本文主要是介绍树型结构构建,模糊查询,过滤,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、前言
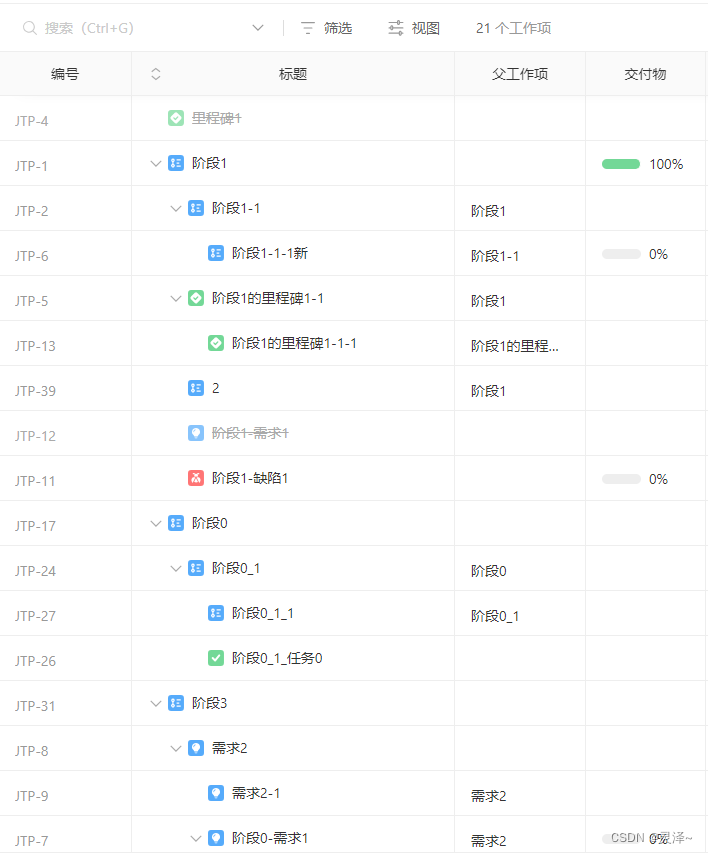
1、最近在做甘特图,有些需求和树型结构要求很大,看的是 pingCode,有搜索
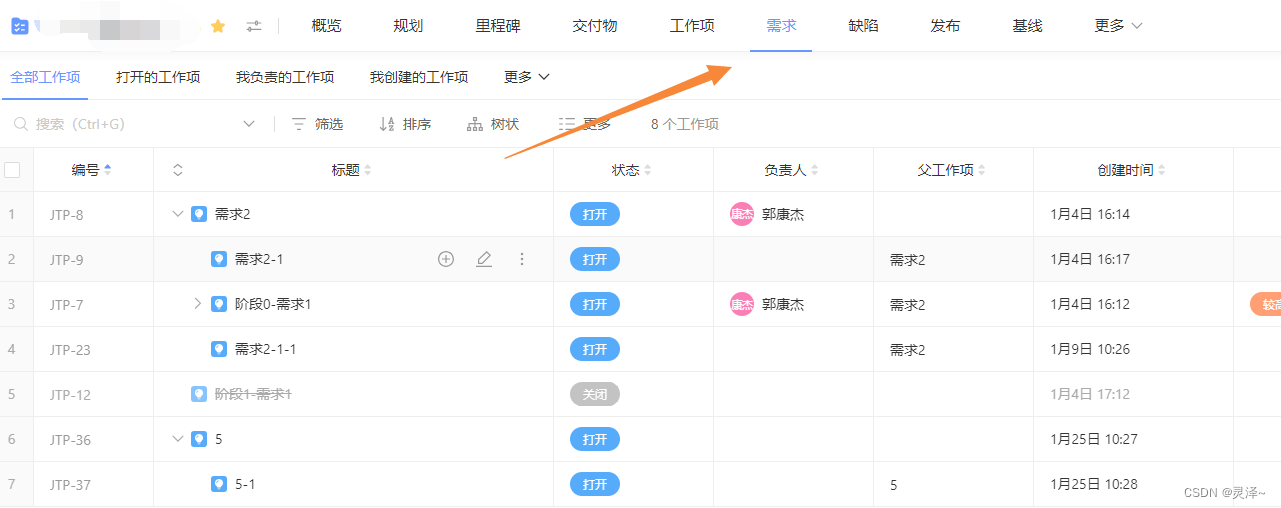
2、还有抽取一部分树型结构的,如下是抽取上面的结构类型为需求的,重新组成树型
二、构建多颗树型结构
1、某些业务下,从数据库查询出来一堆数据后,希望构建树型结构,但是存在一种情况就是,可能这堆数据不是完整的,比如如下情况,我查询出来了除了D节点外的所有数据,那么这种情况下,如果使用正常的构建方式,那么构建出来的数据会丢失数据H,I,J,M,即使这四个节点的数据已经查询出来了,但是因为D节点缺失,导致无法链接上,如果是中间断开了,那断开的部分单独成一个树型结构
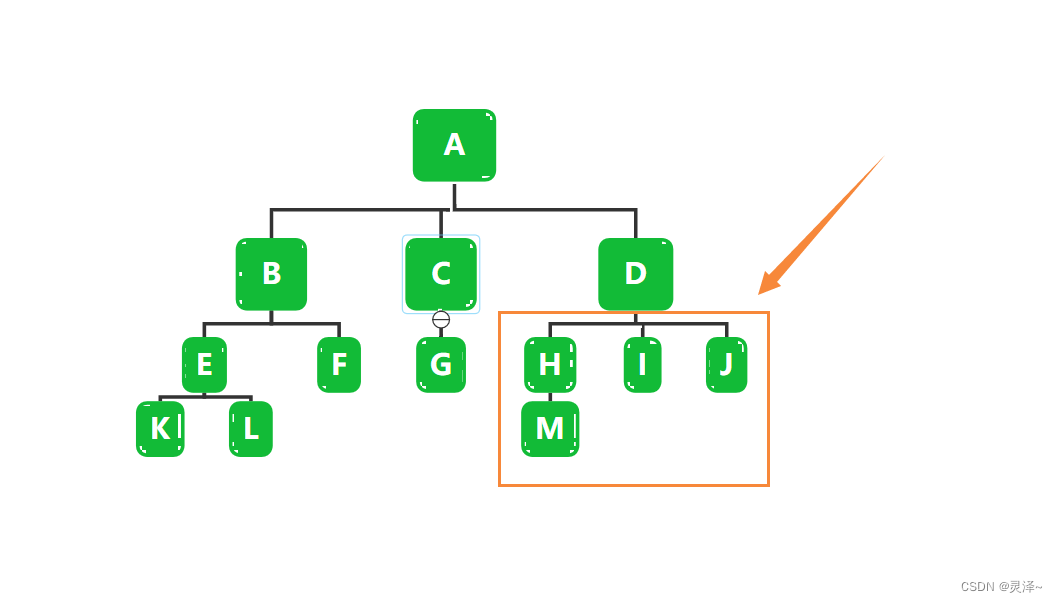
2、那有人说这不是正常的吗,你为啥D节点不查询出来,一颗完整的树是这样的啊,但是存在一些业务情况如下,上述的数据中除了D节点,其它节点的类型都是type1,而D节点的Type 是2,我现在就是想看type为1的,然后你给我形成树型结构
3、代码如下,其中模拟的时候,缺失节点999,所以结果如下,把节点999那一条结构,单独做一个树型结构返回,避免丢失

import cn.hutool.core.collection.CollUtil;
import com.alibaba.fastjson.JSON;import java.util.*;
import java.util.stream.Collectors;class ChildHandle {public static void main(String[] args) {List<Node> mockData = mockData();List<List<Node>> lists = buildTree(mockData, 50);System.out.println(JSON.toJSONString(lists));}public static List<List<Node>> buildTree(List<Node> data, int maxDepth) {List<List<Node>> multipleTopNodeTreeResult = new ArrayList<>();if (CollUtil.isEmpty(data)) {return multipleTopNodeTreeResult;}Map<Integer, List<Node>> moduleMap = new HashMap<>(32);// 找出所有的父节点,因为有些数据并不是一个完整的树型树,如果是中间断开了,那断开的部分单独成一个树型结构HashSet<Integer> rootIds = new HashSet<>();Set<Integer> allIds = data.stream().map(Node::getId).collect(Collectors.toSet());for (Node module : data) {moduleMap.putIfAbsent(module.getPid(), new ArrayList<>());moduleMap.get(module.getPid()).add(module);// 当前的item的pid对应的数据不存在,说明从当前的item的pid就断开了,则为这个pid单独起一颗树if (!allIds.contains(module.getPid())) {rootIds.add(module.getPid());}}// 根据上述的判断,已经知道存在几颗树,则为每颗树构建结构rootIds.forEach(curTopNodeId -> {// 处理每一颗树List<Node> treeInCurTopNode = moduleMap.get(curTopNodeId);if (treeInCurTopNode != null) {// Sort root modulestreeInCurTopNode.sort(Comparator.comparingInt(Node::getSerialNumber));for (Node rootModule : treeInCurTopNode) {buildChildren(rootModule, moduleMap, 0, maxDepth);}} else {treeInCurTopNode = new ArrayList<>();}multipleTopNodeTreeResult.add(treeInCurTopNode);});return multipleTopNodeTreeResult;}private