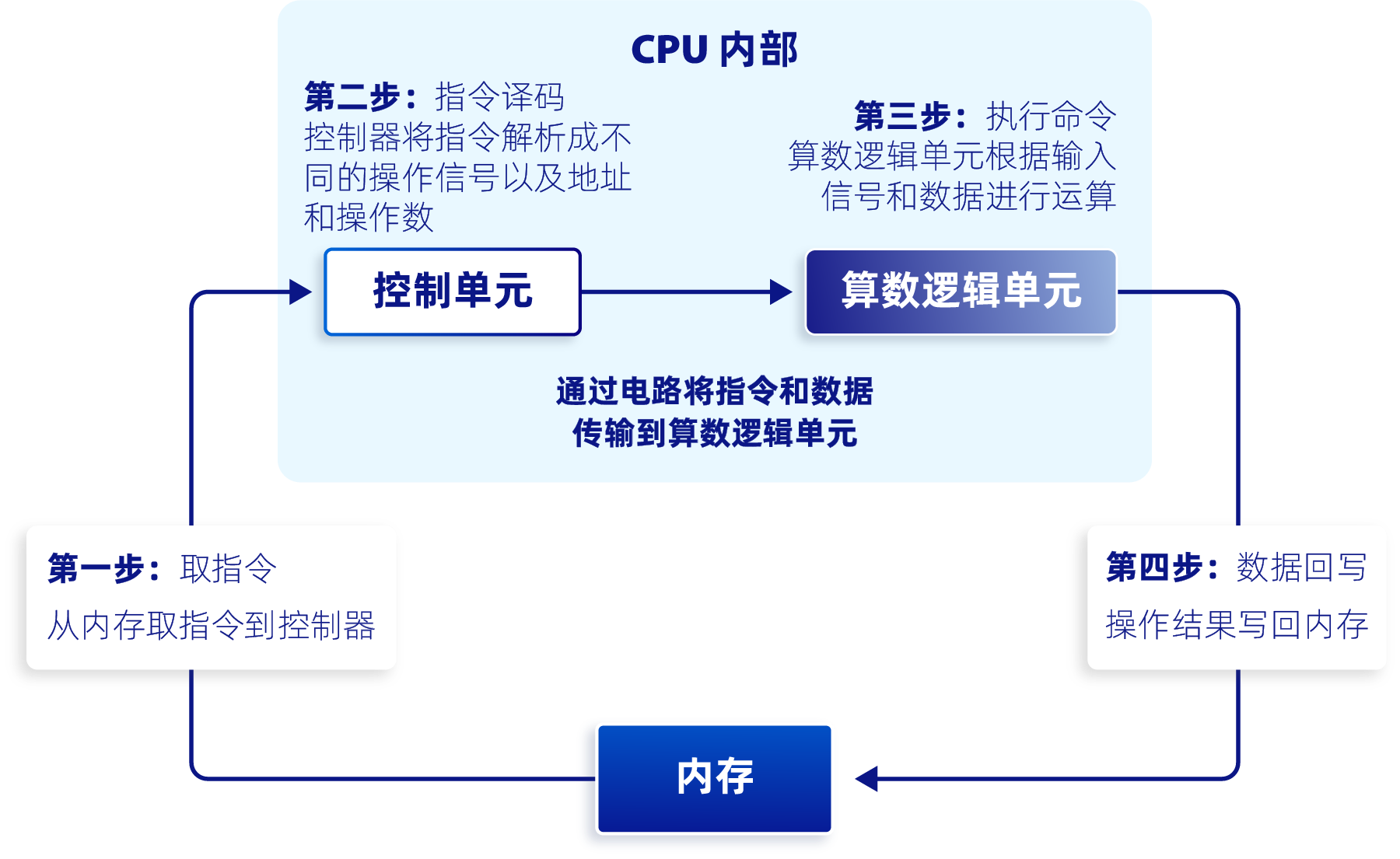
CPU 工作流程
然而,随着计算机的普及,人们对图形显示的要求不断提高,例如在进行复杂的三维建模时,需要处理大量的图形数据以呈现逼真的效果;在玩大型游戏时,要求系统能够处理高分辨率的画面和复杂的游戏场景。尽管 CPU 内部采用了各种方法来加速指令执行,但随着任务的增多,CPU 的性能显得有些力不从心。
面对这个问题,能否考虑增加更多的 CPU 来解决呢?这固然是一种思路,但这涉及到相当高的成本,并且堆叠数量也不能保证完全解决计算能力不足的问题。这时候聪明的开发者就提出了一个更巧妙的解决方案:既然 CPU 的计算能力有限,为什么不将计算单元堆叠在同一块芯片上,让它们处理大量运算的任务呢?于是,GPU 诞生了。
GPU(Graphics Processing Unit),即图形处理器, 顾名思义,一种专门用来处理图形和图像计算的处理器。GPU 最初是为图形渲染和显示而设计的,用于加速计算机中图像的处理,例如在视频游戏、电影渲染、图形设计等方面。它只有少量的控制单元和缓存单元,绝大部分的空间用来堆放运算单元,主要负责完成许多计算密集型任务。
