本文主要是介绍TensorFlow Wide And Deep 模型详解与应用 TensorFlow Wide-And-Deep 阅读344 作者简介:汪剑,现在在出门问问负责推荐与个性化。曾在微软雅虎工作,,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
-
TensorFlow Wide And Deep 模型详解与应用
阅读344


作者简介:汪剑,现在在出门问问负责推荐与个性化。曾在微软雅虎工作,从事过搜索和推荐相关工作。
责编:何永灿(heyc@csdn.net)
本文首发于CSDN,未经允许不得转载。
Wide and deep 模型是 TensorFlow 在 2016 年 6 月左右发布的一类用于分类和回归的模型,并应用到了 Google Play 的应用推荐中 [1]。wide and deep 模型的核心思想是结合线性模型的记忆能力(memorization)和 DNN 模型的泛化能力(generalization),在训练过程中同时优化 2 个模型的参数,从而达到整体模型的预测能力最优。
结合我们的产品应用场景同 Google Play 的推荐场景存在较多的类似之处,在经过调研和评估后,我们也将 wide and deep 模型应用到产品的推荐排序模型,并搭建了一套线下训练和线上预估的系统。鉴于网上对 wide and deep 模型的相关描述和讲解并不是特别多,我们将这段时间对 TensorFlow1.1 中该模型的调研和相关应用经验分享出来,希望对相关使用人士带来帮助。
wide and deep 模型的框架在原论文的图中进行了很好的概述。wide 端对应的是线性模型,输入特征可以是连续特征,也可以是稀疏的离散特征,离散特征之间进行交叉后可以构成更高维的离散特征。线性模型训练中通过 L1 正则化,能够很快收敛到有效的特征组合中。deep 端对应的是 DNN 模型,每个特征对应一个低维的实数向量,我们称之为特征的 embedding。DNN 模型通过反向传播调整隐藏层的权重,并且更新特征的 embedding。wide and deep 整个模型的输出是线性模型输出与 DNN 模型输出的叠加。
如原论文中提到的,模型训练采用的是联合训练(joint training),模型的训练误差会同时反馈到线性模型和 DNN 模型中进行参数更新。相比于 ensemble learning 中单个模型进行独立训练,模型的融合仅在最终做预测阶段进行,joint training 中模型的融合是在训练阶段进行的,单个模型的权重更新会受到 wide 端和 deep 端对模型训练误差的共同影响。因此在模型的特征设计阶段,wide 端模型和 deep 端模型只需要分别专注于擅长的方面,wide 端模型通过离散特征的交叉组合进行 memorization,deep 端模型通过特征的 embedding 进行 generalization,这样单个模型的大小和复杂度也能得到控制,而整体模型的性能仍能得到提高。
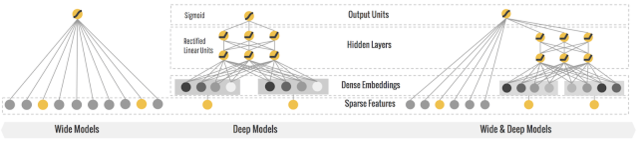
Wide And Deep 模型定义
定义 wide and deep 模型是比较简单的,tutorial 中提供了比较完整的模型构建实例:
获取输入
模型的输入是一个 python 的 dataframe。如 tutorial 的实例代码,可以通过 pandas.read_csv 从 CSV 文件中读入数据构建 data frame。
定义 feature columns
tf.contrib.layers 中提供了一系列的函数定义不同类型的 feature columns:
- tf.contrib.layers.sparse_column_with_XXX 构建低维离散特征
sparse_feature_a = sparse_column_with_hash_bucket(…)
sparse_feature_b = sparse_column_with_hash_bucket(…) - tf.contrib.layers.crossed_column 构建离散特征的组合
sparse_feature_a_x_sparse_feature_b = crossed_column([sparse_feature_a, sparse_feature_b], …) - tf.contrib.layers.real_valued_column 构建连续型实数特征
real_feature_a = real_valued_column(…) - tf.contrib.layers.embedding_column 构建 embedding 特征
sparse_feature_a_emb = embedding_column(sparse_id_column=sparse_feature_a, )
定义模型
定义分类模型:
m = tf.contrib.learn.DNNLinearCombinedClassifier(n_classes = n_classes, // 分类数目weight_column_name = weight_column_name, // 训练实例的权重model_dir = model_dir, // 模型目录linear_feature_columns = wide_columns, // 输入线性模型的 feature columnslinear_optimizer = tf.train.FtrlOptimizer(...), // 线性模型权重更新的 optimizerdnn_feature_columns = deep_columns, // 输入 DNN 模型的 feature columnsdnn_hidden_units=[100, 50],// DNN 模型的隐藏层单元数目dnn_optimizer=tf.train.AdagradOptimizer(...) // DNN 模型权重更新的 optimizer)
需要指出的是:模型的 model_dir 同下面会提到的 export 模型的目录是 2 个不同的目录,model_dir 存放模型的 graph 和 summary 数据,如果 model_dir 存放了上一次训练的模型数据,训练时会从 model_dir 恢复上一次训练的模型并在此基础上进行训练。我们用 tensorboard 加载显示的模型数据也是从该目录下生成的。模型 export 的目录则主要是用于 tensorflow server 启动时加载模型的 servable 实例,用于线上预测服务。
如果要使用回归模型,可以如下定义:
m = tf.contrib.learn.DNNLinearCombinedRegressor(weight_column_name = weight_column_name,linear_feature_columns = wide_columns, linear_optimizer = tf.train.FtrlOptimizer(...), dnn_feature_columns = deep_columns, dnn_hidden_units=[100, 50],dnn_optimizer=tf.train.AdagradOptimizer(...))