static void buildChildren(Node parentModule, Map<Integer, List<Node>> moduleMap, int depth, int maxDepth) {if (depth >= maxDepth) {// 达到深度限制,停止递归return;}List<Node> children = moduleMap.get(parentModule.getId());if (children != null) {// Sort childrenchildren.sort(Comparator.comparingInt(Node::getSerialNumber));parentModule.setChildren(children);for (Node child : children) {// 增加深度计数 限制最多递归多少次,避免OOMbuildChildren(child, moduleMap, depth + 1, maxDepth);}}}/*** 模拟数据** @return*/private static List<Node> mockData() {List<Node> result = new ArrayList<>();result.add(new Node(1, 0, "Root1"));result.add(new Node(2, 1, "Root1 A"));result.add(new Node(3, 1, "Root1 B"));result.add(new Node(4, 2, "Root1 A.1"));result.add(new Node(5, 2, "Root1 A.2"));result.add(new Node(6, 3, "Root1 B.1"));result.add(new Node(7, 3, "Root1 B.2"));result.add(new Node(8, 3, "Root1 C"));result.add(new Node(9, 8, "Root1 D"));result.add(new Node(1000, 0, "Root2"));result.add(new Node(1001, 1000, "Root2 A"));result.add(new Node(1002, 1000, "Root2 B"));return result;}
}class Node {private Integer id;/*** 父id,为0时说明自己就是第一层*/private Integer pid;/*** 名称*/private String name;/*** 排序*/private int serialNumber;/*** 子集*/private List<Node> children;public Integer getPid() {return pid;}public void setPid(Integer pid) {this.pid = pid;}public String getName() {return name;}public void setName(String name) {this.name = name;}public List<Node> getChildren() {return children;}public void setChildren(List<Node> children) {this.children = children;}public Integer getId() {return id;}public void setId(Integer id) {this.id = id;}public int getSerialNumber() {return serialNumber;}public void setSerialNumber(int serialNumber) {this.serialNumber = serialNumber;}public Node(Integer id, Integer pid, String name) {this.id = id;this.pid = pid;this.name = name;}public Node(Integer id, Integer pid, String name, int serialNumber, List<Node> children) {this.id = id;this.pid = pid;this.name = name;this.serialNumber = serialNumber;this.children = children;}
}
三、树型结构查询过滤
1、方法如下,其中存在一种情况就是查询到父节点满足过滤条件后,那么需不需要判断其子节点是否满足条件,如果不需要注释那段代码即可,如果需要接着往下判断则需要加上
