本文主要是介绍前一百成绩分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、实施目的
基于考情,针对目标生制定学习成果“一生一案”方案,帮助目标生消灭短板学科,达到各科均衡发展。
二、实施方法
1、对年级总分科目总分排名前80的学生,制定“一生一案”
2、对标总分名次,设置单科合理区间,超出单科合理区间视为“薄弱学科”,并按名次划分不同档位
3、找出薄弱学科的责任老师
4、由各班班主任在班科联席会上,落实到人,安排到位
5、下次统考,进行成果考核
三、单科区间设置标准
总分前30名,单科合理区间为【总分名次,总分名次+20】
总分31至80名,单科合理区间为【总分名次,总分名次+30】
各单科合理区间往后A、B、C、D档区间长度分别设置为10、20、30、50,超出D档为E档
四、考核标准
下次统考目标生单科名次前进1挡,视为达标
前进2挡及以上,定为优秀
最后成果:
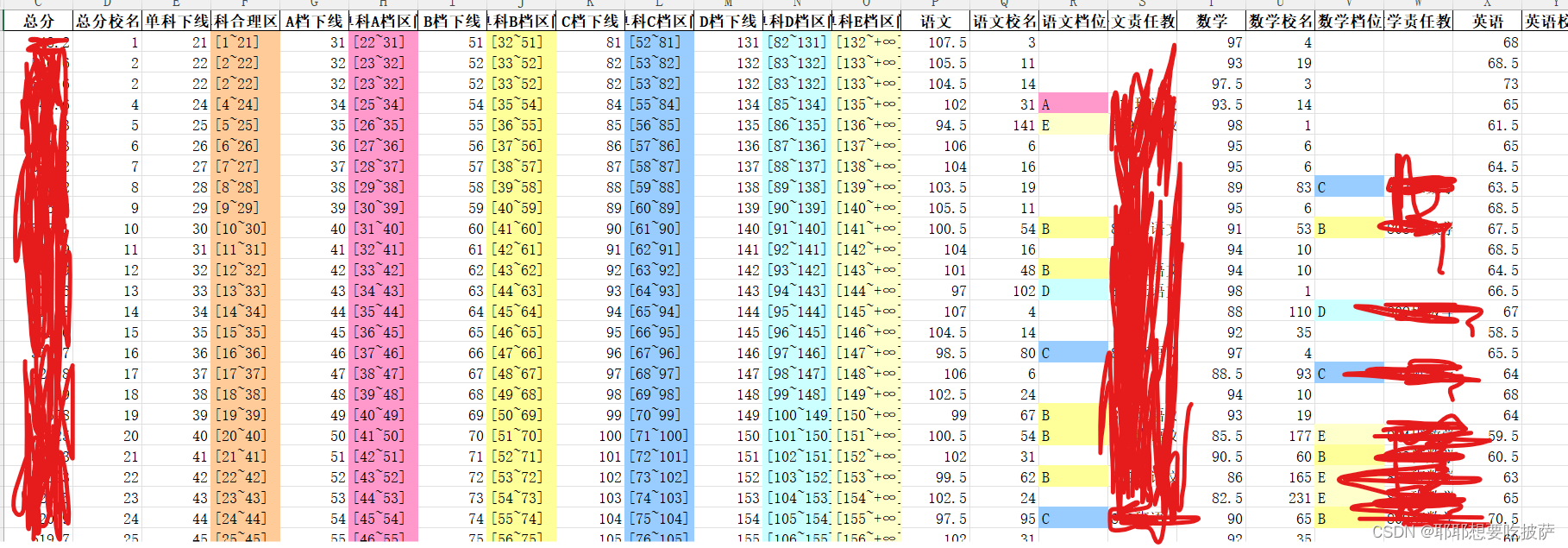
实现方式:
通过python代码实现:
1.下载vscode
通过腾讯应用里面可以下载
vscode下载地址
安装就ok了
2.下载安装python解释器
python 官网找到python 3.12.0版本下载安装(各个版本之间语法有些区别)
版本下载地址:https://www.python.org/ftp/python/3.12.0/python-3.12.0-amd64.exe
然后安装的时候勾选path
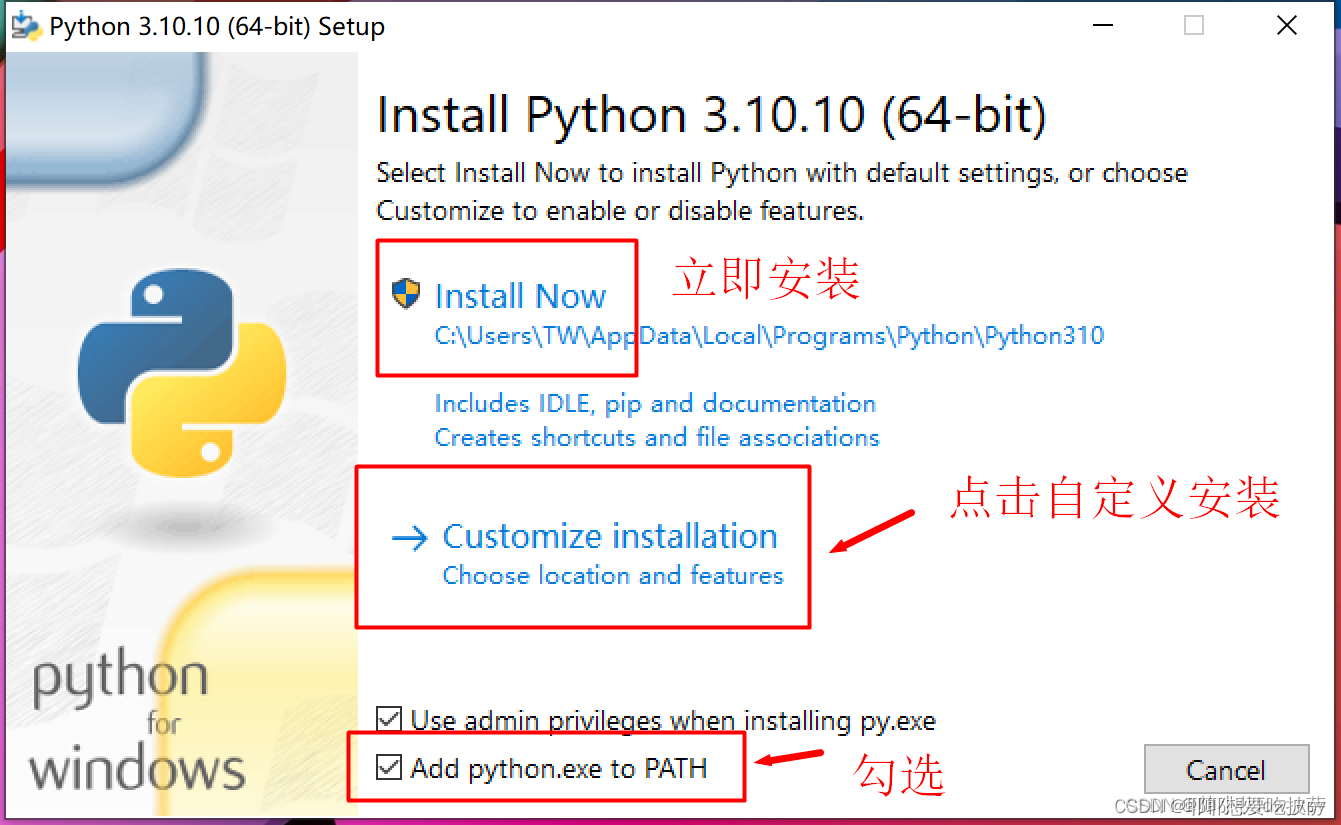
点击立即安装就好了,然后勾选Add python.exe to PATH
3.配置环境和库
同时按win+r
然后输入cmd
然后输入一下指令
pip install --upgrade pip -i https://pypi.tuna.tsinghua.edu.cn/simple some-packagepip install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple some-packagepip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple some-packagepip install openpyxl -i https://pypi.tuna.tsinghua.edu.cn/simple some-packagepip install jupyter -i https://pypi.tuna.tsinghua.edu.cn/simple some-package4.新建一个成绩分析文件夹
将他拖到vscode里面
5.在这个文件夹下新建一个前一百分析.ipynb文件
![]()
然后贴入代码:
import numpy as np
import pandas as pd
import os
import glob
from openpyxl import load_workbook
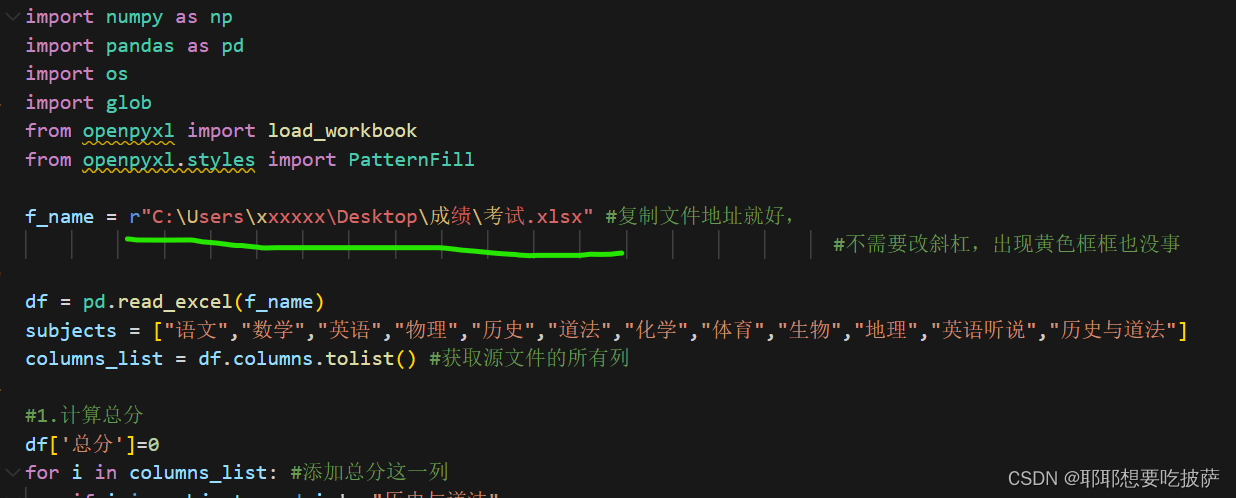
from openpyxl.styles import PatternFillf_name = r"C:\Users\xxxxxx\Desktop\成绩\考试.xlsx" #复制文件地址就好,#不需要改斜杠,出现黄色框框也没事df = pd.read_excel(f_name)
subjects = ["语文","数学","英语","物理","历史","道法","化学","体育","生物","地理","英语听说","历史与道法"]
columns_list = df.columns.tolist() #获取源文件的所有列#1.计算总分
df['总分']=0
for i in columns_list: #添加总分这一列if i in subjects and i != "历史与道法":df["总分"]=df['总分']+df[i] df = df.sort_values(by='总分',ascending=False)#提取生成新的dataframe
data = df[['班级','姓名','总分']][:100]
data['总分校名'] = data['总分'].rank(ascending=False,method='min').astype(int)#年级前三十单科下线位+20,剩下的单科下线为+30