2 CPU vs GPU: “差”在哪里?
通过引入 GPU,计算机系统可以充分利用其强大的并行计算能力,加速图形和图像相关的计算任务。CPU 负责逻辑任务,而 GPU 来处理大量简单重复的计算任务,这种不同类型的任务分配给不同类型的处理器的模式,大大提高了系统性能。那么,CPU 和 GPU 到底“差”在哪里呢?
2.1 架构组成
CPU 和 GPU 之间存在显著差异,是因为它们各自针对不同的目标和需求来设计,具体体现在:
-
CPU 需要有强大的通用性,以处理各种不同类型的数据,同时需要进行逻辑判断,包括大量的分支跳转和中断处理,这导致内部结构异常复杂。
-
GPU 主要面向类型高度统一、相互无依赖的大规模数据,并在纯净的计算环境中执行,因此不需要处理复杂的逻辑操作。
这就导致了 CPU 和 GPU 呈现出非常不同的架构:
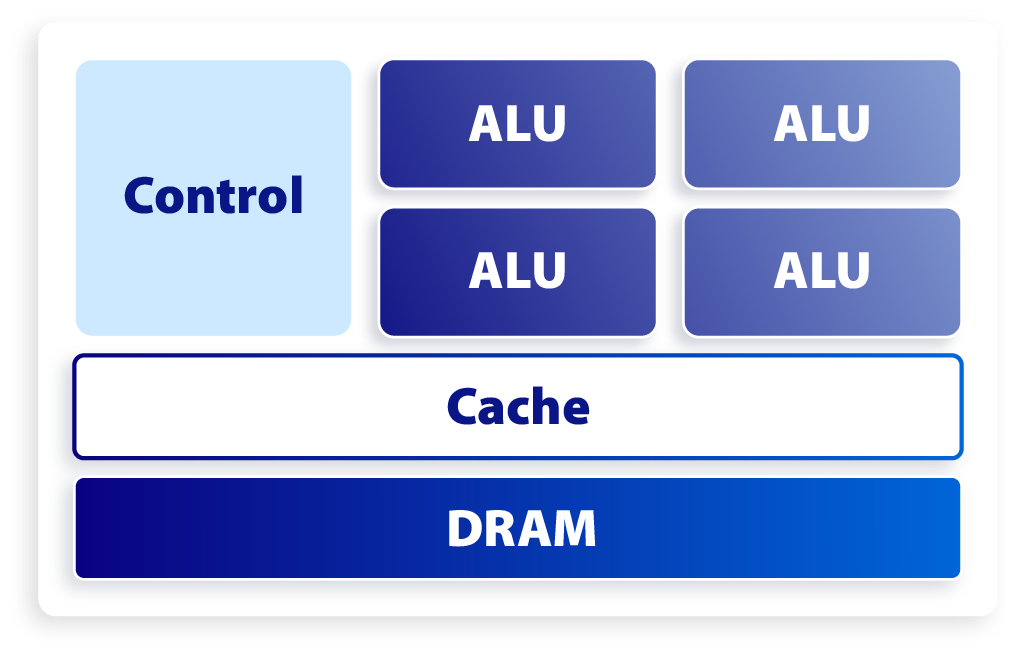
CPU 基本架构
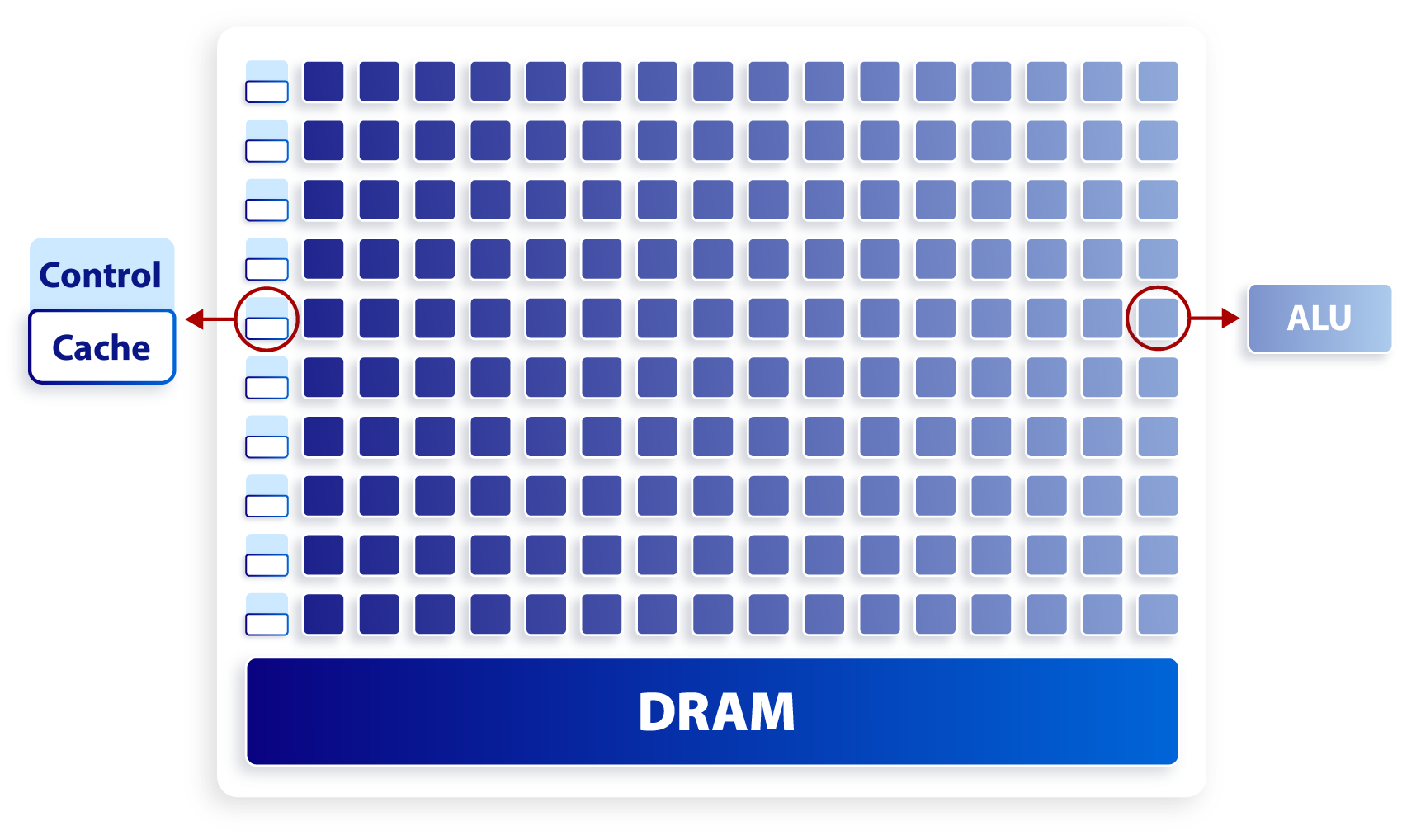
GPU 基本架构
CPU 拥有较大的缓存单元以及复杂的逻辑控制单元,相比之下计算能力只是 CPU 很小的一部分。而 GPU 则拥有数量众多的计算单元和超长的流水线,但只有非常简单的逻辑控制以及较小的缓存单元。
2.2 设计理念
