本文主要是介绍记一次java项目本地正常执行,打完包之后执行发现没有对应的类或配置的问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、起因
线上有个spark的任务出了问题(该任务是通过sparkstreaming读取kafka中的数据,处理完之后推到es中),问题出在kafka中数据是有更新的,但是es中的对应索引中的数据却只更新到月初,因此我需要排查处理下这个问题。
由于这个任务在yarn上运行的,且日志级别是warn的,导致没有过多的有用信息,只有执行程序的入参args,这个时候排查问题就需要将程序放在本地的开发工具,例如:IDEA中进行debug调试。但是这个时候就会遇到另外一个问题,本地电脑连接不上远程的kafka服务,导致消费不到数据,消费不到数据就无法往下进行。但是这个问题不算是问题,我们只需要将本地项目打成jar包,上传到对应kafka的机器上,再开启debug端口执行即可进行项目代码的debug调试。但是在打jar包的过程中遇到了本篇名中主要问题。
# 开启远程debug执行jar包的命令
nohup java -cp analytics.dataFactory.etl.kafka-1.0.0-RELEASE-jar-with-dependencies.jar -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5006 com.aispeech.analytics.dataFactory.etl.kafka.DriverApplicationComplex &
2、处理过程
2.1、打包方式
注:因为将jar包上传到kafka机器上执行前,我想先在本地执行下jar包,看是否有问题,不然上传一个大jar包到远程机器比较耗时。因此我先在本地跑下jar包看看结果。
- 引入maven插件:
在父项目的pom中引入下面插件:
<build><plugins><plugin><artifactId>maven-source-plugin</artifactId><version>2.1</version><configuration><attach>true</attach></configuration><executions><execution><phase>compile</phase><goals><goal>jar</goal></goals></execution></executions></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.5.1</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-release-plugin</artifactId></plugin></plugins></build>
在具体module的pom中引入:
<build><plugins><plugin><artifactId>maven-assembly-plugin</artifactId><version>2.5.3</version><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration></plugin></plugins></build>
- 执行maven命令打包:
mvn -Dmaven.test.skip=true clean package install assembly:single -U
2.2、执行jar包报错
执行jar包命令:
java -cp analytics.dataFactory.etl.kafka-1.0.0-RELEASE-jar-with-dependencies.jar com.aispeech.analytics.dataFactory.etl.kafka.DriverApplicationComplex
报错:
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
24/02/01 11:42:11 INFO SparkContext: Running Spark version 3.1.2
24/02/01 11:42:12 INFO ResourceUtils: ==============================================================
24/02/01 11:42:12 INFO ResourceUtils: No custom resources configured for spark.driver.
24/02/01 11:42:12 INFO ResourceUtils: ==============================================================
24/02/01 11:42:12 INFO SparkContext: Submitted application: dataFactory-local
24/02/01 11:42:12 INFO ResourceProfile: Default ResourceProfile created, executor resources: Map(cores -> name: cores, amount: 1, script: , vendor: , memory -> name: memory, amount: 1024, script: , vendor: , offHeap -> name: offHeap, amount: 0, script: , vendor: ), task resources: Map(cpus -> name: cpus, amount: 1.0)
24/02/01 11:42:12 INFO ResourceProfile: Limiting resource is cpu
24/02/01 11:42:12 INFO ResourceProfileManager: Added ResourceProfile id: 0
24/02/01 11:42:12 INFO SecurityManager: Changing view acls to: duys
24/02/01 11:42:12 INFO SecurityManager: Changing modify acls to: duys
24/02/01 11:42:12 INFO SecurityManager: Changing view acls groups to:
24/02/01 11:42:12 INFO SecurityManager: Changing modify acls groups to:
24/02/01 11:42:12 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(duys); groups with view permissions: Set(); users with modify permissions: Set(duys); groups with modify permissions: Set()
24/02/01 11:42:12 INFO Utils: Successfully started service 'sparkDriver' on port 51898.