训练评测
训练模型可以使用 fit 函数:m.fit(input_fn=input_fn(df_train)),评测使用 evaluate 函数:m.evaluate(input_fn=input_fn(df_test))。Input_fn 函数定义如何从输入的 dataframe 构建特征和标记:
def input_fn(df)// tf.constant 构建 constant tensor,df[k].values 是对应 feature column 的值构成的 listcontinuous_cols = {k: tf.constant(df[k].values) for k in CONTINUOUS_COLUMNS}// tf.SparseTensor 构建 sparse tensor,SparseTensor 由 indices,values, dense_shape 三// 个 dense tensor 构成,indices 中记录非零元素在 sparse tensor 的位置,values 是// indices 中每个位置的元素的值,dense_shape 指定 sparse tensor 中每个维度的大小// 以下代码为每个 category column 构建一个 [df[k].size,1] 的二维的 SparseTensor。categorical_cols = { k: tf.SparseTensor( indices=[[i, 0] for i in range(df[k].size)],values=df[k].values,dense_shape=[df[k].size, 1])for k in CATEGORICAL_COLUMNS}// 可以用以下示意图来表示以上代码构建的 sparse tensor
// label 是一个 constant tensor,记录每个实例的 labellabel = tf.constant(df[LABEL_COLUMN].values)// features 是 continuous_cols 和 categorical_cols 的 union 构成的 dict// dict 中每个 entry 的 key 是 feature column 的 name,value 是 feature column 值的 tensorreturn features, label
输出
模型通过 export 输出到一个指定目录,tensorflow serving 从该目录加载模型提供在线预测服务:m.export(export_dir=export_dir,input_fn = export._default_input_fn
use_deprecated_input_fn=True,signature_fn=signature_fn)
input_fn 函数定义生成模型 servable 实例的特征,signature_fn 函数定义模型输入输出的 signature。
由于在 TensorFlow1.0 之后 export 已经 deprecate,需要用 export_savedmodel 来替代,所以本文就不对 export 进行更多讲解,只在文末给出我们是如何使用它的,建议所有使用者以后切换到最新的 API。
模型详解
wide and deep 模型是基于 TF.learn API 来实现的,其源代码实现主要在 tensorflow.contrib.learn.python.learn.estimators 中。以分类模型为例,wide 与 deep 结合的分类模型对应的类是 DNNLinearCombinedClassifier,实现在源文件 dnn_linear_combined.py。我们先看看 DNNLinearCombinedClassifier 的初始化函数的完整定义,看构造一个 wide and deep 模型可以输入哪些参数:
def __init__(self, model_dir=None, n_classes=2, weight_column_name=None, linear_feature_columns=None,linear_optimizer=None, joint_linear_weights=False, dnn_feature_columns=None, dnn_optimizer=None, dnn_hidden_units=None, dnn_activation_fn=nn.relu, dnn_dropout=None,gradient_clip_norm=None, enable_centered_bias=False, config=None,feature_engineering_fn=None, embedding_lr_multipliers=None):
我们可以将类的构造函数中的参数分为以下几组
基础参数
-
model_dir
我们训练的模型存放到 model_dir 指定的目录中。如果我们需要用 tensorboard 来 DEBUG 模型,将 tensorboard 的 logdir 指向该目录即可:tensorboard –logdir=$model_dir -
n_classes
分类数。默认是二分类,>2 则进行多分类。 -
weight_column_name
定义每个训练样本的权重。训练时每个训练样本的训练误差乘以该样本的权重然后用于权重更新梯度的计算。如果需要为每个样本指定权重,input_fn 返回的 features 里需要包含一个以 weight_column_name 为列名的列,该列的长度为训练样本的数目,列中每个元素对应一个样本的权重,数据类型是 float,如以下伪代码:
weight = tf.constant(df[WEIGHT_COLUMN_NAME].values, dtype=float32);features[weight_column_name] = weight-
config
指定运行时配置参数 -
eature_engineering_fn
对输入函数 input_fn 输出的 (features, label) 进行后处理生成新的 (features』, label』) 然后输入给模型训练函数 model_fn 使用。
call_model_fn():feature, labels = self._feature_engineering_fn(feature, labels)