CPU 和 GPU 的设计理念也截然不同。首先,CPU 是基于低延迟(Low Latency)设计的:
-
强大的运算单元: CPU 拥有数量较少但是单个计算性能更强的运算单元,可以减少操作延时,更快地响应。
-
大容量缓存: 将一部分数据存储到高速缓存当中,使得高延迟的内存访问转换为低延迟的缓存访问。
-
复杂的控制单元: 分支预测(Branch Prediction)机制可以降低分支延时;数据转发(Data Forwarding)机制降低数据延时。
而 GPU 则是基于高通量(High Throughput)设计的:
-
精简的运算单元: GPU 拥有大量的运算单元,虽然单个单元的性能比不上 CPU,但可以支持非常多的线程(Thread)从而达到非常大的吞吐量。
-
小容量缓存: 与 CPU 不同,GPU 缓存的目的并不是用来存储后面需要访问的数据,而是为线程提供服务,如果有很多线程需要访问同一个相同的数据,缓存会合并这些访问,然后再去访问内存。
-
简单的控制单元: GPU 的控制单元没有分支预测和数据转发机制。
总的来说,CPU 拥有数量相对少(一般不超过两位数)但能力更强的核心,能够更快地处理单个任务,因而它尤其适合处理串行任务和逻辑控制等类型的工作。相比之下,GPU 拥有成百上千核,虽然每个核心运算能力较低,但可以将复杂任务分解成非常多的子任务再并行处理。