data['单科下线'] = np.where(data["总分校名"]<=30,data['总分校名']+20,data['总分校名']+30)
data['单科合理区间'] = data.apply(lambda row:f"[{row['总分校名']}~{row['单科下线']}]",axis=1)
data['A档下线'] = data['单科下线']+10 #A
data['单科A档区间'] = data.apply(lambda row:f"[{row['单科下线']+1}~{row['A档下线']}]",axis=1)
data['B档下线'] = data['A档下线']+20 #B
data['单科B档区间'] = data.apply(lambda row:f"[{row['A档下线']+1}~{row['B档下线']}]",axis=1)
data['C档下线'] = data['B档下线']+30 #C
data['单科C档区间'] = data.apply(lambda row:f"[{row['B档下线']+1}~{row['C档下线']}]",axis=1)
data['D档下线'] = data['C档下线']+50 #D
data['单科D档区间'] = data.apply(lambda row:f"[{row['C档下线']+1}~{row['D档下线']}]",axis=1)
#E
data['单科E档区间'] = data.apply(lambda row:f"[{row['D档下线']+1}~+∞]",axis=1)
#
###单科档位比较获得
def compare_grade(row,subject):subject_grade = row[subject+"校名"]if subject_grade<=row["单科下线"]:return ""elif subject_grade>row["单科下线"] and subject_grade<=row["A档下线"]:return "A"elif subject_grade>row["A档下线"] and subject_grade<=row["B档下线"]:return "B"elif subject_grade>row["B档下线"] and subject_grade<=row["C档下线"]:return "C"elif subject_grade>row["C档下线"] and subject_grade<=row["D档下线"]:return "D"elif subject_grade>row['D档下线']:return "E"else:return ""
#
def single_subject_analysis(subject):if subject in subjects:data[subject] = df[subject]#获得语文成绩data[subject+'校名'] = data[subject].rank(ascending=False,method='min')#获得语文排名data[subject+"档位"] = data.apply(lambda row:compare_grade(row,subject),axis=1)data[subject+"责任教师"] = np.where(data[subject+"档位"]!="",data.apply(lambda row:f"{row["班级"]}班{subject}",axis=1),None)for i in columns_list:if i in subjects:single_subject_analysis(i)#-----------------------
result_folder = "数据处理文件夹"
os.makedirs(result_folder,exist_ok=True)
file_path = os.path.join(result_folder,"前一百全科.xlsx")
data.to_excel(file_path,index=False)
file_name = [file_path]
for i in columns_list:if i in subjects:single_df = data[["班级","姓名","总分","总分校名","单科合理区间","单科A档区间","单科B档区间","单科C档区间","单科D档区间","单科E档区间",i,i+"校名",i+"档位",i+"责任教师"]] filename = i+"单科分析.xlsx"file_path = os.path.join(result_folder,filename)single_df.to_excel(file_path,index=False)file_name.append(file_path)
#至此所有文件已经生成#对文件进行润色--------------
#----------------------------------------------------------------对列进行染色
def color_specific_column(file_path, color, column_name):workbook = load_workbook(filename=file_path)sheet = workbook.activeheader_row = next(sheet.iter_rows(min_row=1, max_row=1))column_index = Nonefor cell in header_row:if cell.value == column_name:column_index = cell.columnbreakif column_index is not None:for row in sheet.iter_rows(min_row=2): # 从第二行开始染色cell = row[column_index - 1] # 注意列索引从0开始,而列号从1开始cell.fill = PatternFill(start_color=color, end_color=color, fill_type="solid")workbook.save(filename=file_path)def process_excel_files_with_columns(folder_path, color, column_names):file_paths = glob.glob(os.path.join(folder_path, "*.xlsx"))for file_path in file_paths:for i in range(len(column_names)):color_specific_column(file_path, color, column_names[i])# 示例用法
