本文主要是介绍营销活动探索性数据分析的机器学习成本预测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

关于该项目 (About the project)
The dataset stores information — 2008 to 2015 — of a marketing sales operation (telemarketing) implemented by a Portuguese bank’s marketing team to attract customers to subscribe term deposits, classifying the results as ‘yes’ and ‘no’ into a binary categorical variable.
该数据集存储了葡萄牙银行营销团队实施的营销销售业务(电话营销)的信息(2008年至2015年),以吸引客户认购定期存款,并将结果分为“是”和“否”分类为二进制分类变量。
Until that time, the strategy was to reach the maximum number of clients, indiscriminately, and try to sell them the financial product over the phone. However, that approach, besides spending many resources was also very uncomfortable for many clients disturbed by this type of action.
在此之前,策略是不加选择地吸引最大数量的客户,并尝试通过电话向他们出售金融产品。 但是,这种方法除了花费很多资源之外,对于许多受此类操作困扰的客户来说也非常不舒服。
To determine the costs of the campaign, the marketing team has concluded:
为了确定广告系列的费用,营销团队得出以下结论:
For each customer identified as a good candidate and therefore defined as a target but doesn’t subscribe the deposit, the bank had a cost of 500 EUR.
对于每个被确定为良好候选人并因此被定义为目标客户但不选择支付押金的客户,银行的成本为500欧元 。
For each customer identified as a bad candidate and excluded from the target but would subscribe the product, the bank had a cost of 2.000 EUR.
对于每个被识别为不良候选人并被排除在目标之外但愿意订购该产品的客户,银行的成本为2.000欧元 。
机器学习的问题和目标 (Machine Learning problem and objectives)
We’re facing a binary classification problem. The goal is to train the best machine learning model that should be able to predict the optimal number of candidates to be targeted in order to reduce to the minimum costs and maximize efficiency.
我们正面临一个二进制分类问题 。 目标是训练最佳的机器学习模型,该模型应能够预测要针对的候选候选人的最佳数量,以便将成本降至最低并实现最大效率。
项目结构 (Project structure)
The project divides into three categories:
该项目分为三类:
EDA: Exploratory Data Analysis
EDA:探索性数据分析
Data Wrangling: Cleaning and Feature Engineering
数据整理:清洁和功能工程
Machine Learning: Predictive Modelling
机器学习:预测建模
In this article, I’ll be focusing only on the first section, the Exploratory Data Analysis (EDA).
在本文中,我将仅关注第一部分,即探索性数据分析 (EDA)。
绩效指标 (Performance Metric)
The metric used for evaluation is the total costs since the objective is to determine the minimum costs of the campaign.
用于评估的指标是总成本,因为目标是确定广告活动的最低成本。
You will find the entire code of this project here.The ‘bank_marketing_campaign.csv’ dataset can be downloaded here.
您可以在这里找到该项目的全部代码。“ bank_marketing_campaign.csv”数据集可以在此处下载。
The first thing to do is to import the libraries and dependencies required.
首先要做的是导入所需的库和依赖项。
# import librariesimport pandas as pd
from pandas.plotting import table
import numpy as np
import seaborn as sns
import scipy.stats
import matplotlib.pyplot as plt
%matplotlib inlineLoading the dataset (I will assign it as ‘df’) and inspect the first rows.
加载数据集(我将其分配为“ df”)并检查第一行。
df = pd.read_csv('bank_marketing_campaign.csv') # load the datasetdf.head() # print the data
head() is a method used to display the first 'n' rows in a dataframe and head()是一种用于显示数据帧中前“ n”行,而 tail() for the 'n' last rows tail()用于显示“ n”行的方法 The dependent variable or target (on the right as the last column) labeled as ‘y’ is a binary categoric variable. Let’s start by converting it into a binary numeric wich will assume the value of 1 if the client subscribes and 0 if otherwise. A new column ‘target’ will replace the ‘y’ (to be dropped).
标为“ y”的因变量或目标(在最后一列的右侧)是二进制类别变量。 首先,将其转换为二进制数值,如果客户端订阅,则将假定值为1;否则,则假定值为0。 新列“目标”将替换“ y”(将被删除)。
# converting into a binary numeric variabledf['target'] = df.apply(lambda row: 1 if row["y"] == "yes" else 0, axis=1)
df.drop(["y"],axis=1,inplace=True)I will also rename some columns replacing the dots by underscores.
我还将重命名一些用下划线替换点的列。
# Renaming some columns for better typing and calling variablesdf.rename(columns={"emp.var.rate":"emp_var_rate", "cons.price.idx":"cons_price_idx", "cons.conf.idx":"cons_conf_idx", "nr.employed":"nr_employed"}, inplace=True)df.head()
数据集的基本信息 (Basic info of the dataset)
- How many features are available? 有多少功能可用?
- How many clients are in the dataset? 数据集中有多少个客户?
- Are there any duplicated records? 是否有重复的记录?
- How many clients subscribed to the term deposit and how many didn’t? 有多少客户订阅了定期存款,有多少没有订阅?
# Printing number of observations, variables including the target, and duplicate samplesprint(f"Number of clients: {df.shape[0]}")
print(f"Number of variables: {df.shape[1]} incl. target")
print(f"Number of duplicate entries: {df.duplicated().sum()}")Number of clients: 41188Number of variables: 16 incl. targetNumber of duplicate entries: 5853
客户数量:41188变量数量:16 incl。 target重复条目数:5853
I must conclude that these apparent duplicated samples are actually from people with an identical profile.
我必须得出结论,这些明显重复的样本实际上是来自具有相同特征的人。
# How many clients have subscribed and how many didn't?absolut = df.target.value_counts().to_frame().rename(columns={"target":"clients"})
percent = (df.target.value_counts(normalize=True) *100).to_frame().rename(columns={"target":"%"})
df_bal = pd.concat([absolut,percent],axis=1).round(decimals=2)
print(f"[0] Number of clients that haven't subscribed the term deposit: {df.target.value_counts()[0]}")
print(f"[1] Number of clients that have subscribed the term deposit: {df.target.value_counts()[1]}")
display(df_bal)absolut.plot(kind='pie', subplots=True, autopct='%1.2f%%',
explode= (0.05, 0.05), startangle=80,
legend=False, fontsize=12, figsize=(14,6));数据集高度不平衡: (The dataset is highly imbalanced:)
[0] Number of clients that haven’t subscribed the term deposit: 36548[1] Number of clients that have subscribed the term deposit: 4640
[0]未订阅定期存款的客户数量:36548 [1]未订阅定期存款的客户数量:4640