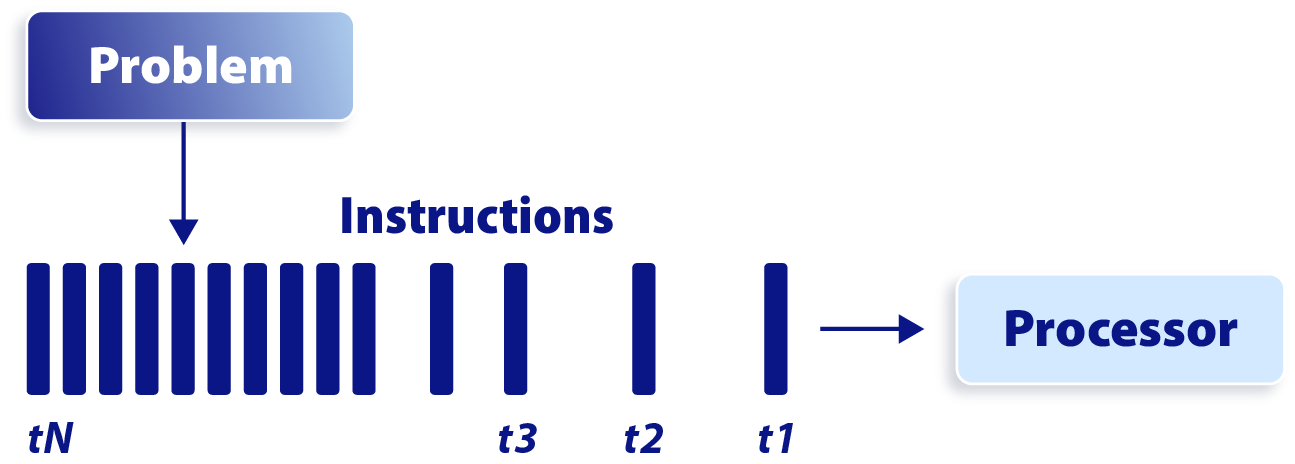
串行处理过程
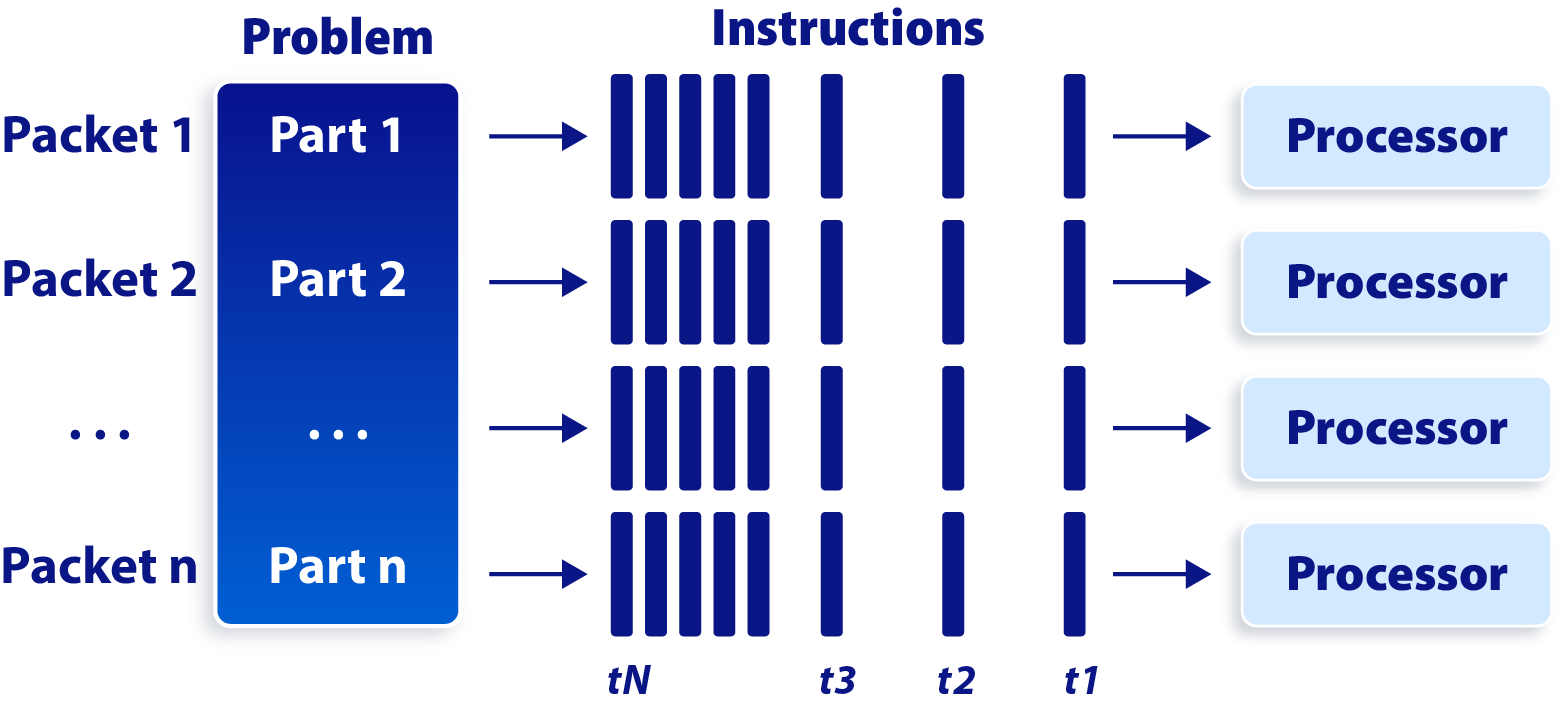
并行处理过程
2.3 适用场景
CPU 与 GPU 二者的设计目的并不一样,因而适用的场景也截然不同。CPU 更擅长一次处理一项任务,而 GPU 则可以同时处理多项任务。
用一个形象的比喻来解释。CPU 就像是一架高速飞机,而 GPU 则相当于一队货柜船。它们的任务是将大量货物从 A 位置迅速运送到 B 位置。虽然 CPU(飞机)速度非常快,但每次只能携带少量的货物,需要多次往返才能完成任务。相比之下,GPU(货柜船)虽然单次执行速度相对较慢,但通过协同工作,每艘都能同时携带一部分货物,最终以集体的力量高效完成运输任务。
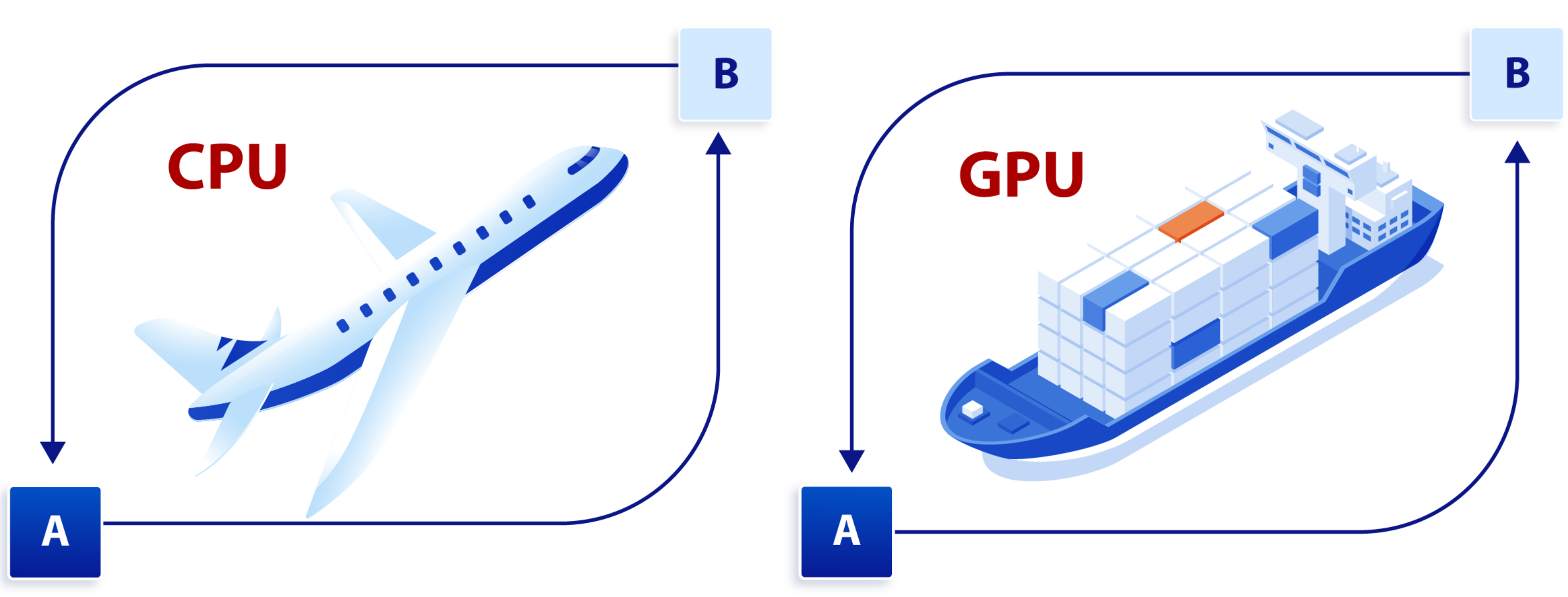
CPU 与 GPU 处理任务对比
因此,虽然 CPU 单次执行任务的时间更快,但是在需要大量重复工作负载时,GPU 优势就越显著。而当遇到前后计算步骤严密关联的计算场景,这些任务涉及到“流”的问题,必须先计算完第一步,再去计算第二步。或是需要进行大量逻辑判断和复杂计算的任务,比如运行操作系统、处理日常办公任务、进行单线程编程等。这种时候,使用 GPU 的效率反而没有 CPU 高。