folder_path = r"C:\Users\xxxxxx\Desktop\成绩\数据处理文件夹" # 文件夹路径
column_names = ["单科合理区间", "单科A档区间", "单科B档区间", "单科C档区间", "单科D档区间", "单科E档区间"]
colors = ["00FFCC99","00FF99CC","00FFFF99","0099CCFF","00CCFFFF","00FFFFCC"]
for i in range(6):process_excel_files_with_columns(folder_path, colors[i], [column_names[i]])#--------------------------------------------------------------------------对字母进行染色
def color_specific_columns(file_path, colors):workbook = load_workbook(filename=file_path)sheet = workbook.activetarget_values = ["A", "B", "C", "D", "E"]for row in sheet.iter_rows():for cell in row:if cell.value in target_values:fill_color = colors[target_values.index(cell.value) % len(colors)]cell.fill = PatternFill(start_color=fill_color, end_color=fill_color, fill_type="solid")workbook.save(filename=file_path)def process_excel_files_with_columns(folder_path, colors):file_paths = glob.glob(os.path.join(folder_path, "*.xlsx"))for file_path in file_paths:color_specific_columns(file_path, colors)# 示例用法
folder_path = r"C:\Users\lxxxxxx\Desktop\成绩\数据处理文件夹" # 文件夹路径
colors = ["00FF99CC","00FFFF99","0099CCFF","00CCFFFF","00FFFFCC"]
process_excel_files_with_columns(folder_path, colors)6.修改细节
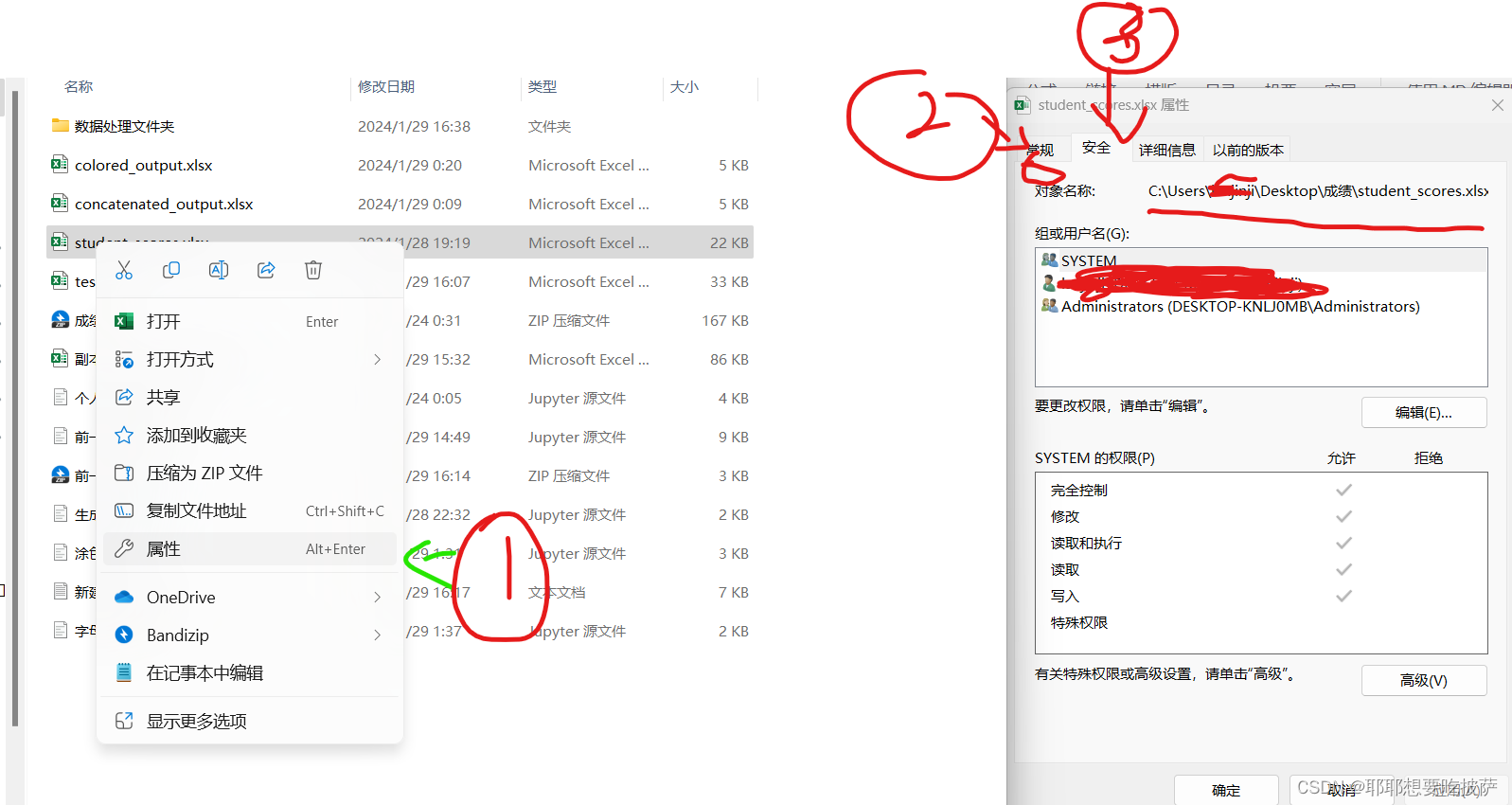
将这个地址复制为你要分析的excel文件,例如
win11电脑如下
win10电脑如下
粘贴上去就好了
excel表格要求如下:

长这样的就ok了,每个都是一列
7.涂色方面的文件夹
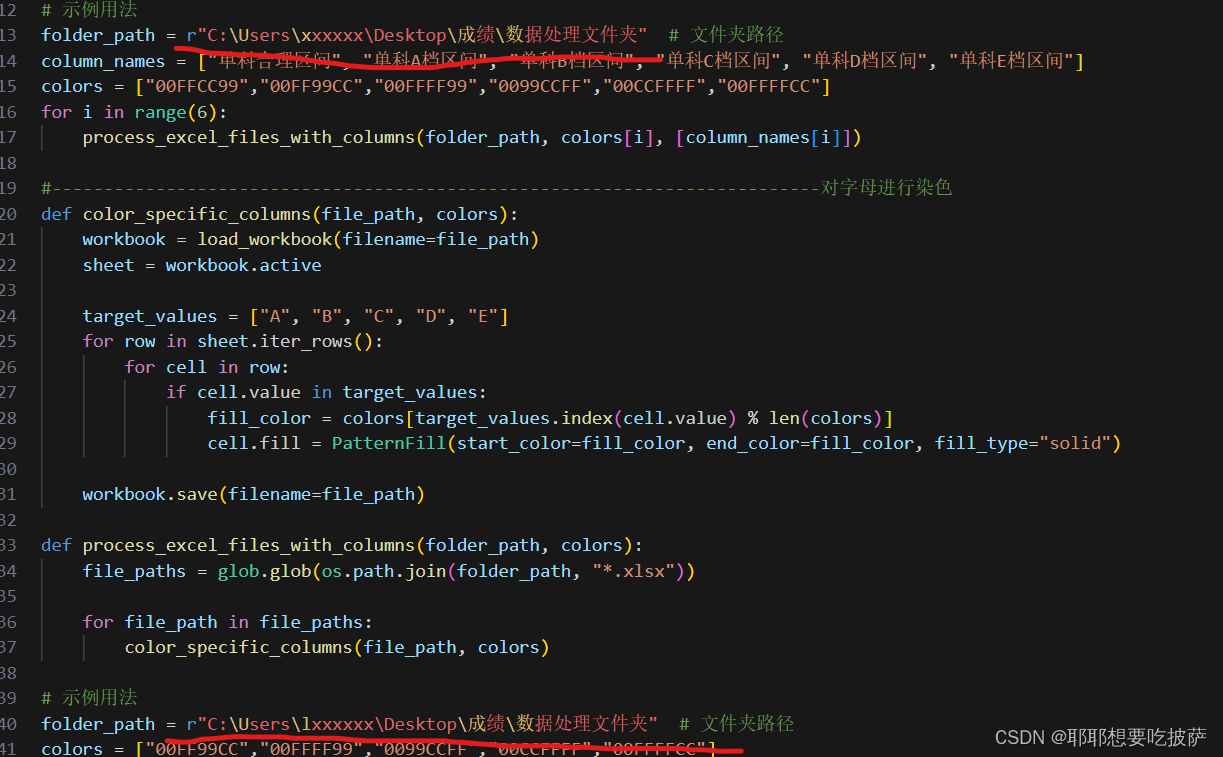
这两个地方在\数据处理文件夹之前改为成绩文件夹所在位置
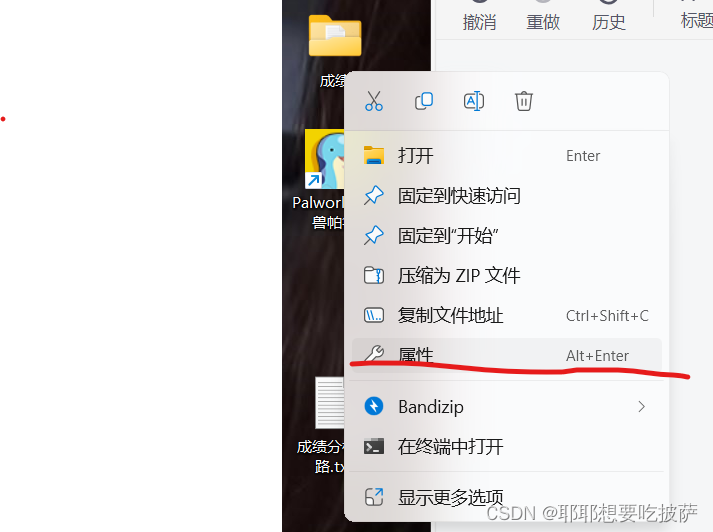
格式为:复制的东西\数据处理文件夹
8.选择内核

找到python 3.12.0
然后点击全部运行就好了

然后可能还会出现这种报错

这里显示No module named 'xxxxxxx' 这里代表的是却xxxx
你就在刚才win+r然后输入cmd打开的地方输入
pip install xxxxxx -i https://pypi.tuna.tsinghua.edu.cn/simple some-package 就好了将xxxx替换
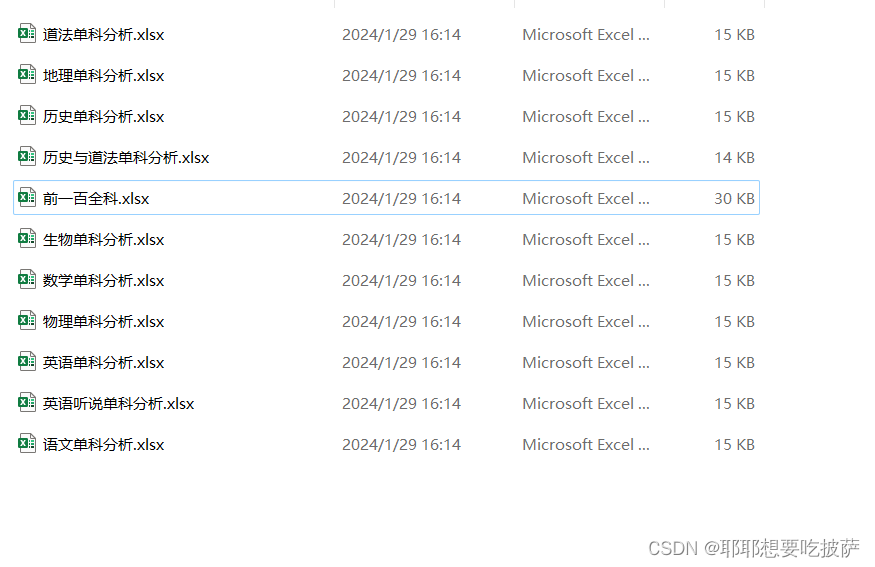
最后生成出来的文件分析在这里

出来成果长这样
然后还有提取单科的
这篇关于前一百成绩分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