/*** 树型查询** @param tree 树型集合* @param key 搜索的字段名称* @param value 搜索的值* @param childNodeName 子节点名称* @param <T> 数据具体对象* @return tree*/public <T> List<T> filterTree(List<T> tree, Function<JSONObject, Boolean> filterCondition, String childNodeName) {// 这个方法的原始文章 https://blog.csdn.net/weixin_44748212/article/details/131692471// 如果要保留子节点的话把注释的(// 去除子节点start - end )这段代码删掉即可if (CollUtil.isEmpty(tree)) {return new ArrayList<>();}
// JSONArray arr = JSONArray.parseArray(JSON.toJSONString(tree)); //如果直接序列化,时间格式是 时间戳了JSONArray arr = JSONArray.parseArray(JSON.toJSONStringWithDateFormat(tree, DatePattern.NORM_DATETIME_PATTERN));JSONArray result = filterTree(arr, filterCondition, childNodeName);Type listType = new TypeReference<List<T>>() {}.getType();return JSON.parseObject(result.toJSONString(), listType);}private JSONArray filterTree(JSONArray tree, Function<JSONObject, Boolean> filterCondition, String childNodeName) {Iterator<Object> it = tree.iterator();while (it.hasNext()) {JSONObject current = (JSONObject) it.next();// 把当前节点给到外部,让外部判断是否满足条件if (Boolean.TRUE.equals(filterCondition.apply(current))) {// 去除子节点 startJSONArray childNodes = current.getJSONArray(childNodeName);if (!CollUtil.isEmpty(childNodes)) {JSONArray filterTree = filterTree(childNodes, filterCondition, childNodeName);if (CollUtil.isEmpty(filterTree)) {current.put(childNodeName, new JSONArray());}}// 去除子节点 endcontinue;}JSONArray childNodes = current.getJSONArray(childNodeName);if (!CollUtil.isEmpty(childNodes)) {filterTree(childNodes, filterCondition, childNodeName);}if (CollUtil.isEmpty(childNodes)) {it.remove();}}return tree;}
2、使用方式
List<ListDto> curTreeFilterResult = filterTree(curTree, currentNode -> {String titleValue = currentNode.getString("title");int serialNumber = currentNode.getIntValue("serialNumber");return StrUtil.contains(titleValue, params.getQuery())|| StrUtil.contains(dbDevmProjectInfo.getIdentifier().concat("-" + serialNumber), params.getQuery());}, "children");if (CollUtil.isNotEmpty(curTreeFilterResult)) {filterTreeResult.add(curTreeFilterResult);}
这篇关于树型结构构建,模糊查询,过滤的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