综上所述,CPU 是个集各种运算能力的大成者。它的优点在于调度、管理、协调能力强,并且可以做复杂的逻辑运算,但由于运算单元和内核较少,只适合做相对少量的运算。GPU 无法单独工作,它相当于一大群接受 CPU 调度的流水线员工,适合做大量的简单运算。CPU 和 GPU 在功能上各有所长,互补不足,通过相互配合使用,实现最佳的计算性能。
因此,虽然 CPU 单次执行任务的时间更快,但是在需要大量重复工作负载时,GPU 优势就越显著。而当遇到前后计算步骤严密关联的计算场景,这些任务涉及到“流”的问题,必须先计算完第一步,再去计算第二步。或是需要进行大量逻辑判断和复杂计算的任务,比如运行操作系统、处理日常办公任务、进行单线程编程等。这种时候,使用 GPU 的效率反而没有 CPU 高。
综上所述,CPU 是个集各种运算能力的大成者。它的优点在于调度、管理、协调能力强,并且可以做复杂的逻辑运算,但由于运算单元和内核较少,只适合做相对少量的运算。GPU 无法单独工作,它相当于一大群接受 CPU 调度的流水线员工,适合做大量的简单运算。CPU 和 GPU 在功能上各有所长,互补不足,通过相互配合使用,实现最佳的计算性能。
3 CPU vs GPU: 演进与发展