探索性数据分析(EDA) (Exploratory Data Analysis (EDA))
Let’s now check the type of variables, missing values, and correlations as well as displaying statistical descriptions.
现在,让我们检查变量的类型,缺失值和相关性,并显示统计描述。
# Type of variables
df.dtypes.sort_values(ascending=True)age int64
pdays int64
previous int64
target int64
emp_var_rate float64
cons_price_idx float64
cons_conf_idx float64
euribor3m float64
nr_employed float64
job object
marital object
education object
default object
housing object
loan object
poutcome object
dtype: object# Counting variables by type
df.dtypes.value_counts(ascending=True)int64 4
float64 5
object 7
dtype: int64# Detecting missing values
print(f"Are there any missing values? {df.isnull().values.any()}")Are there any missing values? False# Visualization of correlations (heatmap)
mask = np.triu(df.corr(), 1)
plt.figure(figsize=(19, 9))
sns.heatmap(df.corr(), annot=True, vmax=1, vmin = -1, square=True, cmap='BrBG', mask=mask);
Variables 'emp_var_rate', 'nr_employed', 'euribor3m' are very redundant. 'nr_employed' is the most correlated with the target.
变量'emp_var_rate' , 'nr_employed'和'euribor3m'非常冗余。 'nr_employed'与目标最相关。
To have a clear and more accurate sense of the present data I will be displaying general stats.
为了清楚,准确地了解当前数据,我将显示常规统计信息。
# General stats of numeric variables adding 'variance' valuesdescribe = df.describe()
describe.append(pd.Series(df.var(), name='variance'))
Age: the youngest client has 17 years old and the oldest has 98 years with a median of 38 years whereas the average is 40 years old. The distribution is skewed to the left. This possibly indicates the presence of outliers.
年龄 :最小的客户年龄为17岁,最大的客户年龄为98岁,平均年龄为38岁,而平均年龄为40岁。 分布偏向左侧。 这可能表明存在异常值。
Pdays: number of days that passed by after the client was last contacted from a previous campaign. The majority of the clients have the 999 number which indicates most people did not contact nor were contacted by the bank. Those 999 are considered to be 'out of range' values.
Pdays :上一次广告系列中与客户最后一次联系之后经过的天数。 大多数客户的999号码表明大多数人没有联系过银行,也没有联系过银行。 那些999被认为是“超出范围”的值。
Previous: number of contacts performed before this campaign for each client. The vast majority were never been contacted before.
上一个 :此活动之前为每个客户执行的联系数量。 绝大多数人以前从未联系过。
Emp_var_rate: employment variation rate. During the period the index varied from [-3.4, 1.4].
Emp_var_rate :就业变化率。 在此期间,该指数从[-3.4,1.4]变化。
Cons_price_idx: the consumer price index varied from [92.2, 94.8].
Cons_price_idx :消费者价格指数从[ 92.2,94.8 ]起变化。
Cons_conf_idx: the consumer confidence level during that period kept always negative with a range of variation of [-51, -27]. These negative values might be explained by the recession that severely affected Portugal due to the financial global crisis during that same period the data was recorded.
Cons_conf_idx :在此期间,消费者信心水平始终保持为负,变化范围为[-51,-27]。 记录数据的同一时期,由于全球金融危机,衰退对葡萄牙造成了严重影响,这可以解释这些负值。
