本文主要是介绍初学——爬取新笔趣阁案例最新,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这是作为新人小白的我第一次写博客,想想还是挺激动的。
首先写代码前,希望大家明白一件事。
代码的规范性。——————真的非常非常非常非常非常重要!
在这之前,我还没体会到代码规范的重要性,直到昨天,我收集项目实例的时候。——头都要大了
同样的需求,代码却千奇百怪,形形色色。我翻烂了github csdn都没找到能看懂的东东。
直到遇见它.......

作为一个爬虫萌新,分享要爬的当然是——————新笔趣阁啦
需求: 输入小说的ID实现爬取整本小说 就是这串数字
就是这串数字
ps:后面我用异步整出来 再分享异步操作
项目效果:
说再多不给人看都是耍流氓 来上效果
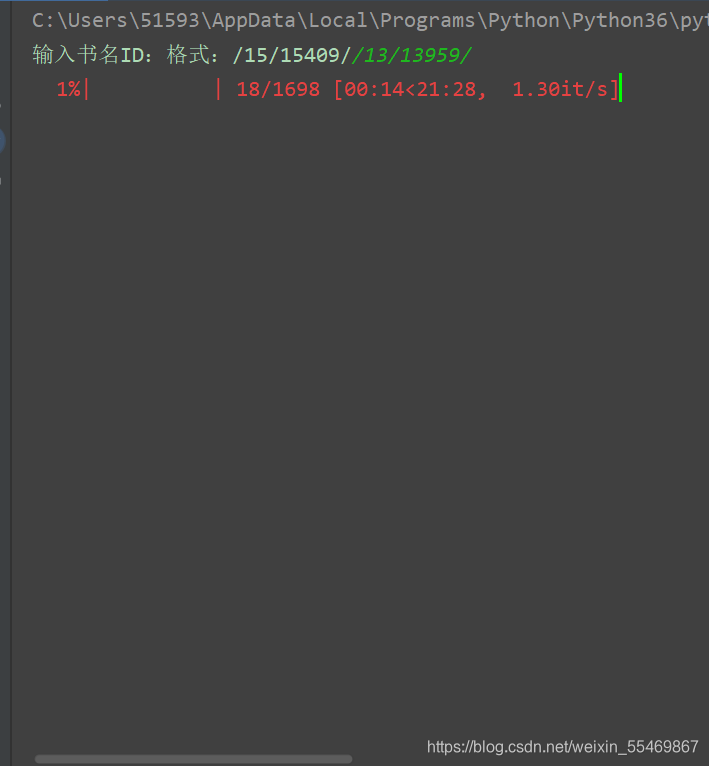
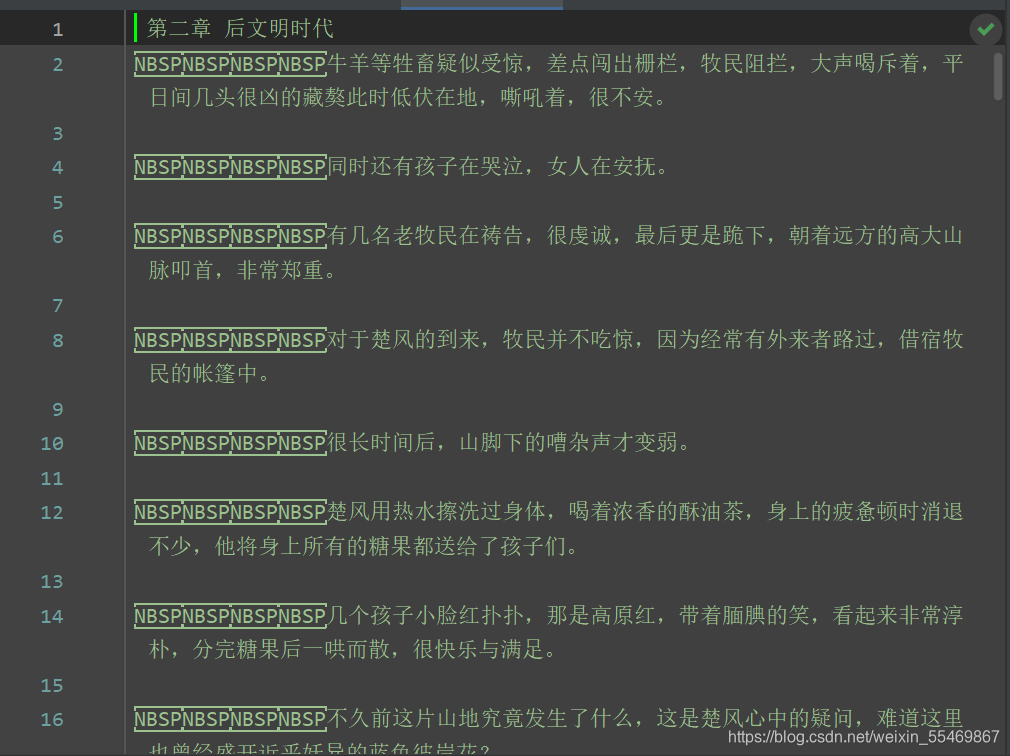
爬取的思路:
项目要用到的模块
import requests
import requests
from lxml import etree
from tqdm import tqdm # 进度条模块一、明确需求
先打开网址https://www.xbiquge.la/ 随便打开一本小说的链接 任意打开一章节 我们来获取它的数据
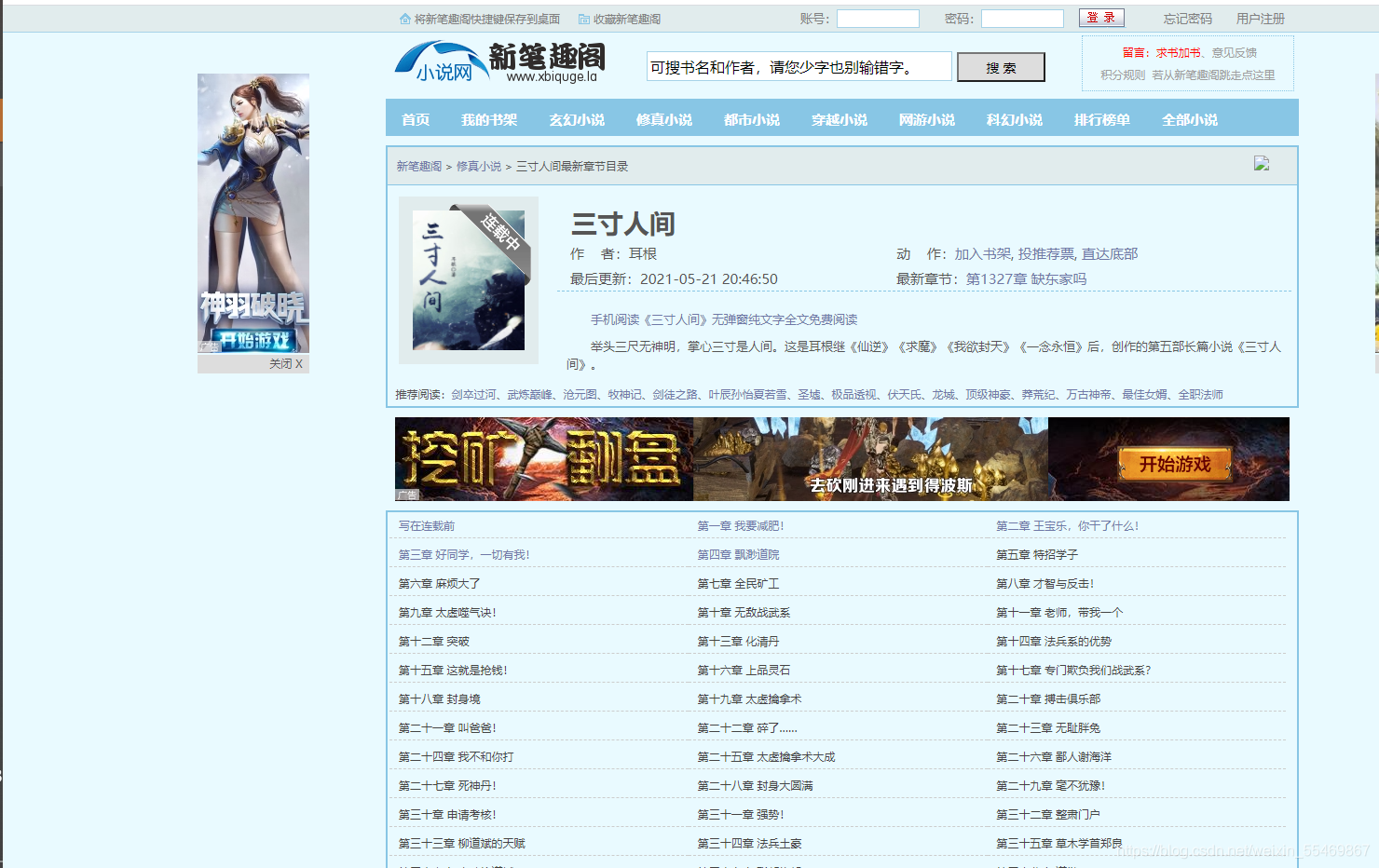
