本文主要是介绍Camunda 流程引擎API介绍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

💖专栏简介
✔️本专栏将从Camunda(卡蒙达) 7中的关键概念到实现中国式工作流相关功能。
✔️文章中只包含演示核心代码及测试数据,完整代码可查看作者的开源项目snail-camunda
✔️请给snail-camunda 点颗星吧😘
💖Services API
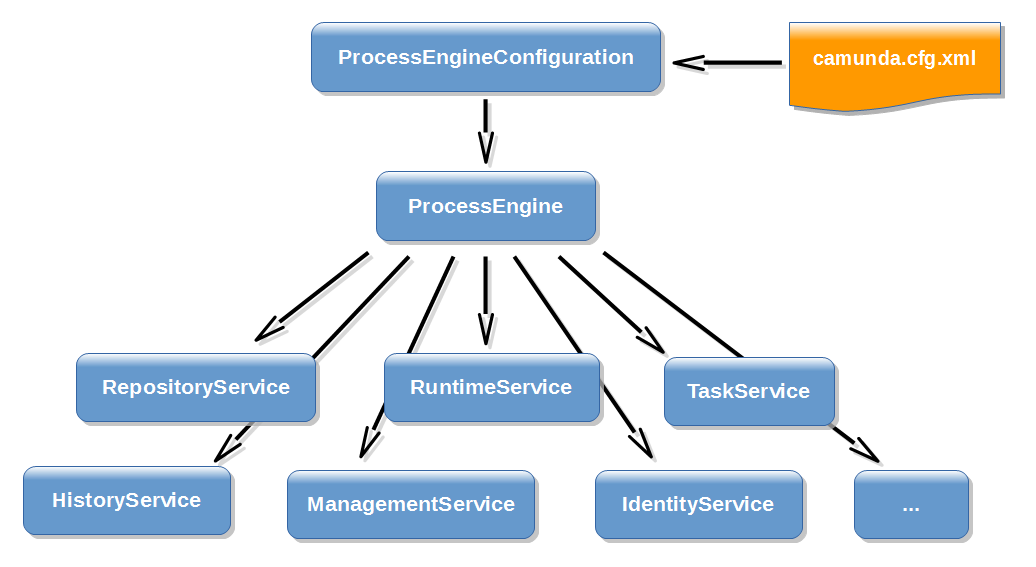
🧡RepositoryService
RepositoryService 可能是使用 Camunda 引擎时需要的第一个服务。此服务提供用于管理和部署流程定义的操作。此外,此服务允许
- 查询引擎已知的部署和进程定义。
- 暂停和激活流程定义。挂起意味着无法对它们进行进一步的操作,而激活则相反。
- 检索各种资源,例如部署中包含的文件或引擎自动生成的流程图。
🧡RuntimeService
RuntimeService 可以用来启动流程实例,也是用于检索和存储流程变量的服务。RuntimeService 还允许查询流程实例和执行。执行是 BPMN 2.0 的“令牌”概念的表示,这个“令牌”概念在之前的篇章《认识BPMN2.0》中也有提及,实质上执行是指向流程实例当前位置的指针。而流程实例等待外部触发器并且流程需要继续时,也会使用 RuntimeService。
🧡TaskService
TaskService 是围绕任务的所有操作,任务才是流程引擎的核心。例如
- 查询分配给用户或组的任务。
- 创建新的独立任务。这些任务与流程实例无关。
- 操作将任务分配给哪个用户或哪些用户以某种方式参与该任务。
- 认领并完成任务。
🧡IdentityService
IdentityService 允许管理(创建、更新、删除、查询等)组和用户。重要的是要了解核心引擎实际上不会在运行时对用户进行任何检查。例如,可以将任务分配给任何用户,但引擎不会验证系统是否知道该用户。
🧡FormService
FormService 是一项可选服务。这意味着 Camunda 引擎可以在没有它的情况下完美使用,而不会牺牲任何功能。此服务引入了开始表单和任务表单的概念。开始表单是在启动流程实例之前向用户显示的表单,而任务表单是在用户想要完成任务时显示的表单。
🧡HistoryService
HistoryService 公开引擎收集的所有历史数据。在执行流程时,引擎可以保留大量数据(这是可配置的),例如流程实例的开始时间、谁执行了哪些任务、完成任务需要多长时间、每个任务遵循的路径流程实例等。此服务主要公开用于访问此数据的查询功能。
🧡ManagementService
ManagementService允许检索有关数据库表和表元数据的信息。此外,它还公开了作业的查询功能和管理操作。作业在引擎中用于各种操作,例如计时器、异步延续、延迟挂起/激活等。
🧡FilterService
FilterService 允许创建和管理过滤器。筛选器是存储查询,如任务查询。例如,Tasklist 使用筛选器来筛选用户任务。
🧡ExternalTaskService
ExternalTaskService 提供对外部任务实例的访问。外部任务表示在外部独立于流程引擎处理的工作项。
💖Query API
要从引擎查询数据有多种方式:
🧡Java Queries
List<Task> tasks = taskService.createTaskQuery().taskAssignee("userOne").processVariableValueEquals("orderId", "8888").orderByDueDate().asc().list();在不限制最大结果数或查询大量结果的情况下可能会导致高内存消耗,甚至导致内存不足异常。而查询的最大结果集可以通过配置queryMaxResultsLimit参数,默认值是231-1。
🧡Native Queries
如果查询 API 缺少您需要的可能性(例如,OR 条件),则提供自己的 SQL 查询来检索引擎实体(如 ProcessInstances、Tasks 等),返回类型由您使用的 Query 对象定义,数据映射到正确的对象,例如 Task、ProcessInstance、Execution 等。由于查询将在数据库上触发,因此必须使用表名和列名。
List<Task> tasks = taskService.createNativeTaskQuery().sql("SELECT * FROM " + managementService.getTableName(Task.class) + " T WHERE T.NAME_ = #{taskName}").parameter("taskName", "aOpenTask").list();long count = taskService.createNativeTaskQuery().sql("SELECT count(*) FROM " + managementService.getTableName(Task.class) + " T1, "+ managementService.getTableName(VariableInstanceEntity.class) + " V1 WHERE V1.TASK_ID_ = T1.ID_").count();🧡Custom Queries
虽然java queries非常简单,但是我们只能使用它提供的查询,也不能对域对象添加约束。
例如下图我们希望返回的查询结果是Customer,此时就需要自定义查询,具体如何实现将在后续的文章中详细讲解。


这篇关于Camunda 流程引擎API介绍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