Euribor3m: there was a huge variation of the Euribor rate during the period of analysis [5% to 0.6%]. This fluctuation together with the negative confidence verified above reinforces the hypothesis that the data provides information from a crisis period.
Euribor3m :在分析期间,Euribor率存在巨大差异[5%至0.6%]。 这种波动以及上面验证的负置信度进一步强化了以下假设:数据可提供来自危机时期的信息。
Nr_employed: the number of employed people varied around 200 during the campaign.
Nr_employed :在竞选期间,就业人数变化了200人左右。
df.describe(include=['object']) # General stats of categoric variables
Job: there are 12 types of job recordings in which the administrative role is the most common with almost 10.5k of all clients.
职位 :有12种职位记录,其中管理角色最为常见,几乎所有客户中有10.5k。
Marital: the majority of clients are married with almost 25k records.
婚姻 :大多数客户已婚,拥有近25,000条记录。
Education: more than 12k people have a university degree.
教育程度 :超过12,000人具有大学学历。
Default: from all the 41.188 clients, 32.588 do not have any credit in default.
默认值 :在所有41.188个客户端中,32.588没有默认值。
Housing: almost half of the customers have a housing loan.
住房 :几乎一半的客户都有住房贷款。
Loan: almost 34k clients do not have any personal loans.
贷款 :将近34,000位客户没有任何个人贷款。
Poutcome: there is no information about the outcome of any previous marketing campaign.
成果 :没有关于任何先前营销活动结果的信息。
所有变量的统计描述 (Statistic description of all variables)
To be able to perform the analysis to both numeric and categoric variables, I will start by defining and creating a list of features separately by type of variable.
为了能够对数字变量和分类变量进行分析,我将首先根据变量类型定义和创建特征列表。
# creating indexescat_features = list(df.select_dtypes('object').columns)
int_features = list(df.select_dtypes('int64').columns)
float_features = list(df.select_dtypes('float64').columns)
num_features = int_features+float_featuresThe next step of the EDA process consists of providing a full description of all variables in the dataset starting with the numeric ones.
EDA流程的下一步包括对数据集中的所有变量(从数字变量开始)进行完整描述。
# Visualization of the numeric distributiondf[num_features].hist(figsize=(10,8), bins=25, xlabelsize=8, ylabelsize=8, alpha=0.9, grid=False)
plt.tight_layout();
Age (Age)
# creating a dataframe
stats_age = {'Designation': ['Value'],
'Variable': 'age',
'Description': 'clients` age',
'Type of variable': df.age.dtype,
'Type of distribution': 'continuous',
'Total observations': df.age.shape[0],
'Missing values': df.age.isnull().sum(),
'Unique values': df.age.nunique(),
'Min': df.age.min(),
'25%': int(df.age.quantile(q=[.25]).iloc[-1]),
'Median': df.age.median(),
'75%': int(df.age.quantile(q=[.75]).iloc[-1]),
'Max': df.age.max(),
'Mean': df.age.mean(),
'Std dev': df.age.std(),
'Variance': df.age.var(),
'Skewness': scipy.stats.skew(df.age),
'Kurtosis': scipy.stats.kurtosis(df.age)
}st_age = pd.DataFrame(stats_age, columns = ['Designation',
'Variable',
'Description',
'Type of variable',
'Type of distribution',
'Total observations',
'Missing values',
'Unique values',
'Min',
'25%',
'Median',
'75%',
'Max',
'Mean',
'Std dev',
'Variance',
'Skewness',
'Kurtosis'
])st_age.set_index("Designation", inplace=True)results = st_age.T # transposing the dataframe