# 构造请求头处理反爬
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'}
# 请求网页内容 赋值给response
response = requests.get('https://www.xbiquge.la/10/10489/4535761.html',headers=headers)
# 答应网页的文本内容
print(response.text)咦,请求网页返回的数据出现了乱码,这就需要我们解码了
加一行代码自动解码
response.encoding = response.apparent_encoding

二、解析数据
我们需要的数据有了,接下来是不是要解析数据啦
解析数据 我这里采用的是xpath解析,当然你也可以采用re bs4 css解析
用标签选择器定位到我们需要的文章标题的内容
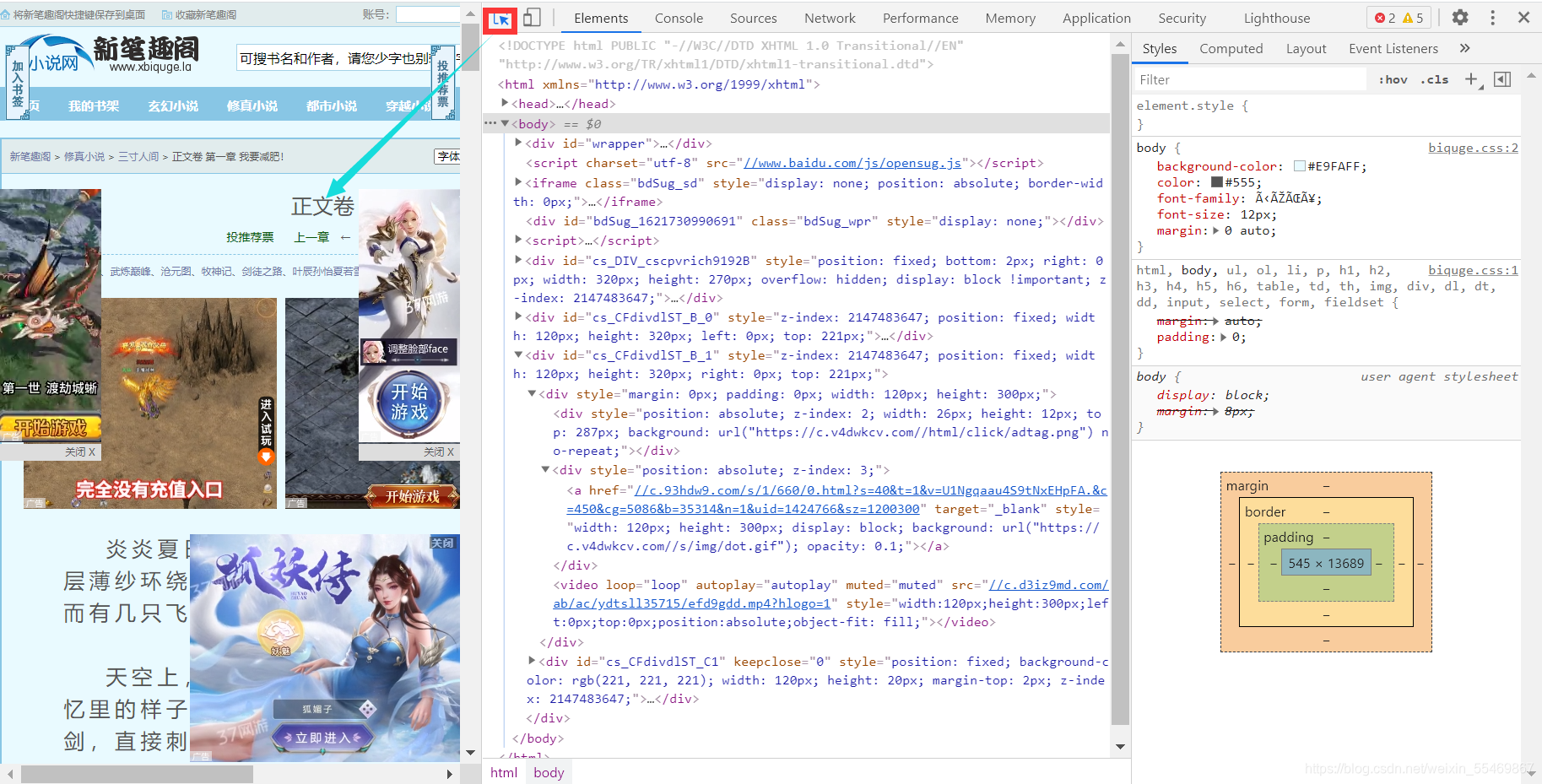
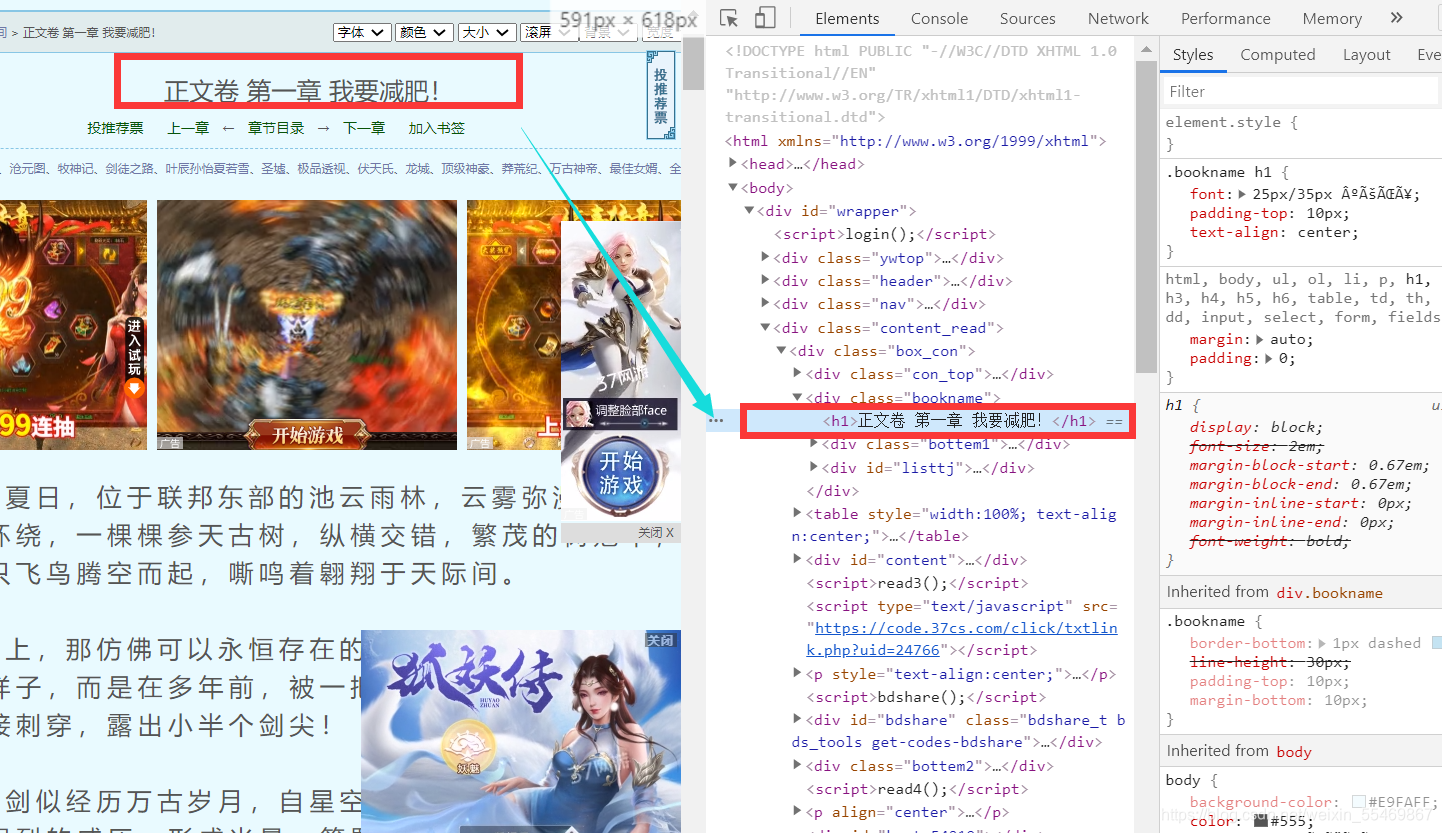
这里对应的便是标题的内容了
右键 copy ----copy xpath
同理 我们再获取小说的的内容
需要注意 我们这里提取到的是小说的列表
# 构建解析对象
tree = etree.HTML(response.text)
# 小说标题
title = tree.xpath('//div[@class="bookname"]/h1/text()')[0]
