本文主要是介绍机器学习 低代码 ML:PyCaret 的使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

✅作者简介:人工智能专业本科在读,喜欢计算机与编程,写博客记录自己的学习历程。
🍎个人主页:小嗷犬的个人主页
🍊个人网站:小嗷犬的技术小站
🥭个人信条:为天地立心,为生民立命,为往圣继绝学,为万世开太平。
本文目录
- PyCaret 简介
- PyCaret 实践
- 安装 PyCaret
- 使用 PyCaret 进行分类任务
- 使用 PyCaret 进行回归任务
PyCaret 简介
PyCaret 是一个开源的低代码 Python 库,专注于简化机器学习(ML)工作流程并加速实验过程。它特别适用于数据科学家、分析师和开发人员,通过减少实现 ML 解决方案所需的繁琐编码工作来提高工作效率。PyCaret 可以在一个统一且用户友好的接口下提供多种机器学习任务的支持,包括但不限于分类、回归、聚类、异常检测、关联规则挖掘等。

以下是一些关于 PyCaret 的关键特点和功能:
-
低代码自动化:
- PyCaret 允许用户通过简洁的 API 调用快速执行数据预处理、特征工程、模型训练、模型评估和模型选择等步骤。
- 用户无需编写大量的底层代码即可完成复杂的机器学习任务,仅需少量命令就能在几秒钟内搭建和比较多个模型。
-
集成多种库:
- 库内部封装了诸如 scikit-learn、XGBoost、LightGBM、CatBoost 等流行机器学习框架,并提供了对这些库中模型的便捷访问和管理。
- 同时也集成了其他辅助工具,如用于文本处理的 spaCy,以及用于超参数优化的 Optuna、Hyperopt 等。
-
模块化设计:
- PyCaret 按照不同机器学习任务划分为不同的模块,例如
classification、regression、clustering、anomaly_detection等,每个模块都包含了对应任务特定的方法和函数。
- PyCaret 按照不同机器学习任务划分为不同的模块,例如
-
端到端解决方案:
- 提供从数据加载到模型部署的完整生命周期管理,支持项目保存和加载,便于复现实验结果和迁移学习。
- 包括可视化工具,可以方便地生成各种性能指标图表,帮助用户直观理解模型表现和数据分布。
-
资源效率:
- 由于其自动化特性,PyCaret 能够在较小的计算资源消耗下进行大量实验,从而节省时间和计算成本。
-
易用性:
- 对于新手友好,使得没有丰富编程经验的数据科学爱好者也能快速入门并开始探索机器学习领域。
使用 PyCaret 进行机器学习实验时,用户通常首先初始化一个环境,设置数据分割策略、目标变量以及其他实验参数,然后就可以直接运行对比试验、调整模型配置、进行特征重要性分析等操作。这一系列过程极大提升了数据分析和建模的工作效率。
PyCaret 实践
安装 PyCaret
pip install pycaret
使用 PyCaret 进行分类任务
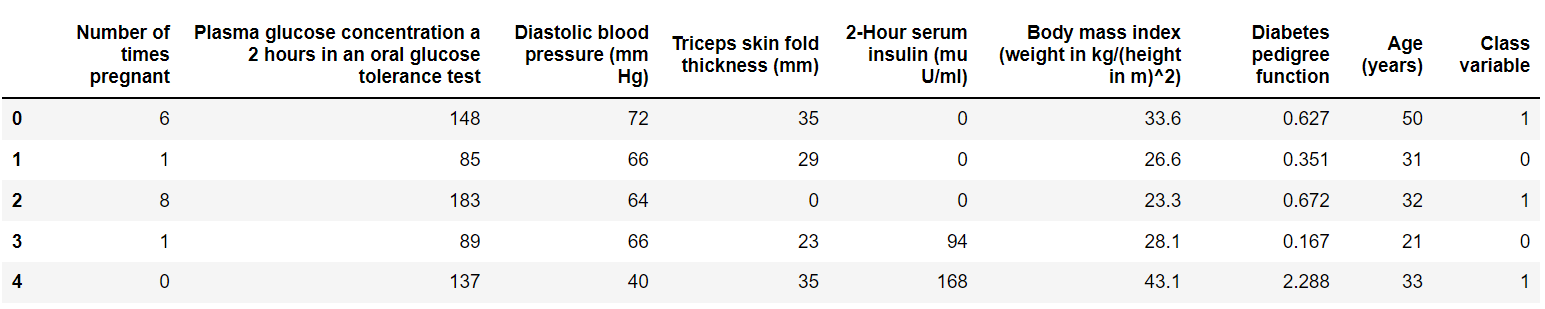
以 PyCaret 官方提供的 diabetes 数据集为例。
# 加载数据集
from pycaret.datasets import get_data
diabetes = get_data("diabetes")
# 初始化分类实验
from pycaret.classification import *
s = setup(data, target="Class variable", session_id=123)