24/02/01 11:42:13 INFO SparkEnv: Registering MapOutputTracker
24/02/01 11:42:13 INFO SparkEnv: Registering BlockManagerMaster
24/02/01 11:42:13 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
24/02/01 11:42:13 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
24/02/01 11:42:13 INFO SparkEnv: Registering BlockManagerMasterHeartbeat
24/02/01 11:42:13 INFO DiskBlockManager: Created local directory at C:\Users\duys\AppData\Local\Temp\blockmgr-1142ca72-1b3d-4869-b7b9-8d229203eac0
24/02/01 11:42:13 INFO MemoryStore: MemoryStore started with capacity 1968.3 MiB
24/02/01 11:42:13 INFO SparkEnv: Registering OutputCommitCoordinator
24/02/01 11:42:13 INFO Utils: Successfully started service 'SparkUI' on port 4040.
24/02/01 11:42:13 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://172.16.68.163:4040
24/02/01 11:42:13 INFO Executor: Starting executor ID driver on host 172.16.68.163
24/02/01 11:42:13 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 51953.
24/02/01 11:42:13 INFO NettyBlockTransferService: Server created on 172.16.68.163:51953
24/02/01 11:42:13 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
24/02/01 11:42:13 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, 172.16.68.163, 51953, None)
24/02/01 11:42:13 INFO BlockManagerMasterEndpoint: Registering block manager 172.16.68.163:51953 with 1968.3 MiB RAM, BlockManagerId(driver, 172.16.68.163, 51953, None)
24/02/01 11:42:13 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, 172.16.68.163, 51953, None)
24/02/01 11:42:13 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, 172.16.68.163, 51953, None)
24/02/01 11:42:13 WARN DriverApplicationComplex: key:0,readerContext1:context{kafka.bootstrap.servers:10.24.1.21:6667,10.24.1.32:6667,10.24.1.43:6667,10.24.1.110:6667,10.24.1.111:6667,topics:log-dca-logger-action-prod,fieldTypes:msTime:long,index_suffix:string,value:string,kafka.maxOffsetsPerTrigger:10000,decoderClass:com.aispeech.analytics.etl.customDecoder.cdc.DecoderDriver,type:com.aispeech.analytics.dataFactory.etl.kafka.KafkaReader,},writerContext1:context{indexType:doc,nodes:10.24.1.33,10.24.1.34,10.24.1.44,10.24.1.45,10.24.110.91,10.24.110.92,10.24.110.93,10.24.110.94,checkpointLocation:file:///tmp/,port:9200,index:log-dca-logger-action-prod-{index_suffix|yyyy.MM},isJsonWriter:true,triggerPeriod:60,authUser:bigdata,type:com.aispeech.analytics.dataFactory.etl.elasticsearch.ElasticsearchWriter,authPassword:data@Speech2019,},metricsContext1:context{}
Exception in thread "main" org.apache.spark.sql.AnalysisException: Failed to find data source: kafka. Please deploy the application as per the deployment section of "Structured Streaming + Kafka Integration Guide".at org.apache.spark.sql.execution.datasources.DataSource$.lookupDataSource(DataSource.scala:684)at org.apache.spark.sql.streaming.DataStreamReader.loadInternal(DataStreamReader.scala:208)at org.apache.spark.sql.streaming.DataStreamReader.load(DataStreamReader.scala:194)at com.aispeech.analytics.dataFactory.etl.kafka.KafkaReader.complexReadStream(KafkaReader.java:145)at com.aispeech.analytics.dataFactory.etl.kafka.DriverApplicationComplex.main(DriverApplicationComplex.java:144)刚开始我还以为是错误对应的spark-sql-kafka-0-10_2.12-3.1.2.jar包没有打进去,但是我通过压缩软件打开jar包内部,却发现是有的!!!