线性模型相关参数
-
linear_feature_columns
线性模型的输入特征 -
linear_optimizer
线性模型的优化函数,定义权重的梯度更新算法,默认采用 FTRL。所有默认支持的 linear_optimizer 和 dnn_optimizer 可以在 optimizer.py 的 OPTIMIZER_CLS_NAMES 变量中找到相关定义。 -
join_linear_weights
按照代码中的注释,如果 join_linear_weights= true,线性模型的权重会存放在一个 tf.Variable 中,可以加快训练,但是 linear_feature_columns 中的特征列必须都是 sparse feature column 并且每个 feature column 的 combiner 必须是“sum”。经过自己线下的对比试验,对模型的预测能力似乎没有太大影响,对训练速度有所提升,最终训练模型时我们保持了默认值。
DNN 模型相关参数
-
dnn_feature_columns
DNN 模型的输入特征 -
dnn_optimizer
DNN 模型的优化函数,定义各层权重的梯度更新算法,默认采用 Adagrad。 -
dnn_hidden_units
每个隐藏层的神经元数目 -
dnn_activation_fn
隐藏层的激活函数,默认采用 RELU -
dnn_dropout
模型训练中隐藏层单元的 drop_out 比例 -
gradient_clip_norm
定义 gradient clipping,对梯度的变化范围做出限制,防止 gradient vanishing 或 gradient explosion。wide and deep 中默认采用 tf.clip_by_global_norm。 -
embedding_lr_multipliers
embedding_feature_column 到 float 的一个 mapping。对指定的 embedding feature column 在计算梯度时乘以一个常数因子,调整梯度的变化速率。
看完模型的构造函数后,我们大概知道 wide 和 deep 端的模型各对应什么样的模型,模型需要输入什么样的参数。为了更深入了解模型,以下我们对 wide and deep 模型的相关代码进行了分析,力求解决如下疑问: (1) 分别用于线性模型和 DNN 模型训练的特征是如何定义的,其内部如何实现;(2) 训练中线性模型和 DNN 模型如何进行联合训练,训练误差如何反馈给 wide 模型和 deep 模型?下面我们重点针对特征和模型训练这两方面进行解读。
特征
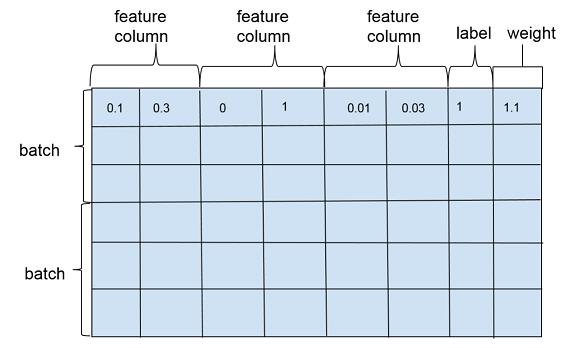
wide and deep 模型训练一般是以多个训练样本作为 1 个批次 (batch) 进行训练,训练样本在行维度上定义,每一行对应一个训练样本实例,包括特征(feature column),标注(label)以及权重(weight),如图 2。特征在列维度上定义,每个特征对应 1 个 feature column,feature column 由在列维度上的 1 个或者若干个张量 (tensor) 组成,tensor 中的每个元素对应一个样本在该 feature column 上某个维度的值。feature column 的定义在可以在源代码的 feature_column.py 文件中找到,对应类为_FeatureColumn,该类定义了基本接口,是 wide and deep 模型中所有特征类的抽象父类。
wide and deep 模型中使用的特征包括两大类: 一类是连续型特征,主要用于 deep 模型的训练,包括 real value 类型的特征以及 embedding 类型的特征等;一类是离散型特征,主要用于 wide 模型的训练,包括 sparse 类型的特征以及 cross 类型的特征等。以下是所有特征的一个汇总图
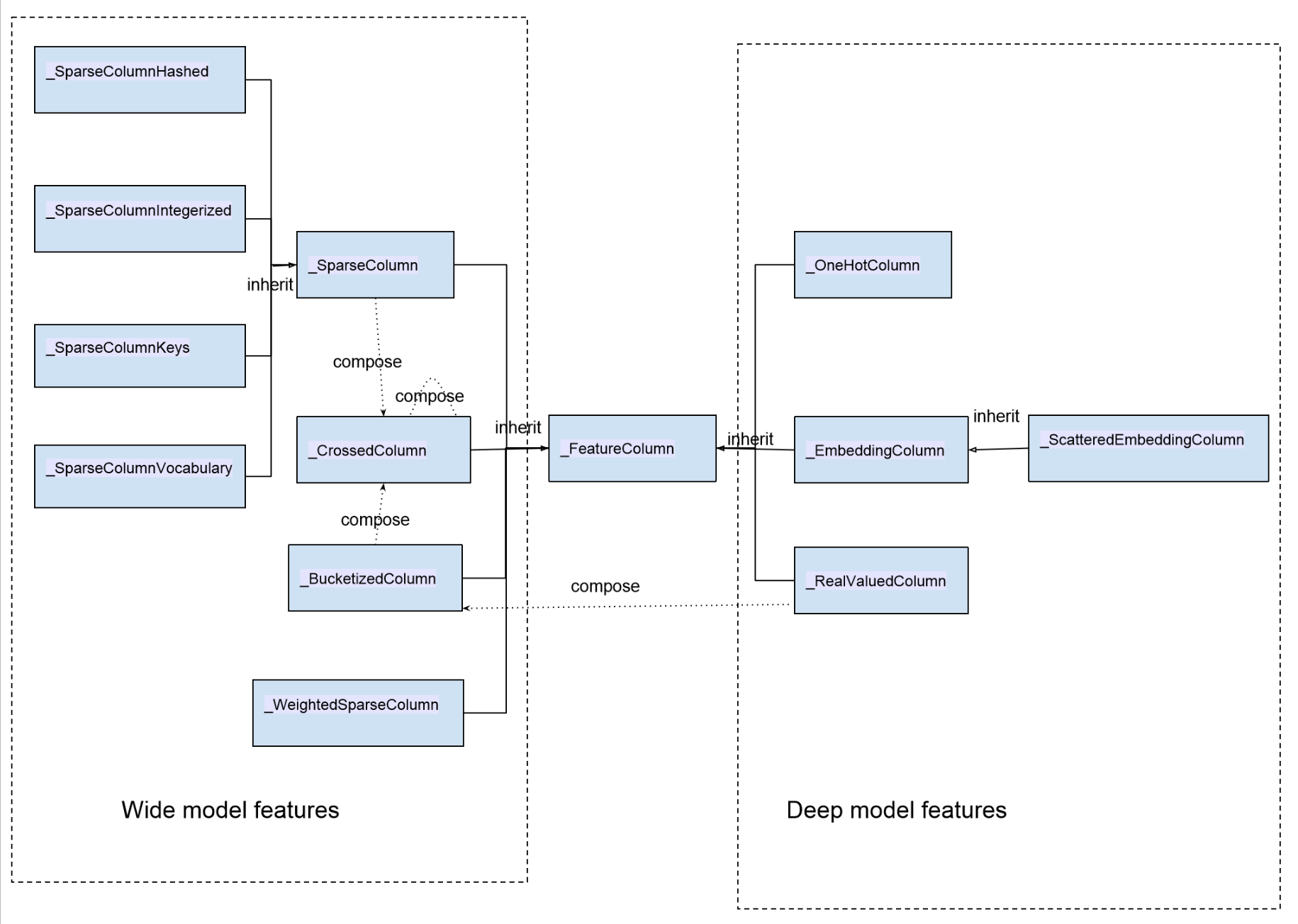
图中类与类的关系除了 inherit(继承)之外,同时我们也标出了特征类之间的构成关系:_BucketizedColumn 由_RealValueColumn 通过对连续值域进行分桶构成,_CrossedColumn 由若干_SparseColumn 或者_BucketizedColumn 或者_CrossedColumn 经过交叉组合构成。图中左边部分特征属于离散型特征,右边部分特征属于连续型特征。
我们在实际使用的时候,通常情况下是调用 TensorFlow 提供的接口来构建特征的。以下是构建各类特征的接口:
sparse_column_with_integerized_feature() --> _SparseColumnIntegerizedsparse_column_with_hash_bucket() --> _SparseColumnHashedsparse_column_with_keys() --> _SparseColumnKeyssparse_column_with_vocabulary_file() --> _SparseColumnVocabularyweighted_sparse_column() --> _WeightedSparseColumnone_hot_column() --> _OneHotColumnembedding_column() --> _EmbeddingColumnshared_embedding_columns() --> List[_EmbeddingColumn]scattered_embedding_column() --> _ScatteredEmbeddingColumnreal_valued_column() --> _RealValuedColumnbucketized_column() -->_BucketizedColumncrossed_column() --> _CrossedColumnFeatureColumn 为模型训练定义了几个基本接口用于提取和转换特征,在后面讲解具体 feature 时会有具体描述:
-
def insert_transformed_feature(self, columns_to_tensors):
“”“Apply transformation and inserts it into columns_to_tensors.