resultsT = st_age
display(results)
It is very important to visualize the distribution and dispersion as follows.
如下显示分布和分散非常重要。
# Visualization of 'age'
# creating a distribution graph and bloxplot combinedage = df.age
np.array(age).mean()
np.median(age)f, (ax_box, ax_hist) = plt.subplots(2, sharex=True, gridspec_kw= {"height_ratios": (0.5, 2)})mean=np.array(age).mean()
median=np.median(age)sns.boxplot(age, ax=ax_box)
ax_box.axvline(mean, color='r', linestyle='--')
ax_box.axvline(median, color='g', linestyle='-')sns.distplot(age, ax=ax_hist)
ax_hist.axvline(mean, color='r', linestyle='--')
ax_hist.axvline(median, color='g', linestyle='-')plt.legend({'Mean':mean,'Median':median})
ax_box.set(xlabel='')plt.show()
Calculus of percentiles: 1%, 5%, 95%, 99%
百分位数的微积分:1%,5%,95%,99%
display(df.age.quantile(q=[.01, .05, .95, .99]))0.01 23.0
0.05 26.0
0.95 58.0
0.99 71.0
Name: age, dtype: float64To be able to visualize the variable against the target we must start by defining two groups: those clients who had to subscribe and those who hadn’t (let’s call them “Good” and “Bad” clients, respectively).
为了能够根据目标可视化变量,我们必须从定义两个组开始:必须订阅的客户端和没有订阅的客户端(分别称为“良好”和“不良”客户端)。
# Visualization variable vs. targetage_0 = df[df.target == 0].iloc[:,:1]
age_1 = df[df.target == 1].iloc[:,:1]a = np.array(age_0)
b = np.array(age_1)np.warnings.filterwarnings('ignore')plt.hist(a, bins=40, density=True, color="r", alpha = 0.6, label='Bad client')
plt.hist(b, bins=40, density=True, color="g", alpha = 0.6, label='Good client')plt.legend(loc='upper right')
plt.title('age', fontsize=14)
plt.xlabel('age')
plt.ylabel('absolute frequency');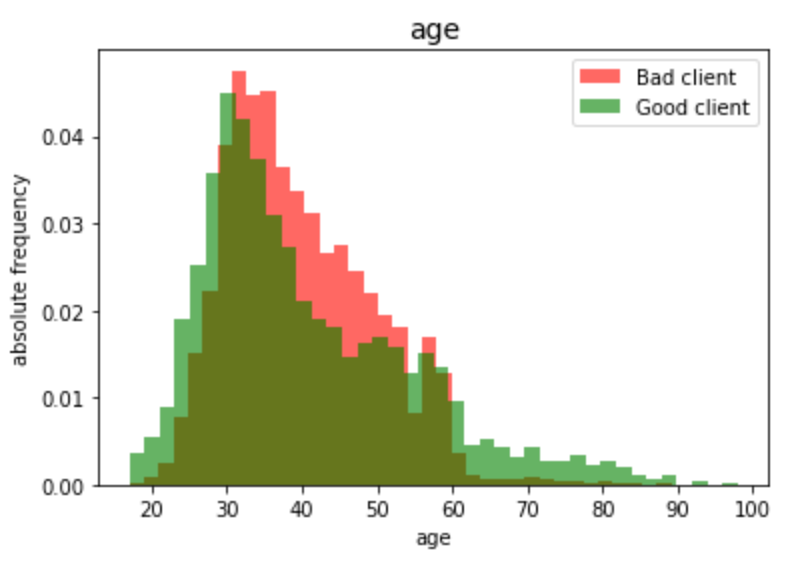
Proportionally there are more subscribers aged between less than 30 and more than 60 years old than between those from 30 to 60 years old.
按比例,年龄在30至60岁以上的订户比30至60岁之间的订户多。
Let’s take a step further and group the clients that subscribed, by age, in 3 buckets: young (<=30), adult (>30 to <=60), and senior (>60) using the cut method.
让我们更进一步,使用cut方法将订阅的客户按年龄划分为3个类别:年轻(<= 30),成人(> 30到<= 60)和高级(> 60)。
df['age_bins'] = pd.cut(df['age'], bins = [df['age'].min(), 30, 60, df['age'].max()],labels=['Young', 'Adult', 'Senior'])group_age_target = df.groupby(['age_bins'])['target'].mean().multiply(100)display(group_age_target)group_age_target.plot.barh()
plt.xlabel('Subscribed [%]');
- 45.5% of Seniors (+60 years old) subscribed to the term deposit. 45.5%的老年人(+60岁)订阅了定期存款。
- Less than 1 in 10 Adults (>30 and <=60 years old) subscribed. 不到十分之一的成年人(> 30岁且<= 60岁)订阅。
- Young people were the 2nd group that subscribed to the deposit corresponding to 1/6 of all young people. 年轻人是第二批订阅了相当于年轻人总数1/6的存款的人。
- Senior subscribers alone were almost as much as Young and Adults subscribers, respectively, all together. 仅高级订户就几乎分别相当于年轻订户和成人订户。
Pdays (Pdays)
Following the previous structure, I’ll be only displaying visuals for a greater understanding. The full code can be seen here.
按照先前的结构,我将仅显示视觉效果以供进一步了解。 完整的代码可以在这里看到。