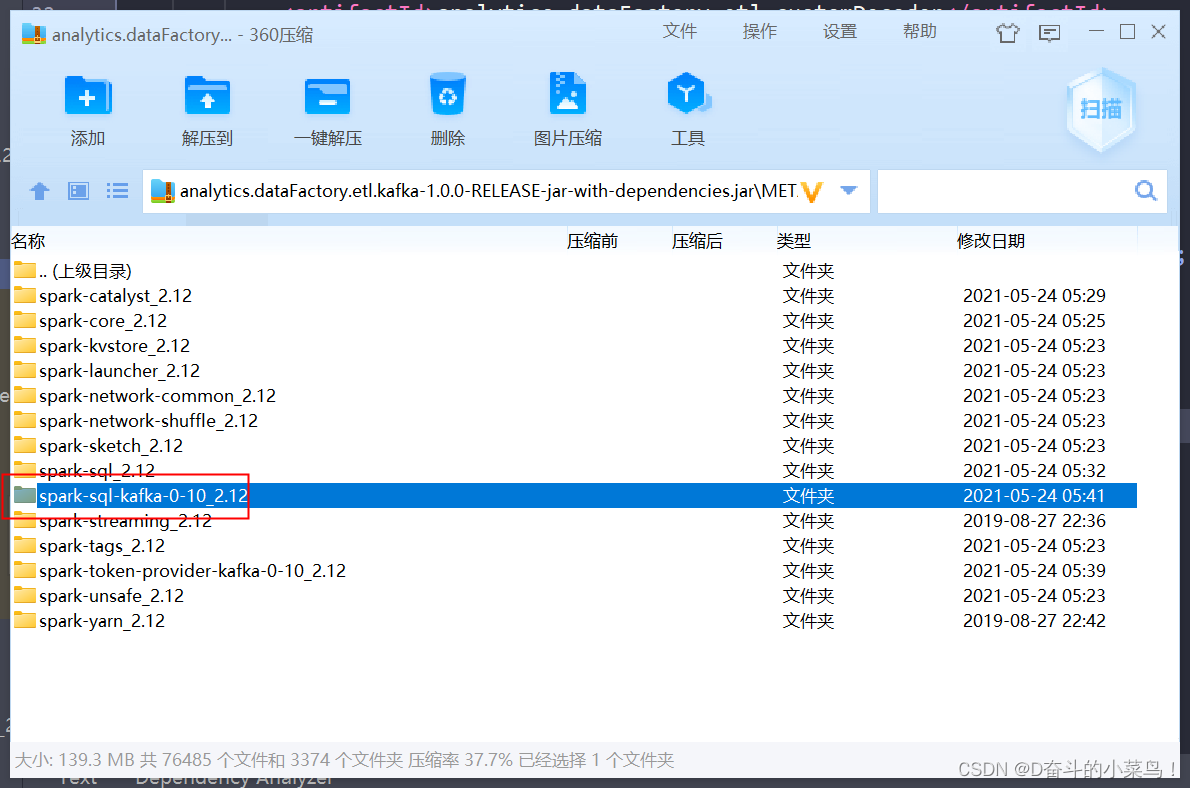
然后我就傻眼了,到底是怎么一回事,在网上查了半天就说我是少对应的依赖包spark-sql-kafka-0-10_2.12-3.1.2.jar,我也是服了。
2.3、解决
等到下午的时候,我突然想到会不会是主jar包下的service目录下对应的文件内容和spark-sql-kafka-0-10_2.12-3.1.2.jar下service目录下对应文件内容不一致,被覆盖掉了?然后我先查看了spark-sql-kafka-0-10_2.12-3.1.2.jar包下的文件内容:
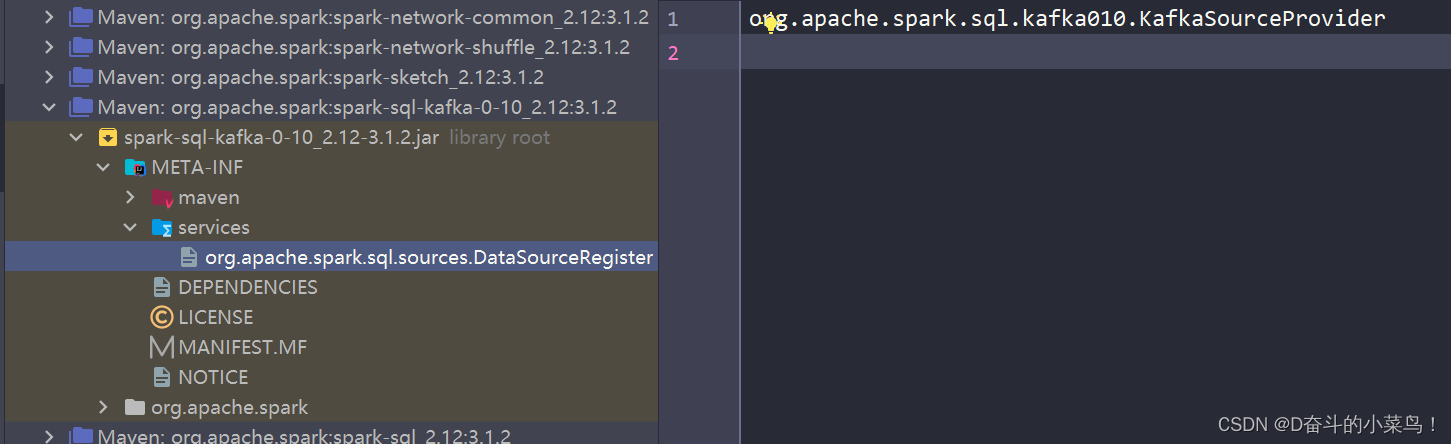
发现文件里面的没内容好像就是错误信息需要的东西,然后我再看我自己打的jar包里面这个文件的内容:
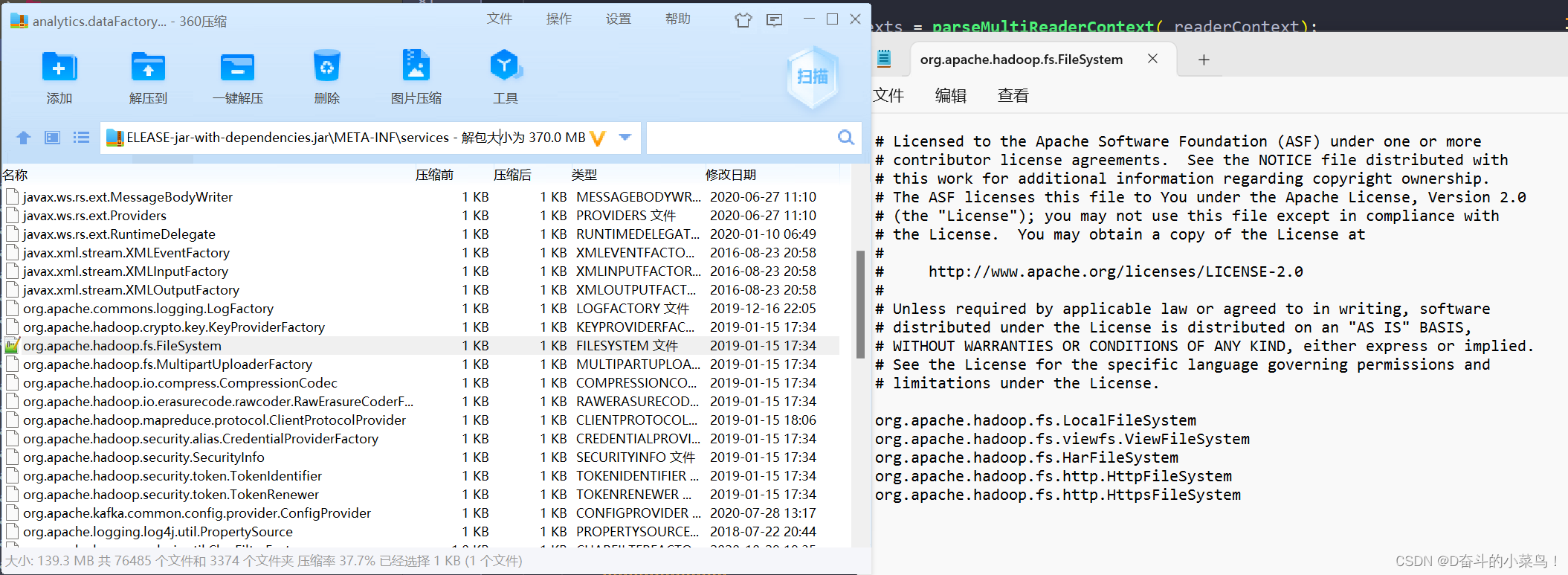
竟然真的没有源jar包文件的这块内容:org.apache.spark.sql.kafka010.KafkaSourceProvider 这就更加让我确信就是这个文件内容的问题!(可能打包的时候被其他的内容覆盖掉了,所以大家使用jar包执行任务的时候,还是打成瘦包吧,将所有的依赖单独放在一个lib目录中依赖,这样会减少一些不容易发现的bug)。然后我就讲这块内容追加到我打的jar包这个文件的里面:
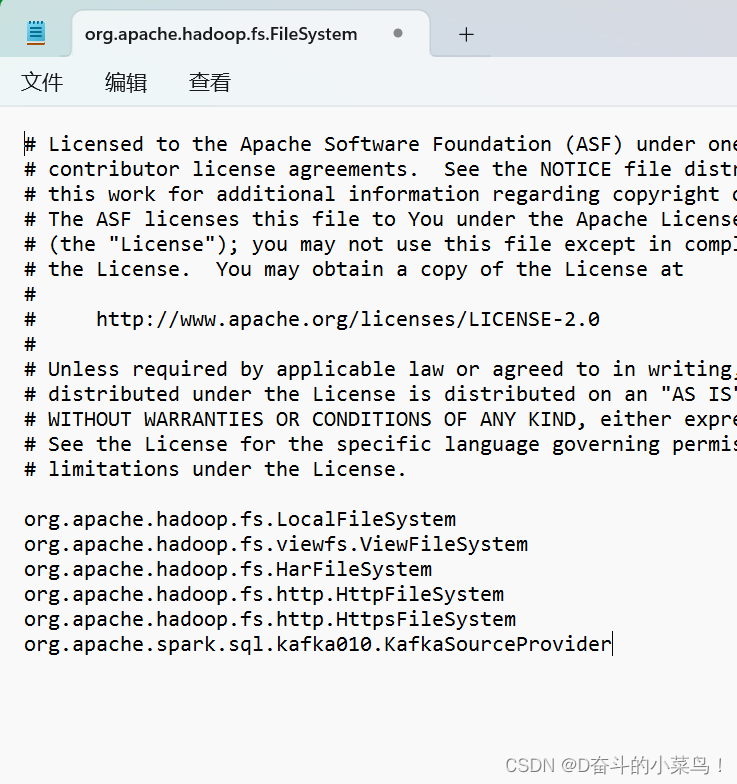
然后保存,再执行我的jar包,果然啊果然就是这里的问题:
$ java -cp analytics.dataFactory.etl.kafka-1.0.0-RELEASE-jar-with-dependencies.jar com.aispeech.analytics.dataFactory.etl.kafka.DriverApplicationComplex