# 小说内容 返回的是列表
content_list = tree.xpath('//*[@id="content"]//text()')
# 将小说列表转化为字符串的形式
content_str = ''.join(content_list)
print(title,content_str)这里你打印字符串 可能会缺少东西 没错的蛤 写入文件就正常了

三 持久化存储
file_name = f"{novel_name}.txt"
# 一定要记得加后缀.txt mode 保存方式 a是追加保存 encoding是保存编码
with open(file_name,mode='a',encoding='utf-8') as f:
# 写入标题f.write(title)
# 写入换行f.write('\n')
# 写入小说内容f.write(content)
保存一章小说这样就写完了,那如何获取完整的小说呢
这里的参数此时不用注意 是函数的参数 后面看完整代码即可 讲的是思路
整本小说爬虫
既然知道怎么爬取单章节内容了,那你是不是知道所有章节的url 使用函数传参到爬取单章节内容的代码 是不是就可以爬取全部内容了
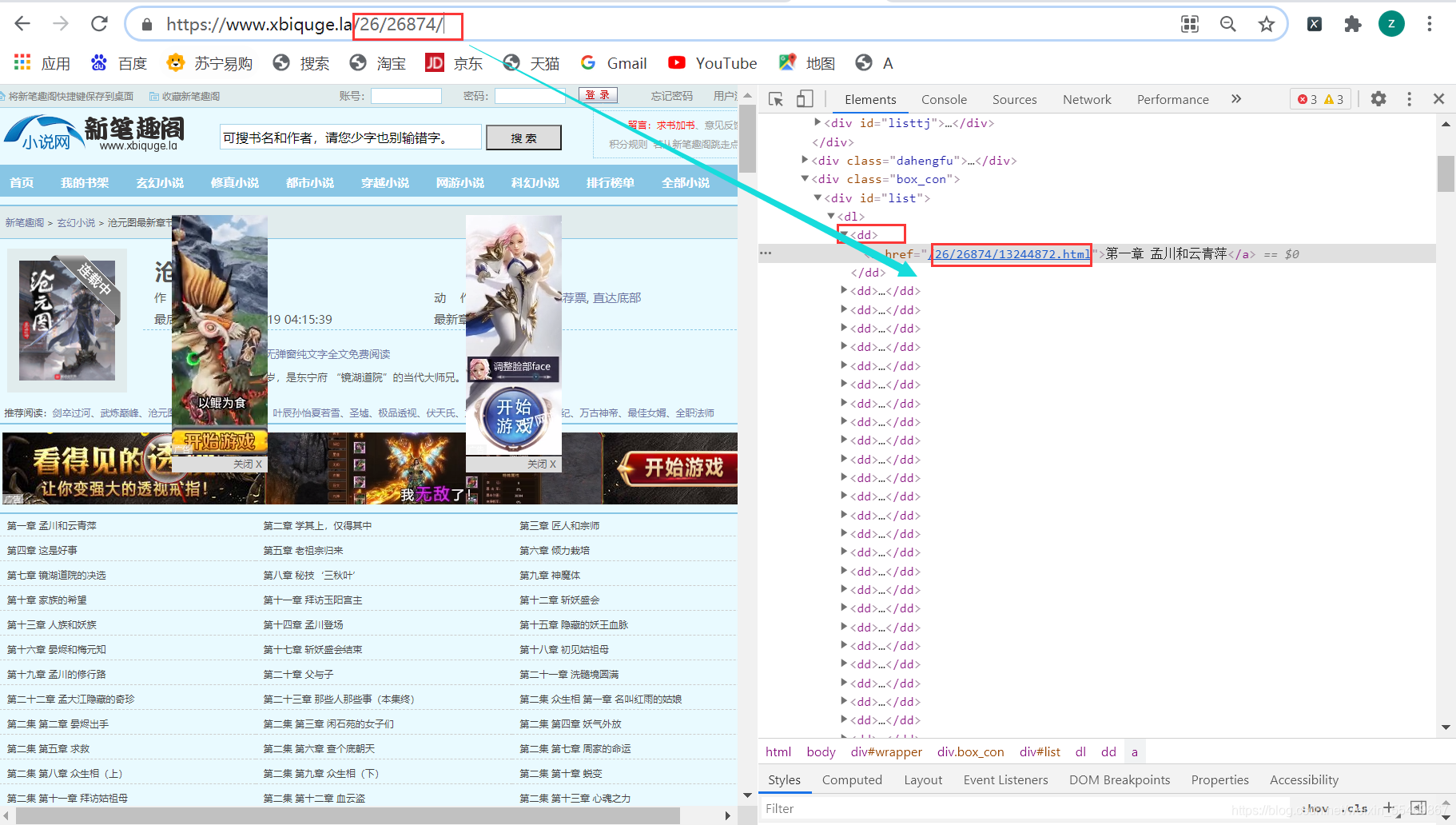
我们用xpath解析首页的html内容提取 所有小说的url和小说的名字
所有的单章的url地址都在 dd 标签当中,但是这个url地址是不完整的,所以爬取下来的时候,要拼接url地址。
前面的前缀名+href的内容