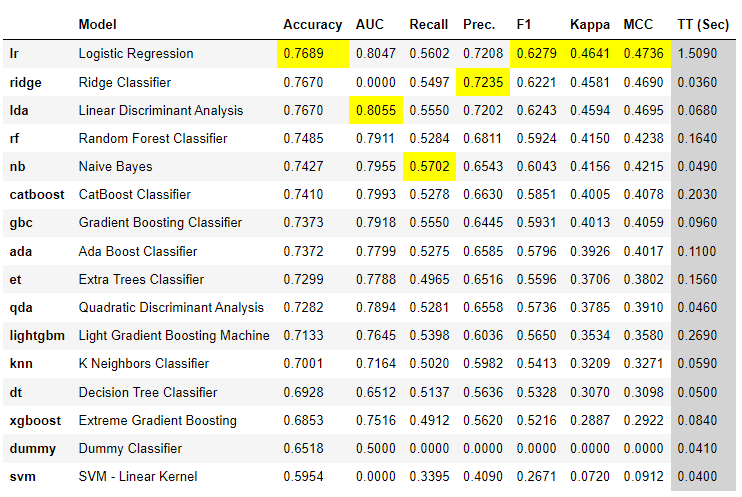
# 比较多个模型
best = compare_models()
# 打印最佳模型
print(best)

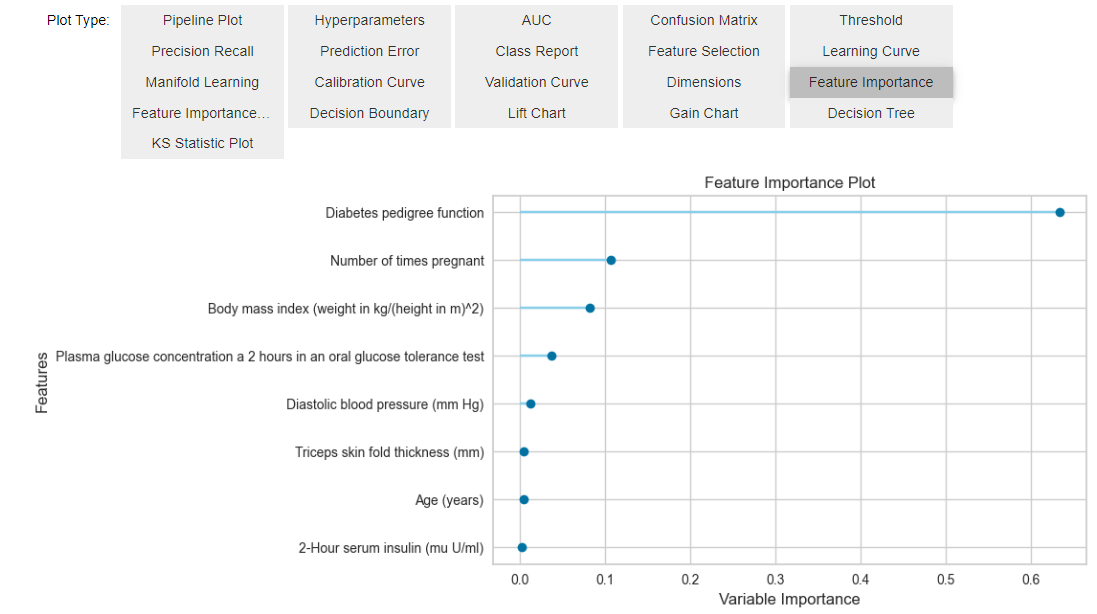
# 评估模型
evaluate_model(best)
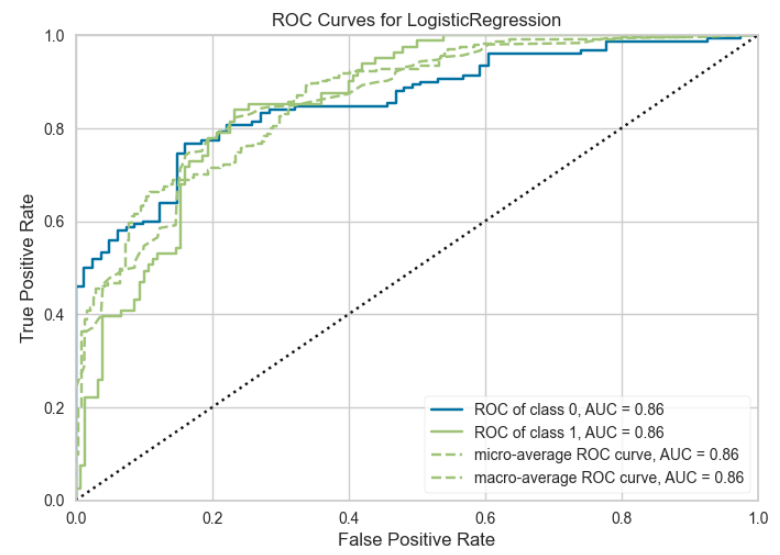
# 绘制 AUC 曲线
plot_model(best, plot="auc")
# 绘制混淆矩阵
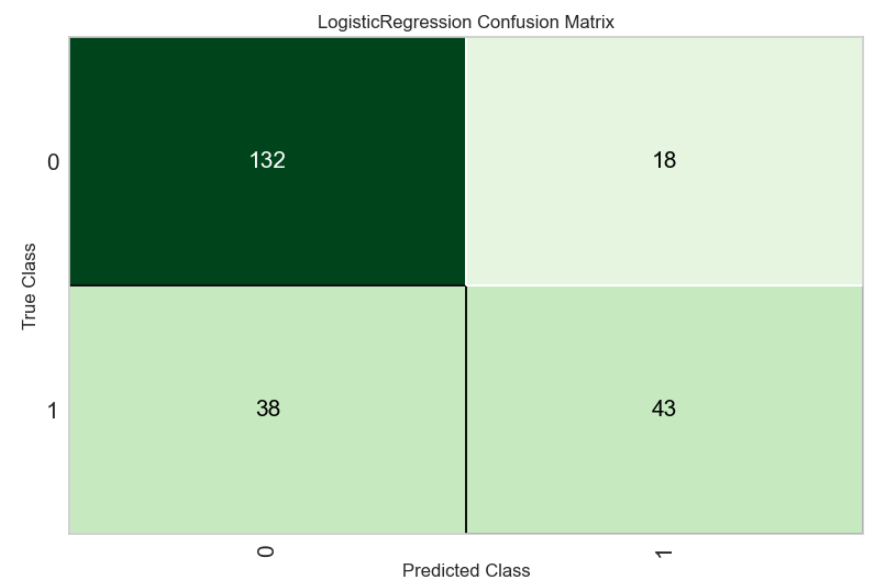
plot_model(best, plot="confusion_matrix")
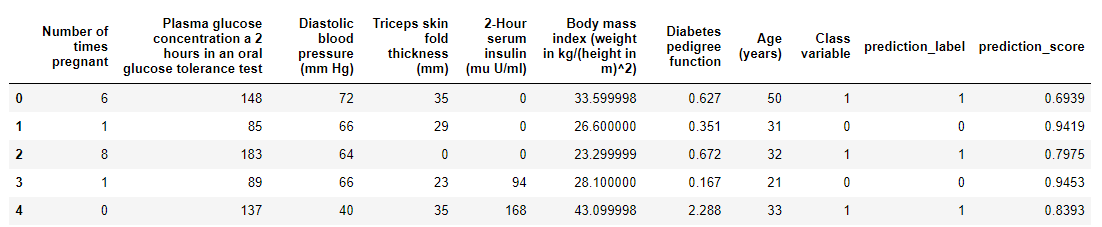
# 使用最优模型进行预测
predictions = predict_model(best, data=data)
predictions.head()
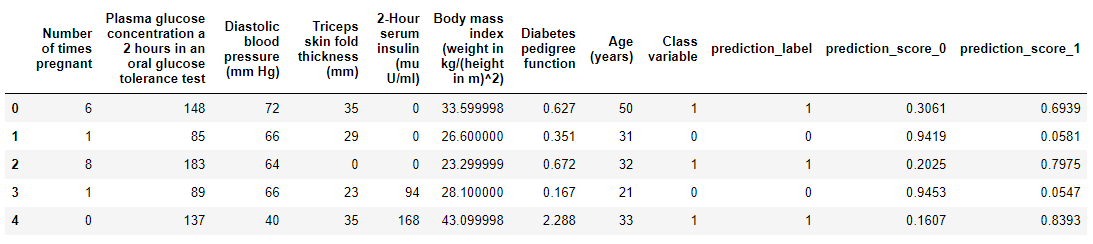