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
24/02/01 12:00:40 INFO SparkContext: Running Spark version 3.1.2
24/02/01 12:00:40 INFO ResourceUtils: ==============================================================
24/02/01 12:00:40 INFO ResourceUtils: No custom resources configured for spark.driver.
24/02/01 12:00:40 INFO ResourceUtils: ==============================================================
24/02/01 12:00:40 INFO SparkContext: Submitted application: dataFactory-local
24/02/01 12:00:40 INFO ResourceProfile: Default ResourceProfile created, executor resources: Map(cores -> name: cores, amount: 1, script: , vendor: , memory -> name: memory, amount: 1024, script: , vendor: , offHeap -> name: offHeap, amount: 0, script: , vendor: ), task resources: Map(cpus -> name: cpus, amount: 1.0)
24/02/01 12:00:40 INFO ResourceProfile: Limiting resource is cpu
24/02/01 12:00:40 INFO ResourceProfileManager: Added ResourceProfile id: 0
24/02/01 12:00:40 INFO SecurityManager: Changing view acls to: duys
24/02/01 12:00:40 INFO SecurityManager: Changing modify acls to: duys
24/02/01 12:00:40 INFO SecurityManager: Changing view acls groups to:
24/02/01 12:00:40 INFO SecurityManager: Changing modify acls groups to:
24/02/01 12:00:40 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(duys); groups with view permissions: Set(); users with modify permissions: Set(duys); groups with modify permissions: Set()
24/02/01 12:00:41 INFO Utils: Successfully started service 'sparkDriver' on port 62220.