技术的不断更新推动着计算机领域的快速发展,而在这个不断演进的过程中,CPU 和 GPU 也在持续发展。在过去的几十年里它们在各自的领域取得了显著的突破,为计算机应用提供了更高的性能和效率。这不仅推动了数字化时代信息技术的发展,也为各个领域带来了新的可能性。
3.1 扬长避短,稳步前进
CPU 拥有强大的指令处理和计算能力(这里强大的计算能力是指 CPU 可以胜任更复杂的计算任务),通常用于处理计算机的核心工作,包括解释计算机指令和处理计算机软件中的数据。例如我们在使用个人计算机时,用户和各种软件会不断地产生指令流,CPU 要完成的一个重要工作就是负责处理这些指令,保证它们按照规定的顺序执行。此外,CPU 还要负责处理计算机软件所产生的类型多样且逻辑复杂的数据。
距离第一块 CPU 4004 的诞生已经过去了五十多年,尽管与早期相比,CPU 在物理形态、设计制造和具体任务的执行上有了极大的发展,但是其基本的操作原理一直没有改变。换句话来说 ,CPU 的功能和使用场景并没有发生较大的改变,无非是在能耗、性能以及可靠性上面不断地优化。
3.2 GPU 加速应用遍地开花
3.2.1 从 GPU 到 GPGPU
GPU 的概念在 1999 年 NVIDIA 公司发布 GeForce 256 时被首次提出, 在早期,GPU 主要用于 3D 图形渲染。但与 CPU 不同,随着 GPU 的功能和运算能力越来越强大,开发者开始探索除了图形处理之外,GPU 还能做什么?