Calculus of percentiles: 1%, 5%, 95%, 99%
百分位数的微积分:1%,5%,95%,99%
display(df.pdays.quantile(q=[.01, .05, .95, .99]))0.01 3.0
0.05 999.0
0.95 999.0
0.99 999.0
Name: pdays, dtype: float64Next, visualizing the distribution of the data and also the variable against the target.
接下来,可视化数据的分布以及针对目标的变量。

Considering only the clients who had to subscribe, let’s count the days that passed by after contact from a previous campaign. Most of the people will respond on the 6th day as well as within 7 to 8 days, you can observe below.
仅考虑必须订阅的客户,让我们计算上一个广告系列联系后经过的天数。 大多数人会在第6天以及7到8天内做出回应,您可以在下面进行观察。
dummy = df.loc[(df['pdays']!=999) & (df['target'] == 1), 'pdays']
print('Median: {:.2}'.format(dummy.median()))
dummy.hist().grid(False)
plt.title('Histogram')
plt.xlabel('Couting days after contact \n for those who subscribed')
Previous (Previous)

Calculus of percentiles: 1%, 5%, 95%, 99%
百分位数的微积分:1%,5%,95%,99%
display(df.previous.quantile(q=[.01, .05, .95, .99]))0.01 0.0
0.05 0.0
0.95 1.0
0.99 2.0
Name: previous, dtype: float64
The graph below shows that the clients that were previously contacted have subscribed to the term deposit at a much higher rate.
下图显示了以前联系过的客户以更高的利率订购了定期存款。
Considering only clients that never got reached only 10% subscribed whereas clients that have been previously contacted twice and more the success of the campaign increased up to >45%.
考虑到只有从未达到目标的客户才订阅了10%,而以前曾联系过两次或更多次的客户则使广告系列的成功率增加了> 45%。
group = df.groupby(['previous'])['target'].mean().multiply(100)
group.plot.barh()
plt.xlabel('Subscribed [%]');print('How many people got previously contacted? {}'.format(df.loc[df['previous']!=0].shape[0]))print('How many people got contacted 7 times? {}'.format(df.loc[df['previous']==7, 'previous'].count()))print('How many people got previously contacted with success? {}'.format(df.poutcome.value_counts()[1]))print('How many people got previously contacted without success? {}'.format(df.poutcome.value_counts()[2]))- How many people got previously contacted? 5625 以前有多少人联系过? 5625
- How many people got contacted 7 times? 1 有多少人被联系了7次? 1个
- How many people got previously contacted with success? 4525 以前有多少人联系过成功? 4525
- How many people got previously contacted without success? 1373 先前有多少人没有成功联系? 1373

索引变量 (Indexes variables)
There are 4 macro rating variables, or economic indexes, present in the dataset: ‘emp_var_rate’, ‘cons_price_idx’, ‘cons_conf_idx’ and ‘euribor3m’.
数据集中存在4个宏观评级变量或经济指标: 'emp_var_rate' , 'cons_price_idx' , 'cons_conf_idx'和'euribor3m' 。
Let’s dig a bit further and briefly investigate their correlation and check if there are any trends or patterns between those indexes and also with each other against the target. To do that I must create a list only with these specific variables and display them side by side (pairplot method).
让我们进一步挖掘并简要研究它们的相关性,并检查这些指标之间以及针对目标彼此之间是否存在任何趋势或模式。 为此,我必须仅使用这些特定变量创建一个列表,并将它们并排显示(pairplot方法)。
Note: we will return to the correlation subject later on this project (but in another article) in the section Data Wrangling: Cleaning and Feature Engineering.
注意:我们将在本项目的稍后部分(但在另一篇文章中)返回相关主题,在数据整理:清洁和特征工程一节中。
# creating a list
idx_list = ["cons_price_idx", "cons_conf_idx", "euribor3m", "emp_var_rate", "target"]df[idx_list].corr()
We can see that euribor3m, cons_price_idx, and emp_Var_rate are highly correlated. Next, visualize the correlations between the indexes variables using the pairplot method.
我们可以看到euribor3m , cons_price_idx和emp_Var_rate高度相关。 接下来,使用pairplot方法可视化索引变量之间的相关性。
sns.pairplot(df[idx_list], hue="target")
plt.show()
What can we observe from the scatter plots? Please keep in mind that (blue) 0=NO and (orange) 1=YES
我们可以从散点图中观察到什么? 请记住,(蓝色)0 =否,(橙色)1 =是
euribor3mincreases when there is a positive variation ofemp_var_rate.当
euribor3m有正向变化时,emp_var_rate.cons_conf_idxvaries linearly withcons_price_idxandemp_var_rate: the higher the prices and rate of employment get, the lower the confidence level index becomes.cons_conf_idx随cons_price_idx和emp_var_rate线性变化:价格和就业率越高,置信度指数越低。when
emp_var_rate(employment rate) increasescons_price_idx(price index) also increases.emp_var_rate(就业率)增加时,cons_price_idx(价格指数)也增加。
Can the output of the campaign be affected by the indexes variables? The answer comes from the observation of the distribution plots.
广告活动的输出会受到index变量的影响吗? 答案来自对分布图的观察。
the lower the
euribor3mis, the higher the number of subscriptions.euribor3m越低,订阅数量越多。when the
cons_price_idx(consumer price index) increases there is a strong negative response from the clients' subscriptions.当
cons_price_idx(消费者价格指数)增加时,客户的订阅会产生强烈的负面响应。when the
emp_var_rate(the employment rate) is negative there is a higher positive response to the campaign.如果
emp_var_rate(就业率)为负,则对竞选活动的积极响应较高。
Nr_employed (Nr_employed)