# 输出概率分数
predictions = predict_model(best, data=data, raw_score=True)
predictions.head()
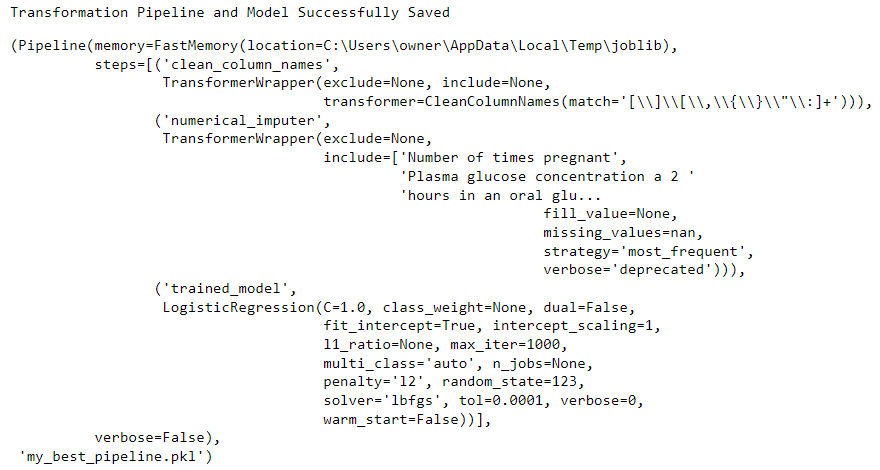
# 保存模型
save_model(best, "my_best_pipeline")
# 加载模型
loaded_model = load_model("my_best_pipeline")
print(loaded_model)

使用 PyCaret 进行回归任务
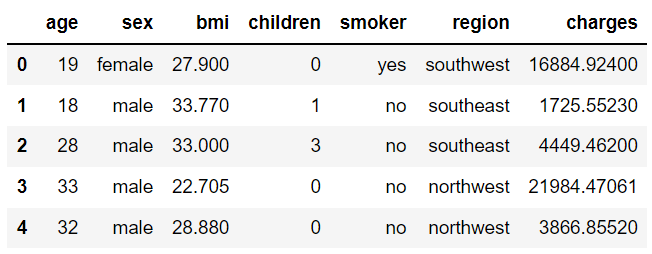
以 PyCaret 官方提供的 insurance 数据集为例。
# 加载数据集
from pycaret.datasets import get_data
insurance = get_data("insurance")
# 初始化回归实验
from pycaret.regression import *
s = setup(data, target="charges", session_id=123)

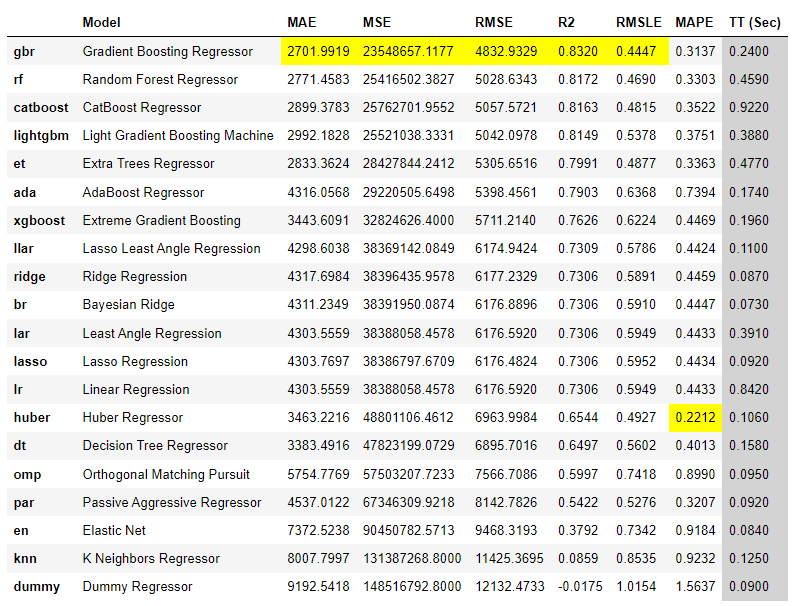