24/02/01 12:00:41 INFO SparkEnv: Registering MapOutputTracker
24/02/01 12:00:41 INFO SparkEnv: Registering BlockManagerMaster
24/02/01 12:00:41 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
24/02/01 12:00:41 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
24/02/01 12:00:41 INFO SparkEnv: Registering BlockManagerMasterHeartbeat
24/02/01 12:00:41 INFO DiskBlockManager: Created local directory at C:\Users\duys\AppData\Local\Temp\blockmgr-8e9e9755-2411-40cd-ae8d-3974791fc1b5
24/02/01 12:00:41 INFO MemoryStore: MemoryStore started with capacity 1968.3 MiB
24/02/01 12:00:41 INFO SparkEnv: Registering OutputCommitCoordinator
24/02/01 12:00:41 INFO Utils: Successfully started service 'SparkUI' on port 4040.
24/02/01 12:00:41 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://172.16.68.163:4040
24/02/01 12:00:41 INFO Executor: Starting executor ID driver on host 172.16.68.163
24/02/01 12:00:41 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 62275.
24/02/01 12:00:41 INFO NettyBlockTransferService: Server created on 172.16.68.163:62275
24/02/01 12:00:41 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
24/02/01 12:00:41 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, 172.16.68.163, 62275, None)
24/02/01 12:00:41 INFO BlockManagerMasterEndpoint: Registering block manager 172.16.68.163:62275 with 1968.3 MiB RAM, BlockManagerId(driver, 172.16.68.163, 62275, None)
24/02/01 12:00:41 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, 172.16.68.163, 62275, None)
24/02/01 12:00:41 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, 172.16.68.163, 62275, None)
24/02/01 12:00:41 WARN DriverApplicationComplex: key:0,readerContext1:context{kafka.bootstrap.servers:10.24.1.21:6667,10.24.1.32:6667,10.24.1.43:6667,10.24.1.110:6667,10.24.1.111:6667,topics:log-dca-logger-action-prod,fieldTypes:msTime:long,index_suffix:string,value:string,kafka.maxOffsetsPerTrigger:10000,decoderClass:com.aispeech.analytics.etl.customDecoder.cdc.DecoderDriver,type:com.aispeech.analytics.dataFactory.etl.kafka.KafkaReader,},writerContext1:context{indexType:doc,nodes:10.24.1.33,10.24.1.34,10.24.1.44,10.24.1.45,10.24.110.91,10.24.110.92,10.24.110.93,10.24.110.94,checkpointLocation:file:///tmp/,port:9200,index:log-dca-logger-action-prod-{index_suffix|yyyy.MM},isJsonWriter:true,triggerPeriod:60,authUser:bigdata,type:com.aispeech.analytics.dataFactory.etl.elasticsearch.ElasticsearchWriter,authPassword:data@Speech2019,},metricsContext1:context{}
24/02/01 12:00:41 WARN FileSystem: Cannot load filesystem: java.util.ServiceConfigurationError: org.apache.hadoop.fs.FileSystem: Provider org.apache.spark.sql.kafka010.KafkaSourceProvider not a subtype
24/02/01 12:00:42 WARN SparkSession: DataFrame schema: StructType(StructField(msTime,LongType,true), StructField(index_suffix,StringType,true), StructField(value,StringType,true))
24/02/01 12:00:42 WARN ElasticsearchForeachWriter: -----------------nodes:10.24.1.33,10.24.1.34,10.24.1.44,10.24.1.45,10.24.110.91,10.24.110.92,10.24.110.93,10.24.110.94,port:9200,authUser:bigdata,authPassword:data@Speech2019,index:log-dca-logger-action-prod-{index_suffix|yyyy.MM},type:doc,httpHosts:8,eCore:1完美解决!
这篇关于记一次java项目本地正常执行,打完包之后执行发现没有对应的类或配置的问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