在 2003 年,NVIDIA 推出新产品 GeForce 8800 GTX 时,首次提出了 GPGPU(General-purpose computing on Graphics Processing Unit)的概念,即通用图形处理器,意指利用 GPU 的计算能力,在非图形处理领域进行更通用、更广泛的计算。
到了 2007 年,NVIDIA 进一步提出了名为 CUDA(Compute Unified Device Architecture,计算统一设备架构)的全新技术,利用该技术可以通过 NVIDIA 的 GPU 进行图像处理之外的计算任务,它揭开了 GPU 计算革命序幕。随后,苹果公司也推出了类似的技术:OpenCL(Open Computing Language)并在与 AMD,IBM,Intel 和 NVIDIA 技术团队的合作之下初步完善。OpenCL 是一个开放的、跨平台的并行计算框架,允许开发人员在不同的硬件平台(CPU、GPU、FPAG 等)上进行开发。
自此以后,GPU 不再以图形的 3D 加速为唯一目的,而是能够广泛应用于各领域的通用计算加速,尤其是科学计算、大数据分析以及人工智能等领域。
3.2.2 大模型与向量数据库
当今互联网世界所需的计算能力远远超出任何人的想象,并且只会随着人工智能的兴起而增加。以如今爆火的生成式 AI ChatGPT 为代表,大小为 175B 的 GPT-3 使用了 1024 张 A100 GPU 训练了约 34 天,随着参数数量的增加,往后 AI 需要的算力资源更是天文数字。
大模型同样引发了数据库领域的革命,此前不温不火的向量数据库搭上了这辆顺风车,一举成为 AI 时代的新宠。在 2023 英伟达 GTC AI 开发者大会中,NVIDIA CEO 黄仁勋首次提及向量数据库,并强调对于构建专有大模型的组织而言,向量数据库至关重要。
对于 AI 来说,向量是它理解世界的通用数据形式,不管是图片、视频、音频,都可以通过转换成向量来让 AI 识别,向量数据库作为专门对向量进行检索和存储的工具,能为大模型的应用落地解决诸如“没有长期记忆”、“幻觉”、“知识更新不及时”等问题。
但是,向量数据库本身的性能也是一个问题,说到底与大模型的结合只是其应用的一部分,它本质上还是一个数据搜索和分析的工具,如果性能满足不了用户需求,同样也会被淘汰。于是乎,开发者们又想起了 GPU。
在向量数据库中,最核心的功能在于向量相似性搜索,即在一个海量的数据中找到和某个向量最相似的向量,它的计算量十分庞大,而这恰好是 GPU 所擅长的,利用 GPU 的并行计算能力可以加速向量相似性搜索,显著提高查询速度,降低延迟。
4 云原生向量数据库 PieCloudVector 支持 GPU 加速
拓数派大模型数据计算系统 πDataCS 三大数据计算引擎之一:向量数据库 PieCloudVector,是大模型时代的分析型数据库升维,目标是助力多模态大模型 AI 应用,进一步实现海量向量数据存储与高效查询。PieCloudVector 支持和配合大模型的 Embeddings,帮助基础模型在场景 AI 的快速适配和二次开发,是大模型必备应用。
PieCloudVector 充分利用现代化硬件能力,支持 GPU 加速功能。 这一特性让 PieCloudVector 能够利用 GPU 的并行计算能力来加速向量计算和数据处理任务,显著缩短任务的执行时间,提高计算效率,帮助用户更高效地进行数据计算。特别是在需要处理大规模数据集或进行复杂的数值运算时,GPU 加速可以大幅提升计算性能。
这篇关于CPU vs GPU:不仅仅是一字之差的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