# 比较多个模型
best = compare_models()
# 打印最佳模型
print(best)

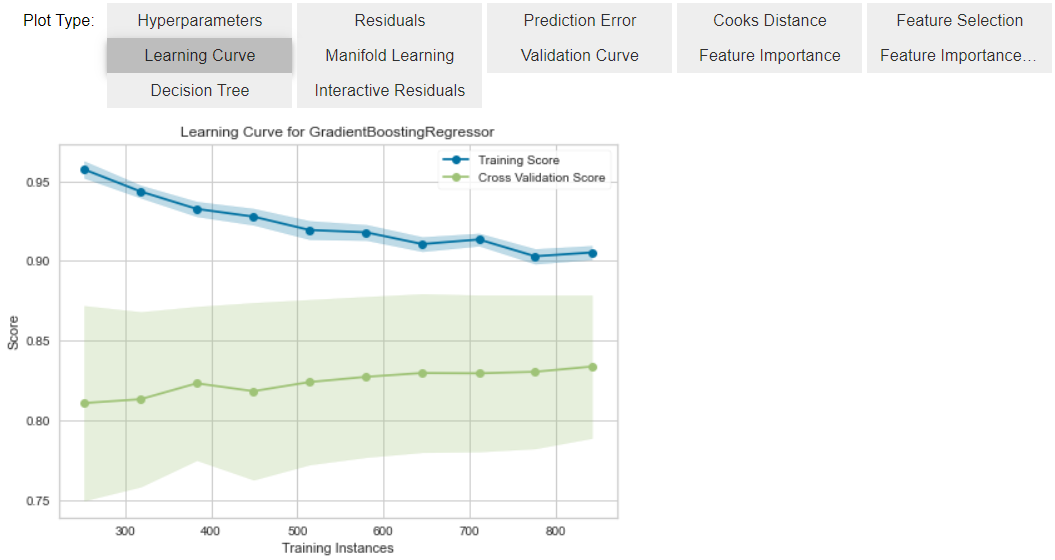
# 评估模型
evaluate_model(best)
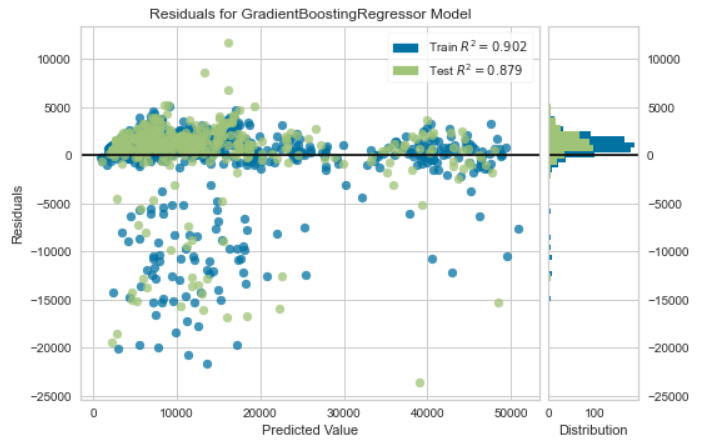
# 绘制残差分布图
plot_model(best, plot="residuals")
# 绘制特征重要性图
plot_model(best, plot="feature")
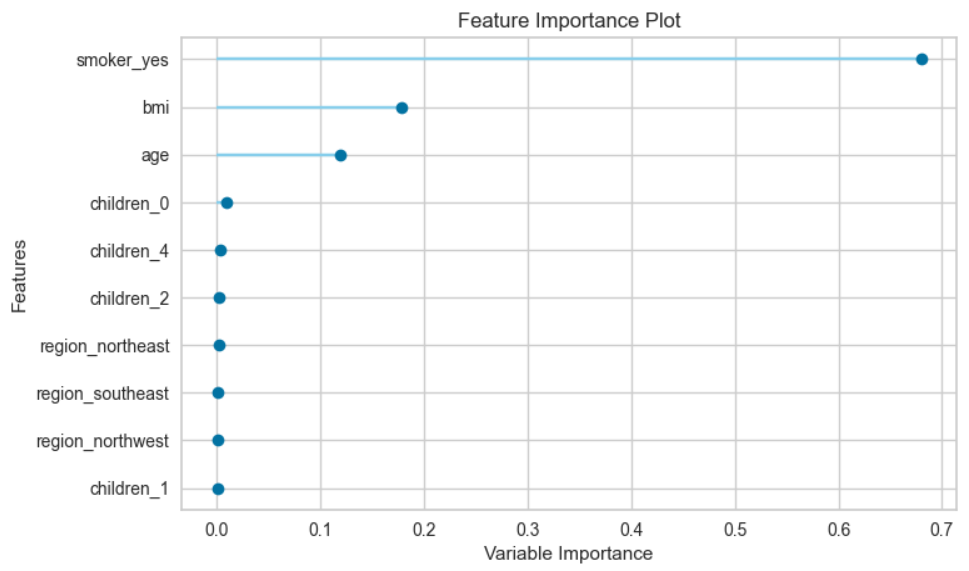
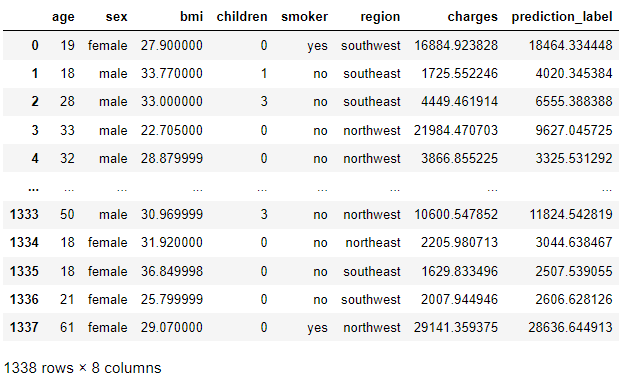
# 使用最优模型进行预测
predictions = predict_model(best, data=data)
predictions.head()
这篇关于机器学习 低代码 ML:PyCaret 的使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