Calculus of percentiles: 1%, 5%, 95%, 99%
百分位数的微积分:1%,5%,95%,99%
display(df.nr_employed.quantile(q=[.01, .05, .95, .99]))0.01 4963.6
0.05 5017.5
0.95 5228.1
0.99 5228.1
Name: nr_employed, dtype: float64
From the analysis, we have known that people that were contacted had higher rates of subscription. The above histogram shows that the first contacts were exclusively made to known clients resulting in a much more efficient campaign with a low number of employed people.
通过分析,我们知道联系的人的订阅率更高。 上面的直方图显示,最初的联系是专门针对已知客户的,从而可以在工作人员较少的情况下提高效率。
Let’s move on to the categoric variables description.
让我们继续进行分类变量描述。
工作 (Job)
‘Job’ has 12 unique values. There is a class labeled as ‘unknown’ considered a missing value (I’ll not do anything about missing values for the time being).
“作业”具有12个唯一值。 有一个标记为“未知”的类,被认为是缺失值(暂时不做任何关于缺失值的操作)。
stats_job = {'Designation': ['Value'],
'Variable': 'job',
'Description': 'type of job',
'Type of variable': df.job.dtype,
'Total observations': df.job.shape[0],
'Unique values': df.job.nunique(),
}st_job = pd.DataFrame(stats_job, columns = ['Designation',
'Variable',
'Description',
'Type of variable',
'Total observations',
'Unique values',
])st_job.set_index("Designation", inplace=True)results = st_job.T
resultsT = st_job
display(results)print(f"List of unique values: {df.job.unique()}")
How are the clients distributed concerning their jobs?
客户如何分配有关其工作的信息?
data_count = df['job'].value_counts().plot(kind='bar', figsize=(6,4), fontsize=12)
plt.title('Categorical variable \'job\'', fontsize=12)
plt.xlabel('Jobs')
plt.ylabel('Absolute frequency');
Below, we can find the absolute values (sum of jobs) and their proportions. The 5 most common jobs are enough to represent 80% of the data.
在下面,我们可以找到绝对值(工作总和)及其比例。 这5个最常见的作业足以代表80%的数据。
num_obs = df.job.value_counts()
num_o = pd.DataFrame(num_obs)
num_o.rename(columns={"job":"Freq abs"}, inplace=True)
num_o_pc = (df.job.value_counts(normalize=True) * 100).round(decimals=2)
num_obs_pc = pd.DataFrame(num_o_pc)
num_obs_pc.rename(columns={"job":"percent %"}, inplace=True)
n_obs = pd.concat([num_o,num_obs_pc], axis=1)display(n_obs)
job_0 = df[df.target == 0].iloc[:,1:2]
job_1 = df[df.target == 1].iloc[:,1:2]a = np.array(job_0)
b = np.array(job_1)np.warnings.filterwarnings('ignore')plt.hist(a, bins=40, color="r", alpha = 0.8, label='Bad client', align="left")
plt.hist(b, bins=40, color="g", alpha = 0.8, label='Good client', align="right")plt.legend(loc='upper right')
plt.title('job', fontsize=12)
plt.xlabel('Professional ocupation')
plt.xticks(rotation='vertical')
plt.ylabel('Absolute frequency');
The classes ‘admin.’, ‘blue-collar’, ‘technician’, ‘management’ and ‘ services’ are the jobs where most clients had to subscribe but in terms of proportion, ‘student’ and ‘retired’ are the most representative.
“管理员”,“蓝领”,“技术员”,“管理”和“服务”类别是大多数客户必须订阅的工作,但就比例而言,“学生”和“退休”是最具代表性的工作。
Below we see that ‘retired’ and ‘housemaid’ are the oldest clients and the ones who have accepted the subscription more than any of the other classes.
在下面,我们看到“退休”和“女佣”是最老的客户,并且比其他任何类别的客户都接受订阅。
type_pivot = df.pivot_table(
columns="target",
index="job",
values="age", aggfunc=np.mean)type_pivot.sort_values(by=["job"], ascending=True).plot(kind="bar", title=("Type of customer by professional occupation and age"), figsize=(6,4), fontsize = 12);
婚姻 (Marital)

‘Marital’ has 4 unique values. Bellow, the chart and table show us the dominant class is the ‘married’ people with 61% and the ‘divorced’ clients correspond to 11% of all clients.
“婚姻”具有4个唯一值。 在贝娄,图表向我们展示了占主导地位的阶层是“已婚”人士,占61%,而“离婚”客户占所有客户的11%。
# pie chart
df['marital'].value_counts(dropna=False).plot(kind='pie', figsize=(14,9), explode = (0.01, 0.01, 0.01, 0.01), autopct='%1.1f%%', startangle=120);# table
marital_obs = df.marital.value_counts()
marital_o = pd.DataFrame(marital_obs)
marital_o.rename(columns={"marital":"Freq abs"}, inplace=True)
marital_o_pc = (df.marital.value_counts(normalize=True) *100).round(decimals=2)
marital_obs_pc = pd.DataFrame(marital_o_pc)
marital_obs_pc.rename(columns={"marital":"percent %"}, inplace=True)
marital_obs = pd.concat([marital_o,marital_obs_pc], axis=1)
marital_obs