def get_all_url(html_url):# 调用请求网页函数 获取到的是某个小说的首页response = get_response(html_url)# 解析我们需要的小说章节标题 章节url内容# 构成解析对象tree = etree.HTML(response.text)# 首页的所有章节urlall_url = tree.xpath('//*[@id="list"]/dl/dd/a/@href')# 小说的名字novel_name = tree.xpath('//*[@id="info"]/h1/text()')for url in tqdm(all_url):novel_url = 'https://www.xbiquge.la/'+url# 给get第一页函数传入参数 小说名字和链接get_one_novel(novel_name,novel_url)tqdm的用法小伙伴们可以自行搜索学习 是一个进度条的效果
爬起整本小说代码
注释写的很详细 这是我结合很多大佬/很多案例总结出的,目前我认为的最优方法。
需要有python基础噢 有不懂得可以在下面交流讨论
咱们下期见 ~~~~~
import requestsfrom lxml import etree
from tqdm import tqdmdef get_response(html_url):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'}response = requests.get(url=html_url,headers=headers)response.encoding = response.apparent_encodingreturn responsedef save(novel_name,title,content):""":param novel_name::param title::param content::return:"""file_name = f"{novel_name}.txt"# 一定要记得加后缀.txt mode 保存方式 a是追加保存 encoding是保存编码with open(file_name,mode='a',encoding='utf-8') as f:# 写入标题f.write(title)# 写入换行f.write('\n')# 写入小说内容f.write(content)def get_one_novel(name,novel_url):# 小说章节内容获取 #调用请求网页数据函数response = get_response(novel_url)# 构建解析对象tree = etree.HTML(response.text)# 小说标题title = tree.xpath('//div[@class="bookname"]/h1/text()')[0]# 小说内容 返回的是列表content_list = tree.xpath('//*[@id="content"]//text()')content_str = ''.join(content_list)save(name,title,content_str)def get_all_url(html_url):# 调用请求网页函数 获取到的是某个小说的首页response = get_response(html_url)# 解析我们需要的小说章节标题 章节url内容# 构成解析对象tree = etree.HTML(response.text)# 首页的所有章节urlall_url = tree.xpath('//*[@id="list"]/dl/dd/a/@href')# 小说的名字novel_name = tree.xpath('//*[@id="info"]/h1/text()')for url in tqdm(all_url):novel_url = 'https://www.xbiquge.la/'+url# 给get第一页函数传入参数 小说名字和链接get_one_novel(novel_name,novel_url)if __name__ == '__main__':novel_id = input('输入书名ID:格式:/15/15409/')url = f'https://www.xbiquge.la{novel_id}'get_all_url(url)
这篇关于初学——爬取新笔趣阁案例最新的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






