本文主要是介绍自动保存知乎上点赞的内容至本地,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
背景:知乎上常有非常精彩的回答/文章,必须要点赞+收藏,日后回想起该回答/文章时翻看自己的动态和收藏夹却怎么也找不到,即使之前保存了链接网络不好也打不开了(。所以我一般碰到好的回答/文章都会想办法保存它的离线版本,但人是懒的,有没有什么办法可以自动保存我点赞/公开收藏过的内容呢。经过苦苦搜寻,终于我找到了这么一个开源的工具:
https://github.com/amchii/ZhiArchive,监测知乎用户的个人动态并保存内容以防丢失
Docker快速部署好之后,每当我点赞某个内容的时候,它都会帮我拍一个动态和该内容的长截图,妈妈再也不用担心我丢三落四了。
以下是它的介绍:
ZhiArchive
监测知乎用户的个人动态并保存内容以防丢失。
某用户的动态结果保存目录如下:
activities为个人动态页快照,archives为动态对应的回答/文章快照
.
├── activities
│ ├── 2024
│ │ └── 01
│ │ └── 17
│ │ ├── 回答-为什么只有饿死的狮子而没有饿死的老虎?说明了什么问题?.png
│ │ ...
│ │ └── 赞同-如何看待211高校华中某业大学动物Y养系黄某若教授十几年如一日的学术造假行为?.png
│ └── 20240117181850.json
└── archives └── 2024 └── 01 └── 17 ├── 回答-为什么只有饿死的狮子而没有饿死的老虎?说明了什么问题? │ ├── info.json │ └── 回答-为什么只有饿死的狮子而没有饿死的老虎?说明了什么问题?.png ... └── 赞同-如何看待211高校华中某业大学动物Y养系黄某若教授十几年如一日的学术造假行为? ├── info.json └── 赞同-如何看待211高校华中某业大学动物Y养系黄某若教授十几年如一日的学术造假行为?.png 16 directories, 25 files
其中:
动态文件activities/2024/01/17/赞同-如何看待211高校华中某业大学动物Y养系黄某若教授十几年如一日的学术造假行为?.png如图:
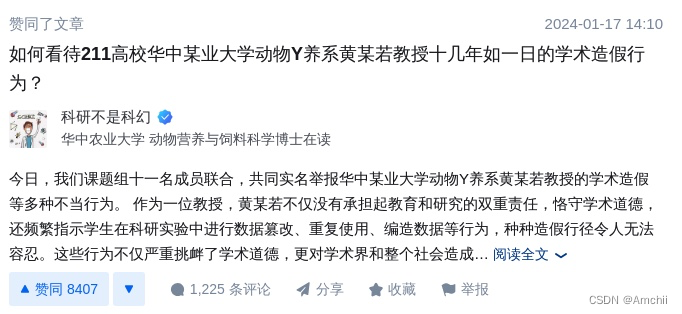
目标文件archives/2024/01/17/赞同-如何看待211高校华中某业大学动物Y养系黄某若教授十几年如一日的学术造假行为?/赞同-如何看待211高校华中某业大学动物Y养系黄某若教授十几年如一日的学术造假行为?.png如图:
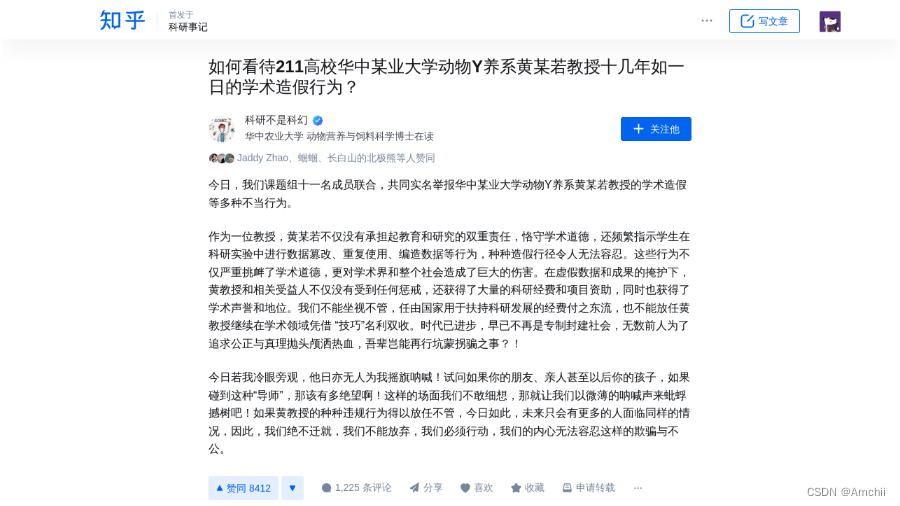
archives/2024/01/17/赞同-如何看待211高校华中某业大学动物Y养系黄某若教授十几年如一日的学术造假行为?/info.json内容为:
{ "title": "如何看待211高校华中某业大学动物Y养系黄某若教授十几年如一日的学术造假行为?", "url": "https://zhuanlan.zhihu.com/p/678136207", "author": "zhang-li-28-1", "shot_at": "2024-01-17T18:19:13.783"
}
它是如何工作的
ZhiArchive使用Playwright,它由4个部分组成,分别是monitor,archiver,login worker和api:
- monitor:用于监测用户个人主页的动态并将新的动态:打快照,把动态的目标(回答、文章)链接通过redis丢给archiver。
- archiver:打开目标链接并保存屏幕快照至本地。
- login worker:用于登录知乎获取monitor和archiver所必需的认证信息。
- api:提供接口来操作控制monitor,archiver,login worker。
使用
注意查看日志跟踪运行状态
archiver: archiver.log
monitor: monitor.log
login_worker: login_worker.log
Docker
下载本项目:
# 下载本项目
git clone https://github.com/amchii/ZhiArchive.git
# 进入项目目录
cd ZhiArhive
构建镜像:
docker build -t zhi-archive:latest -f BaseDockerfile .
配置环境变量:
所有可配置项见config.py,支持通过环境变量或.env,.apienv文件配置
.env文件
secret_key= # 请生成一个随机字符串
people=<someone> # 知乎用户,在个人主页地址中:https://www.zhihu.com/people/<someone>
monitor_fetch_until=10 # 天数,Monitor初次运行时默认抓取到10天前的动态
.apienv文件
# API认证账号,配置用户名和密码
username=
password=
启动
docker compose up -d
API端口为9090,以127.0.0.1为例,
打开http://127.0.0.1:9090/docs可查看接口文档,下面👇🏻所提到的接口可在这个接口文档进行调用,调用之前请先打开http://127.0.0.1:9090/auth/login登录获取本项目的接口认证信息(Cookies)
登录知乎获取Cookie
打开http://127.0.0.1:9090/zhi/login获取知乎登录二维码:

扫码完成登录后将重定向到"http://127.0.0.1:9090/zhi/login/state/f19c99849de8dccc8e9b" 并显示获取的cookies,路径最后的’f19c99849de8dccc8e9b’将是你的state文件地址,文件存储路径为<项目目录>/states/f19c99849de8dccc8e9b.state.json,可通过接口GET/PUT /zhi/core/state_path 查看和设置正在运行的Monitor和Archiver的state文件。
(后续考虑登录完成即设置state)
运行Monitor和Archiver
Monitor和Archiver默认是暂停状态,设置好知乎的Cookie后,可以通过接口:
/zhi/core/{name}/pause查看和更改运行状态,name可以是’monitor’或’archiver’
运行后查看日志输出和结果目录。
TODO
- 所有元素selector可配置
- 通过接口完全控制
Monitor,Archiver - 支持监测多个用户
- 异常告警
- 提供前端界面
欢迎交流,Star⭐️一下,项目随时更新
这篇关于自动保存知乎上点赞的内容至本地的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