FeatureColumn 的特征输出和转换函数。columns_to_tensor 是 FeatureColumn 到 tensors 的映射。 -
def _to_dnn_input_layer(self, input_tensor, weight_collection=None, trainable=True, output_rank=2):
“”“Returns a Tensor as an input to the first layer of neural network.”“”
构建 DNN 的 float tensor 输入,参见后面对 RealValuedColumn 的讲解。 -
def _deep_embedding_lookup_arguments(self, input_tensor):
“”“Returns arguments to embedding lookup to build an input layer.”“”
构建 DNN 的 embedding 输入,参见后面对 EmbeddingColumn 的讲解。 -
def _wide_embedding_lookup_arguments(self, input_tensor):
“”“Returns arguments to look up embeddings for this column.”“”
构建线性模型的输入,参见后面对 SparseColumn 的讲解。
我们从离散型的特征(sparse 特征)开始分析。离散型特征可以看做由若干键值构成的特征,比如用户的性别。在实际实现中,每一个键值在 sparse column 内部对应一个整数 id。离散特征的基类是_SparseColumn:
class _SparseColumn(_FeatureColumn,collections.namedtuple("_SparseColumn",["column_name", "is_integerized","bucket_size", "lookup_config","combiner", "dtype"])):
collections.namedtuple 中的字符串数组是_SparseColumn 从对应的创建接口函数中接收的输入参数的名称。
def __new__(cls,column_name,is_integerized=False,bucket_size=None,lookup_config=None,combiner="sum",dtype=dtypes.string):
SparseFeature 是如何存放这些离散取值的呢?这个跟 bucket_size 和 lookup_config 这两个参数相关。在实际定义中,有且只定义其中一个参数。通过使用哪一个参数我们可以把 sparse feature 分成两类,定义 lookup_config 参数的特征使用一个 in memory 的字典存储 feature 的所有取值,包括后面会讲到的_SparseColumnKeys,_SparseColumnVocabulary;定义 bucket_size 参数的特征使用一个哈希表来存储特征值,特征值通过哈希函数散列到各个桶,包括_SparseColumnHashed 和_SparseColumnIntegerized(is_integerized = True)。
dtype 指定特征值的类型,除了字符串类型 (dtypes.string)之外,spare feature column 还支持 64 位整数类型(dtypes.int64),默认我们认为输入的离散特征是字符串,如果我们定义了 is_integerized = True,那么我们认为特征是一个整型的 id 型特征,我们可以直接用特征的取值作为特征的 id,而不需要建立一个专门的映射。
combiner 参数对应的是样本维度特征的归一化,如果特征列在单个样本上有多个取值,combiner 参数指定如何对单个样本上特征的多个取值进行归一化。源代码注释中是这样写的:「combiner: A string specifying how to reduce if the sparse column is multivalent」,multivalent 的具体含义在 crossed feature column 的定义中有一个稍微清楚的解释(combiner: A string specifying how to reduce if there are multiple entries in a single row)。combiner 可以指定 3 种归一化方式:sum 对应无归一化,sqrtn 对应 L2 归一化,mean 对应 L1 归一化。通常情况下采用 L2 归一化,模型的准确度相对会更高。
SparseColumn 不能直接作为 DNN 的输入,它只能用于直接构建线性模型的输入:
def _wide_embedding_lookup_arguments(self, input_tensor):return _LinearEmbeddingLookupArguments( input_tensor=self.id_tensor(input_tensor),weight_tensor=self.weight_tensor(input_tensor),vocab_size=self.length,initializer=init_ops.zeros_initializer(),combiner=self.combiner)
_LinearEmbeddingLookupArguments 是一个 namedtuple(A new subclass of tuple with named fields)。input_tensor 是训练样本集中特征的 id 构成的数组,weight_tensor 中每个元素对应一个样本中该特征的权重,vocab_size 是特征取值的个数,intiializer 是特征初始化的函数,默认初始化为 0。
不过看源代码中_SparseColumn 及其子类并没有使用特征权重:
def weight_tensor(self, input_tensor):"""Returns the weight tensor from the given transformed input_tensor."""return None
如果需要为_SparseColumn 的特征赋予权重,可以使用_WeightedSparseColumn,构造接口函数为 weighted_sparse_column(Create a _SparseColumn by combing sparse_id_column and weight_column)
class _WeightedSparseColumn(_FeatureColumn, collections.namedtuple("_WeightedSparseColumn",["sparse_id_column", "weight_column_name", "dtype"])):def __new__(cls, sparse_id_column, weight_column_name, dtype):return super(_WeightedSparseColumn, cls).__new__(cls, sparse_id_column, weight_column_name, dtype)
_WeightedSparseColumn 需要 3 个参数:sparse_id_column 对应 sparse feature column,是_SparseColumn 类型的对象,weight_column_name 为输入中对应 sparse_id_column 的 weight column(input_fn 返回的 features dict 中需要有一个 weight_column_name 的 tensor)dtype 是 weight column 中每个元素的数据类型。这里有几个隐含要求:
(1)dtype 需要能够转换成浮点数类型,否则会抛 TypeError;
(2)weight_column_name 对应的 weight column 可以是一个 SparseTensor,也可以是一个常规的 dense tensor,程序会将 dense tensor 转换成 SparseTensor,但是要求 weight column 最终对应的 SparseTensor 与 sparse_id_column 的 SparseTensor 有相同的索引 (indices) 和维度 (dense_shape)。
_WeightedSparseColumn 输出特征的 id tensor 和 weight tensor 的函数如下:
def insert_transformed_feature(self, columns_to_tensors):"""Inserts a tuple with the id and weight tensors."""if self.sparse_id_column not in columns_to_tensors:self.sparse_id_column.insert_transformed_feature(columns_to_tensors)weight_tensor = columns_to_tensors[self.weight_column_name]if not isinstance(weight_tensor, sparse_tensor_py.SparseTensor):# The weight tensor can be a regular Tensor. In such case, sparsify it.// 我们输入的 weight tensor 可以是一个常规的 Tensor,如通过 tf.Constants 构建的 tensor,// 这种情况下,会调用 dense_to_sparse_tensor 将 weight_tensor 转换成 SparseTensor。weight_tensor = contrib_sparse_ops.dense_to_sparse_tensor(weight_tensor)// 最终使用的 weight_tensor 的数据类型是 floatif not self.dtype.is_floating:weight_tensor = math_ops.to_float(weight_tensor)// 返回中对应该 WeightedSparseColumn 的一个二元组,二元组的第一个元素是 SparseFeatureColumn 调用 // insert_transformed_feature 后的 id_tensor,第二个元素是 weight tensor。columns_to_tensors[self] = tuple([columns_to_tensors[self.sparse_id_column],weight_tensor])def id_tensor(self, input_tensor):"""Returns the id tensor from the given transformed input_tensor."""return input_tensor[0]def weight_tensor(self, input_tensor):"""Returns the weight tensor from the given transformed input_tensor."""return input_tensor[1]
(1)sparse column from keys
这个是最简单的离散特征,类比于枚举类型,一般用于枚举的值不是太多的情况。创建基于 keys 的 sparse 特征的接口是 sparse_column_with_keys(column_name, keys, default_value=-1, combiner=None),对应类是 SparseColumnKeys,构造函数为:
def __new__(cls, column_name, keys, default_value=-1, combiner="sum"):return super(_SparseColumnKeys, cls).__new__(cls, column_name, combiner=combiner,lookup_config=_SparseIdLookupConfig(keys=keys, vocab_size=len(keys),default_value=default_value), dtype=dtypes.string)
keys 为一个字符串列表,定义了所有的枚举值。构造特征输入的 keys 最后存储在 lookup_config 里面,每个 key 的类型是 string,并且对应 1 个 id,id 是该 key 在输入的 keys 数组中的下标。在模型实际训练中使用的是每个 key 对应的 id。
SparseColumnKeys 输入到模型前需要将枚举值的 key 转换到相应的 id,这个转换工作在函数 insert_transformed_feature 中实现:
def insert_transformed_feature(self, columns_to_tensors):"""Handles sparse column to id conversion."""input_tensor = self._get_input_sparse_tensor(columns_to_tensors)""""Returns a lookup table that converts a string tensor into int64 IDs.This operation constructs a lookup table to convert tensor of strings into int64 IDs. The mapping can be initialized from a string `mapping` 1-D tensor where each element is a key and corresponding index within the tensor is thevalue."""table = lookup.index_table_from_tensor(mapping=tuple(self.lookup_config.keys),default_value=self.lookup_config.default_value, dtype=self.dtype, name="lookup")columns_to_tensors[self] = table.lookup(input_tensor)
(2)sparse column from vocabulary file
sparse column with keys 一般枚举都能满足,如果枚举的值多了就不合适了,所以提供了一个从文件加载枚举变量的接口:
sparse_column_with_vocabulary_file((column_name, vocabulary_file, num_oov_buckets=0, vocab_size=None,
default_value=-1, combiner="sum",dtype=dtypes.string)
对应的构造函数为:
def __new__(cls, column_name, vocabulary_file, num_oov_buckets=0, vocab_size=None, default_value=-1,combiner="sum", dtype=dtypes.string):
那么从文件中读入的特征值是存哪里呢?看看这个构造函数最后返回的类实例:
return super(_SparseColumnVocabulary, cls).__new__(cls, column_name,combiner=combiner,
lookup_config=_SparseIdLookupConfig(vocabulary_file=vocabulary_file,num_oov_buckets=num_oov_buckets,
vocab_size=vocab_size,default_value=default_value), dtype=dtype)
如同_SparseColumnKeys,这个特征也使用了_SparseIdLookupConfig 来存储特征值,vocabulary_file 指向定义枚举值的文件,vocabulary_file 每一行对应一个枚举值,每个枚举值的 id 是该枚举值所在行号(注意,行号是从 0 开始的),vocab_size 定义枚举值的个数。_SparseIdLookupConfig 从特征文件中构建一个特征值到 id 的哈希表,我们看看 SparseColumnVocabulary 进行 vocabulary 到 id 的转换时如何使用_SparseIdLookupConfig 对象。
def insert_transformed_feature(self, columns_to_tensors):"""Handles sparse column to id conversion."""st = self._get_input_sparse_tensor(columns_to_tensors)if self.dtype.is_integer:// 输入的整数数值型特征转换成字符串形式sparse_string_values = string_ops.as_string(st.values)sparse_string_tensor = sparse_tensor_py.SparseTensor(st.indices,sparse_string_values, st.dense_shape)else:sparse_string_tensor = st"""Returns a lookup table that converts a string tensor into int64 IDs.This operation constructs a lookup table to convert tensor of strings into int64 IDs. The mapping can be initialized from a vocabulary file specified in`vocabulary_file`, where the whole line is the key and the zero-based line number is the ID.table = lookup.index_table_from_file(vocabulary_file=self.lookup_config.vocabulary_file, num_oov_buckets=self.lookup_config.num_oov_buckets,vocab_size=self.lookup_config.vocab_size,default_value=self.lookup_config.default_value, name=self.name + "_lookup")columns_to_tensors[self] = table.lookup(sparse_string_tensor)
index_table_from_file 函数从 lookup_config 的字典文件中构建 table。Table 变量是一个 string 到 int64 的 HashTable,如果定义了 num_oov_buckets,table 是 IdTableWithHashBuckets 对象(a string to id wrapper that assigns out-of-vocabulary keys to buckets)。