教育 (Education)
‘Education’ has 8 unique values. The top 4 education levels correspond to 80% of the data. Clients with 4 years basic or illiterate are the oldest and prone to subscribe to the product.
“教育”具有8个独特的价值。 排名前4位的教育水平对应80%的数据。 具有4年基本或不识字经验的客户年龄最大,并且倾向于订阅该产品。



默认 (Default)
With 3 unique values, the class ‘yes’ is meaningless, the variable is unexpressive and totally imbalanced.
具有3个唯一值的类“是”是没有意义的,该变量没有表现力并且完全不平衡。


住房 (Housing)
This variable has 3 unique values with the ‘unknown’, interpreted as a missing value, representing 2% of observations. The proportion of ‘yes’ and ‘no’ is very tight might reduce its predictive power.
此变量具有3个唯一值,“未知”值被解释为缺失值,占观察值的2%。 “是”和“否”的比例非常严格,可能会降低其预测能力。


贷款 (Loan)
Although, generally speaking, ‘Loan’ shows a high number of non-subscribers, this variable has some similarities with ‘housing’ in the sense that, proportionally, ‘yes’ and ‘no’ are very even. Once again, it might reduce its predictive power.
虽然通常来说,“贷款”显示出大量的非订户,但该变量与“住房”有一些相似之处,即“是”和“否”成比例。 再一次,它可能会降低其预测能力。


成果 (Poutcome)
Interesting fact: between the clients previously contacted from previous promotional campaigns that actually succeed, the majority subscribed this time.
有趣的事实:在先前从之前成功实现促销活动的客户那里获得联系之前,大多数客户这次都订阅了。


最常见的类别是什么? (What are the most common categories?)
The detailed analysis gave us a ton of information about the data, the customers, and the variables’ behavior. Let’s take an overview.
详细的分析为我们提供了有关数据,客户和变量行为的大量信息。 让我们来概述一下。
n = len(cat_features)
i=1
plt.figure(figsize=(16,14))for feature in df[cat_features]:
plt.subplot(round(n/2),round(n/3), i)
df[feature].value_counts().plot.bar()
plt.xticks(rotation=90)
plt.title(feature)
i+=1plt.tight_layout();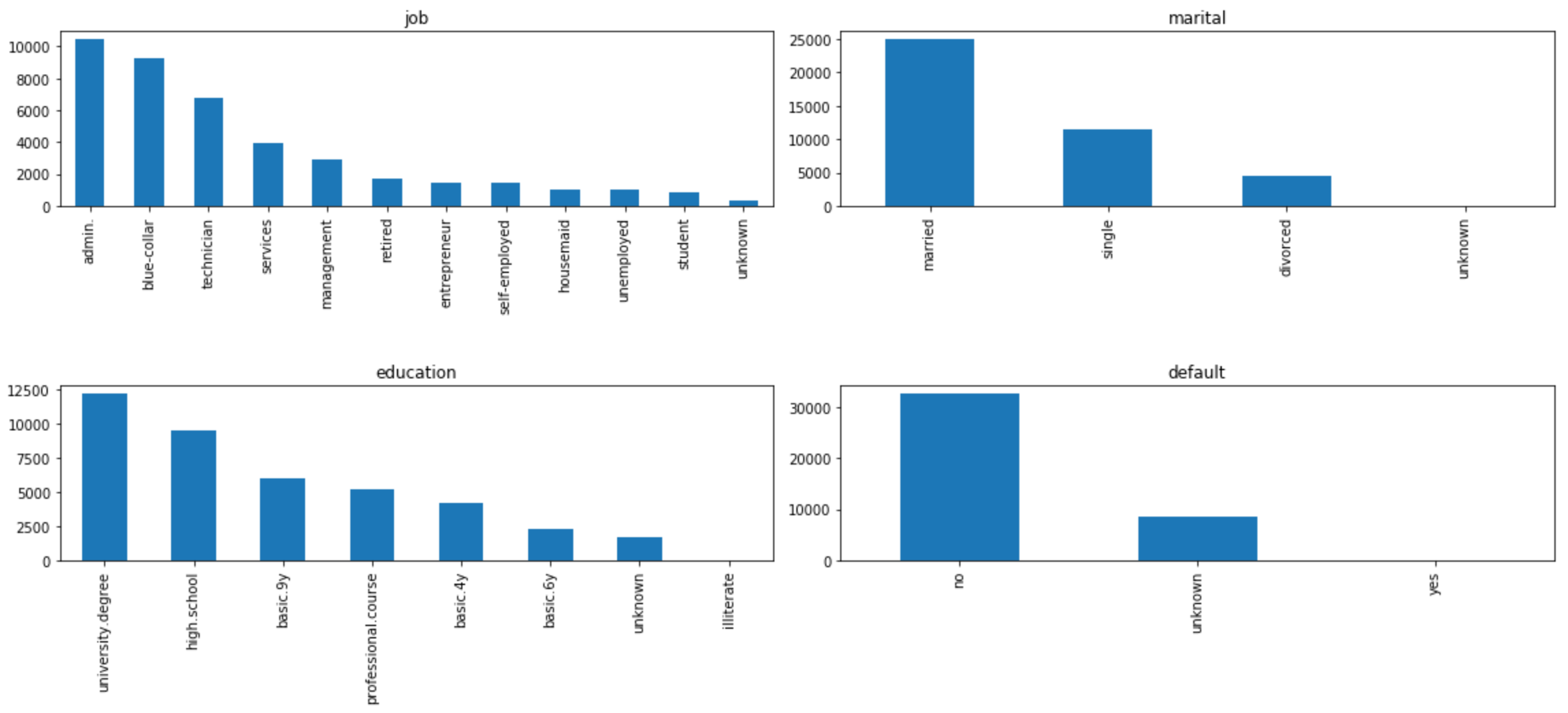