(3)sparse column with hash bucket
如果没有 vocab 文件定义枚举特征,我们可以使用 hash bucket 特征,使用该特征的接口是
sparse_column_with_hash_bucket(column_name, hash_bucket_size, combiner=None,dtype=dtypes.string)
对应类_SparseColumnHashed 的构造函数为:def new(cls, column_name, hash_bucket_size, combiner=”sum”, dtype=dtypes.string):
ash_bucket_size 定义哈希桶的个数,用于哈希值取模。dtype 支持整数和字符串。实际计算哈希值的时候是将整数转换成对应的字符串表示形式,用字符串计算哈希值然后取模,转换后的特征值是 0 到 hash_bucket_size 的一个整数。
def insert_transformed_feature(self, columns_to_tensors):"""Handles sparse column to id conversion."""input_tensor = self._get_input_sparse_tensor(columns_to_tensors)if self.dtype.is_integer:// 整数类型的输入转换成字符串类型sparse_values = string_ops.as_string(input_tensor.values)else:sparse_values = input_tensor.valuessparse_id_values = string_ops.string_to_hash_bucket_fast(sparse_values, self.bucket_size, name="lookup")// Sparse 特征的哈希值作为特征值对应的 id 返回columns_to_tensors[self] = sparse_tensor_py.SparseTensor(input_tensor.indices, sparse_id_values,input_tensor.dense_shape)
(4)integerized sparse column
hash bucket 的 sparse 特征取哈希值的时候是将整数看做字符串处理的,如果我们希望用整数本身的数值作为哈希值,可以使用_SparseColumnIntegerized,对应的接口是
sparse_column_with_integerized_feature:def sparse_column_with_integerized_feature(column_name,hash_bucket_size,combiner="sum",dtype=dtypes.int64)
对应的类是_SparseColumnIntegerized:
def __new__(cls, column_name, bucket_size, combiner="sum", dtype=dtypes.int64)
特征的转换函数定义:
def insert_transformed_feature(self, columns_to_tensors):"""Handles sparse column to id conversion."""input_tensor = self._get_input_sparse_tensor(columns_to_tensors)// 直接对特征值取模,取模后的值作为特征值的 idsparse_id_values = math_ops.mod(input_tensor.values, self.bucket_size, name="mod")columns_to_tensors[self] = sparse_tensor_py.SparseTensor( input_tensor.indices, sparse_id_values, input_tensor.dense_shape)
(5)crossed column
Crossed column 支持 1 个以上的离散型 feature column 进行笛卡尔积,组成高维度的交叉特征。特征之间进行交叉,可以将特征之间的相关性引入模型,增强模型的表达能力。crossed column 仅支持以下 3 种离散特征的交叉组合: _SparsedColumn, _BucketizedColumn 和_CrossedColumn,其接口定义为:
def crossed_column(columns,hash_bucket_size, combiner=」sum」,ckpt_to_load_from=None,tensor_name_in_ckpt=None, hash_key=None)
对应类为_CrossedColumn:
def __new__(cls, columns,hash_bucket_size,hash_key, combiner="sum",ckpt_to_load_from=None, tensor_name_in_ckpt=None):
columns 对应一个 feature column 的集合,如 tutorial 中的例子:[age_buckets, education, occupation];hash_bucket_size 参数指定 hash bucket 的桶个数,特征交叉的组合个数越多,hash_bucket_size 也应相应增加,从而减小哈希冲突。
交叉特征生成模型输入的逻辑可以分为如下两步:
def insert_transformed_feature(self, columns_to_tensors):"""Handles cross transformation."""def _collect_leaf_level_columns(cross):"""Collects base columns contained in the cross."""leaf_level_columns = []for c in cross.columns:// 对 CrossedColumn 类型的 feature column 进行递归展开if isinstance(c, _CrossedColumn):leaf_level_columns.extend(_collect_leaf_level_columns(c))else:// SparseColumn 和 BucketizedColumn 作为叶子节点leaf_level_columns.append(c)return leaf_level_columns// 步骤 1: 将 crossed column 中的所有特征进行递归展开,展开后的特征值存放在 feature_tensors 数组中feature_tensors = []for c in _collect_leaf_level_columns(self):if isinstance(c, _SparseColumn):feature_tensors.append(columns_to_tensors[c.name])else:if c not in columns_to_tensors:c.insert_transformed_feature(columns_to_tensors)if isinstance(c, _BucketizedColumn):feature_tensors.append(c.to_sparse_tensor(columns_to_tensors[c]))else:feature_tensors.append(columns_to_tensors[c])// 步骤 2: 生成 cross feature 的 tensor,sparse_feature_cross 通过动态库调用 SparseFeatureCross 函数,函数接
//口可参见 sparse_feature_cross_op.cccolumns_to_tensors[self] = sparse_feature_cross_op.sparse_feature_cross(feature_tensors, hashed_output=True,num_buckets=self.hash_bucket_size,hash_key=self.hash_key, name="cross")
在源代码该部分的注释中有一个例子说明 feature column 进行 cross 后的效果,我们用 1 个图来将这部分注释展示的更明确点:
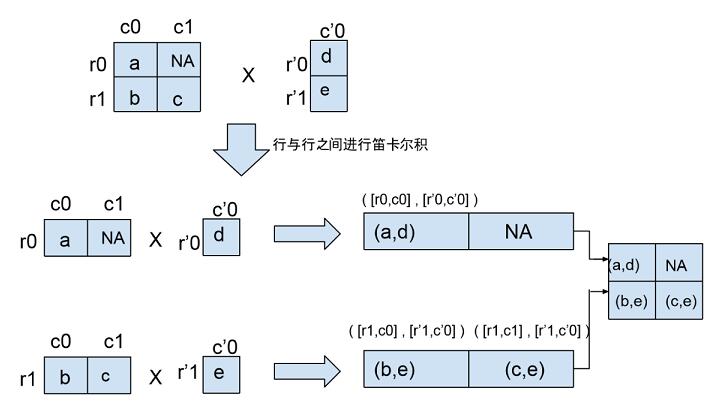
需要指出的一点是:交叉特征是没有权重定义的。
对离散特征进行交叉组合在预测模型中使用比较广泛,但是该类特征的一个局限性是它对训练数据中没有见过的特征组合泛化能力有限,后面我们谈到的 embedding column 则是通过构建离散特征的低维向量表示,强化离散特征的泛化能力。
(6)real valued column
real valued feature column 对应连续型数值特征,接口为
real_valued_column(column_name, dimension=1, default_value=None, dtype=dtypes.float32,normalizer=None):对应类为_RealValuedColumn:
_RealValuedColumn(column_name, dimension, default_value, dtype,normalizer)dimension 指定 feature column 的维度,默认值为 1,即 1 维浮点数数组。dimension 也可以取大于 1 的整数,对应多维数组。rea valued column 的特征取值类型可以是 float32 或者 int,int 类型在输入到模型之前会转换成 float 类型。normalizer 定义在一批训练样本实例中,特征在列维度的归一化,相当于 column-level normalization。这个同 sparse feature column 的 combiner 不同,combiner 定义的是离散特征在单个样本维度的归一化(example-level normalization),以下示意图举了个例子来说明两者的区别:
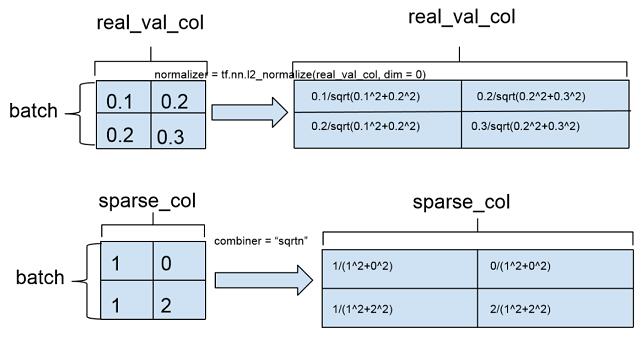
normalizer 在 real valued feature column 输入 DNN 时调用:
def insert_transformed_feature(self, columns_to_tensors):# Transform the input tensor according to the normalizer function.// _normalized_input_tensor 调用的是构造 real valued colum 时传入的 normalizer 函数input_tensor = self._normalized_input_tensor(columns_to_tensors[self.name])columns_to_tensors[self] = math_ops.to_float(input_tensor)
real valued column 调用_to_dnn_input_layer 转换为 DNN 的输入。_to_dnn_input_layer 生成一个二维数组,数组的每一行是一个训练样本的 real valued column 的特征值,该特征值与其他连续型特征拼接后构成 DNN 的输入层。
def _to_dnn_input_layer(self,input_tensor,weight_collections=None,trainable=True,output_rank=2):// DNN 的输入必须是 dense tensor,sparse tensor 需要调用 to_dense_tensor 转换成 dense tensorinput_tensor = self._to_dense_tensor(input_tensor)if input_tensor.dtype != dtypes.float32:input_tensor = math_ops.to_float(input_tensor)// 调用 dense_inner_flatten(input_tensor, output_rank)。// output_rank = 2,输出 [batch_size, real value column』s input dimension]return _reshape_real_valued_tensor(input_tensor, output_rank, self.name)def _to_dense_tensor(self, input_tensor):if isinstance(input_tensor, sparse_tensor_py.SparseTensor):default_value = (self.default_value[0] if self.default_value is not None else 0)// Sparse tensor 转换成 dense tensorreturn sparse_ops.sparse_tensor_to_dense(input_tensor, default_value=default_value)// real valued column 直接返回 input tensorreturn input_tensor
(7)bucketized column
连续型特征通过 bucketization 生成离散特征,连续特征离散化的优点在网上有一些相关讨论,比如餐馆的距离对用户选择的影响,我们通常会将距离划分为若干个区间,如 100 米以内,1 公里以内等,这样小幅度的距离差异不会对我们最终模型的预测造成太大影响,除非距离差异跨域了区间边界。bucketized column 的接口定义为:def bucketized_column(source_column, boundaries) 对应类为_BucketizedColumn,构造函数定义:def new(cls, source_column, boundaries):source_column 必须是 real_valued_column,boundaries 是一个浮点数的列表,而且列表必须是递增序的,比如 boundaries = [0, 100, 200] 定义了以下一组区间:(-INF,0),[0,100),[100,200),[200, INF)。
def insert_transformed_feature(self, columns_to_tensors):# Bucketize the source column.if self.source_column not in columns_to_tensors:self.source_column.insert_transformed_feature(columns_to_tensors)columns_to_tensors[self] = bucketization_op.bucketize(columns_to_tensors[self.source_column],boundaries=list(self.boundaries), name="bucketize")
bucketize 函数调用 tensorflow c++ core library 中的 BucketizeOp 类完成 feature 的 bucketization 功能。
(8)embedding column
sparse feature column 通过 embedding 转换成连续型向量后可以作为 deep model 的输入,前面谈到了 cross column 的一个不足之处是在测试集合的泛化能力,通过 embedding column 将离散特征连续化,根据标注学习特征的向量形式,如同矩阵分解中学习物品的隐含因子向量或者词向量模型中单词的词向量。embedding column 的接口形式是:
def embedding_column(sparse_id_column, dimension, combiner=None, initializer=None, ckpt_to_load_from=None,tensor_name_in_ckpt=None, max_norm=None, trainable=True)
对应类为_EmbeddingColumn:
def __new__(cls,sparse_id_column,dimension,combiner="mean",initializer=None, ckpt_to_load_from=None,tensor_name_in_ckpt=None,shared_embedding_name=None, shared_vocab_size=None,max_norm=None,trainable = True):
sparse_id_column 是 SparseColumn 对象或者 WeightedSparseColumn 对象,dimension 是 embedding column 的向量维度。SparseColumn 的每个特征取值对应一个整数 id,该整数 id 在 embedding column 中对应一个 dimension 维度的浮点数向量。combiner 参数指定在单个样本上对特征向量归一化的方式,initializer 参数指定特征向量的初始化函数,默认按 truncated normal distribution 初始化 (mean = 0, stddev = 1/ sqrt(length of sparse id column))。max_norm 限定每个样本特征向量做 L2 归一化后的最大值:embedding_vector = embedding_vector * max_norm / L2_norm(embedding_vector)。
为了进一步理解 embedding column,我们可以画一个简易图:
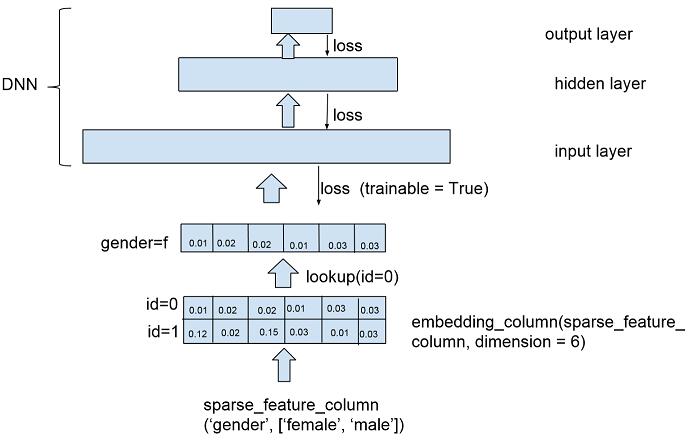
如上图,以 sparse_column_with_keys(column_name = 『gender』, keys = [『female』, 『male』]) 为例,假设 female 对应 id = 0, male 对应 id = 1,每个 id 在 embedding feature 中对应 1 个 6 维的浮点数向量。在实际训练数据中,当 gender 特征取值为』female』时,给到 DNN 输入层的将是 id = 0 对应的向量(tf.embedding_lookup_sparse)。embedding_column 设置了一个 trainable 参数,指定是否根据模型训练误差更新特征对应的 embedding。
embedding 特征的变换函数:
def insert_transformed_feature(self, columns_to_tensors):if self.sparse_id_column not in columns_to_tensors:self.sparse_id_column.insert_transformed_feature(columns_to_tensors)columns_to_tensors[self] = columns_to_tensors[self.sparse_id_column]def _deep_embedding_lookup_arguments(self, input_tensor):return _DeepEmbeddingLookupArguments(input_tensor=self.sparse_id_column.id_tensor(input_tensor),// sparse_id_column 为_SparseColumn 类型的对象时,weight_tensor = None// sparse_id_column 为_WeightedSparseColumn 类型对象时,weight_tensor = WeihgtedSparseColumn 的// weight tensor,weight_tensor 须满足:// 1)weight_tensor.indices = input_tensor.indices// 2)weight_tensor.shape = input_tensor.shapeweight_tensor=self.sparse_id_column.weight_tensor(input_tensor),// sparse feature column 的元素个数vocab_size=self.length,// embedding 的维度dimension=self.dimension,// embedding 的初始化函数initializer=self.initializer,// embedding 的行归一化方法combiner=self.combiner,shared_embedding_name=self.shared_embedding_name,hash_key=None,max_norm=self.max_norm,trainable=self.trainable)
从_DeepEmbeddingLookupArguments 产生 sparse feature 的 embedding 的逻辑在函数_embeddings_from_arguments 实现:
def _embeddings_from_arguments(column, args, weight_collections,trainable, output_rank=2):// column 对应 embedding feature column 的 name,args 是 feature column 对应的// _DeepEmbeddingLookupArguments 对象,weight_collections 存储 embedding 的权重,// output_rank 指定输出 embedding 的 tensor 的 rank。input_tensor = layers._inner_flatten(args.input_tensor, output_rank)weight_tensor = layers._inner_flatten(args.weight_tensor, output_rank)// 考虑默认情况下构建 embedding: args.hash_key is None, args.shared_embedding_name is None// 获取或创建 embedding 的 model variable// embeddings 是 [number of sparse feature id, embedding dimension] 的浮点数二维数组// 每行对应一个 sparse feature id 的 embeddingembeddings = contrib_variables.model_variable( name='weights',shape=[args.vocab_size, args.dimension], dtype=dtypes.float32,initializer=args.initializer,// If trainable, embedding vector 作为一个 model variable 添加到 GraphKeys.TRAINABLE_VARIABLES trainable=(trainable and args.trainable),collections=weight_collections // weight_collections 存储每个 feature id 的 weight)// 获取每个 sparse feature id 的 embeddingreturn embedding_ops.safe_embedding_lookup_sparse(embeddings, input_tensor,sparse_weights=weight_tensor, combiner=args.combiner, name=column.name + 'weights',max_norm=args.max_norm)
safe_embedding_lookup_sparse 调用 tf.embedding_lookup_sparse 获取每个 sparse feature id 的 embedding。
tf.embedding_lookup_sparse 首先调用 tf.embedding_lookup 获取 sparse feature id 的 embedding vector:
// sp_ids 是 input_tensor 的 id tensor
ids = sp_ids.valuesembeddings = embedding_lookup (// params 对应 embeddings 矩阵,每个元素是 embedding_dimension 的 float tensor,可以将 params 看// 做一个 embedding tensor 的 partitions,partition 的策略由 partition_strategy 指定params, // ids 对应 input_tensor 的 values 数组ids,// id 分配到 params 的分配策略,有 mod 和 div 两种,默认 mod,具体定义可参见 tf.embedding_lookup 的说明partition_strategy=partition_strategy, // 限制 embedding 的最大 L2-Normmax_norm=max_norm)
如果 sparse_weights 不是 None,embedding 的值乘以 weights,
weights = sparse_weights.values
embeddings *= weights
根据 combiner,对 embedding 进行归一化
segment_id = sp_ids.indices[;0]if combiner == "sum":// No normalizationembeddings = math_ops.segment_sum(embeddings, segment_ids, name=name)elif combiner == "mean":// L1 normlization: embeddings = SUM(embeddings * weight) / SUM(weight)embeddings = math_ops.segment_sum(embeddings, segment_ids)weight_sum = math_ops.segment_sum(weights, segment_ids)embeddings = math_ops.div(embeddings, weight_sum, name=name)elif combiner == "sqrtn":// L2 normalization: embeddings = SUM(embeddings * weight^2) / SQRT(SUM(weight^2))embeddings = math_ops.segment_sum(embeddings, segment_ids)weights_squared = math_ops.pow(weights, 2)weight_sum = math_ops.segment_sum(weights_squared, segment_ids)weight_sum_sqrt = math_ops.sqrt(weight_sum)embeddings = math_ops.div(embeddings, weight_sum_sqrt, name=name)(9)其他 feature columns
除了以上列举的几个 feature column,TensorFlow 还支持 one hot column,shared embedding column 和 scattered embedding column。one hot column 对 sparse feature column 进行 one-hot 编码,如果离散特征的取值较少,可以用 one hot feature column 进行编码用于 DNN 的训练。不同于 embedding column,one hot feature column 不支持通过模型训练来更新其特征的 embedding。shared embedding column 和 scattered embedding column 由于篇幅原因就不多谈了。
这篇关于TensorFlow Wide And Deep 模型详解与应用 TensorFlow Wide-And-Deep 阅读344 作者简介:汪剑,现在在出门问问负责推荐与个性化。曾在微软雅虎工作,的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