Most common:
最常见的:
- job: administrative 工作:行政
- marital state: married 婚姻状况:已婚
- education: university degree 学历:大学学历
- credit in default: no 违约信用:否
- housing: yes, however not having a housing loan is very close 住房:是的,但是没有住房贷款非常接近
- loan: no 贷款:无
- poutcome: did not participate in previous campaigns 提示:未参加之前的广告系列
Notice that all the features include the category ‘unknown’ except the ‘poutcome’ variable.
请注意,除“ poutcome”变量外,所有功能都包括“未知”类别。
这些类别如何影响目标变量? (How these categories influence the target variable?)
n = len(cat_features)
i=1
plt.figure(figsize=(16,14))for feature in df[cat_features]:
plt.subplot(round(n/2),round(n/3), i)
df.groupby([feature])['target'].mean().multiply(100).plot.barh()
plt.xlabel('Subscribed [%]')
plt.title(feature)
i+=1plt.tight_layout();

Observations:
观察结果:
- ‘Student’ and ‘retired’ have the highest percentage of subscriptions (>25%) whereas ‘blue-collar’ and ‘services’ have the lowest. “学生”和“退休”的订阅比例最高(> 25%),而“蓝领”和“服务”的订阅比例最低。
- ‘Illiterate’ people have the highest percentage of subscriptions (>20%), on the other hand ‘basic 9y’, ‘basic 6y’ and ‘basic 4y’ have the lowest. “文盲”用户的订阅比例最高(> 20%),而“基本9y”,“基本6y”和“基本4y”的订阅比例最低。
- People with credit in default did not subscribe. 拖欠信用额的人没有订阅。
- More than 60% of the people previously contacted to other campaigns subscribed. 以前与其他广告系列联系过的人中有60%以上订阅了该广告。
- Marital state, existence of loans, and housing do not influence much the subscription rate. 婚姻状况,贷款的存在和住房对预订率的影响不大。
结论 (Conclusion)
I’ve focused on how to begin a machine learning project starting by one of the most important parts which allow us to look beyond the data, the Exploratory Data Analysis. This is a very important procedure because if you don’t deeply understand the data you’re about to be dealing with, it will be a total mess.
我专注于如何从最重要的部分之一开始机器学习项目,该部分使我们能够查看数据之外的数据,即探索性数据分析。 这是一个非常重要的过程,因为如果您不深刻了解将要处理的数据,那将是一团糟。
In the next article (Data Wrangling) I’ll be doing feature engineering and feature selection, cleaning the dataset, and taking care of anomalies we might find along the way as well as imputations and transformations.
在下一篇文章(数据整理)中,我将进行特征工程和特征选择,清理数据集,并照顾沿途可能发现的异常以及插补和转换。
In the last part and third article (Machine Learning: Predictive Modelling) we are going to train some machine learning models to be able to choose the best one and find out the most important features in predicting the minimum costs for the marketing campaign.
在最后一部分和第三篇文章(机器学习:预测建模)中,我们将训练一些机器学习模型,以便能够选择最佳模型并找出最重要的功能,以预测营销活动的最低成本。
That’s it! I hope you enjoyed reading this article as much as I enjoyed writing it.
而已! 我希望您喜欢阅读这篇文章,也喜欢阅读它。
You can find the entire code of this project here.
您可以在此处找到该项目的完整代码。
联络人 (Contacts)
Linkedin
领英
Twitter
推特
Medium
中
GitHub
的GitHub
Kaggle
卡格勒
Email
电子邮件
Good readings, great codings!
好的读物,很好的编码!
翻译自: https://towardsdatascience.com/machine-learning-costs-prediction-of-a-marketing-campaign-exploratory-data-analysis-part-i-758b8f0ff5d4
相关文章:
这篇关于营销活动探索性数据分析的机器学习成本预测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








