本文主要是介绍小白必看_从入门到实战的ElasticSearch7.6.1,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
此博客是学习了b站up主狂神说java的相关课程整理而来
适合没有接触过ElasticSearch的小白食用
狂神b站地址:https://space.bilibili.com/95256449/
如果需要相关的文件和Demo源码等资源,可以评论博主
编程之路漫长,本人也是今年上岸的小白一个,如果有志同道合的朋友可以加群一起学习讨论,互相帮助:817080571
概述
ElasticSearch ,简称为es,是一个开源的、高拓展的分布式全文检索引擎,它可以近乎实时的存储、检索数据。本身拓展性很好,可以拓展到上百台服务器,处理PB级别的数据。ElasticSearch使用java开发并且使用Lucene作为其核心来实现所有索引和搜索的功能,但是他的目的是通过简单的RestFul API来隐藏Lucene的复杂性,从而让全文检索变得简单。
ElasticSearch和Solr的比较
- es基本上是开箱即用,非常简单,Solr安装略麻烦;
- Solr利用Zookeeper进行分布式管理,而elasticsearch自身就带有分布式协调管理功能;
- Solr支持更多格式的数据,例如:json,xml,csv,而ElasticSearch仅仅支持json文件格式;
- Solr官方提供的功能更多,而ElasticSearch本身更注重核心功能,高级功能多由第三方插件提供,例如图形化界面需要kibana友好支持;
- Solr查询快,但更新索引时慢(即插入删除慢),用于电商的查询多的应用;
- ElasticSearch建立索引快(即查询慢),即实时性查询快,用于新浪的搜索;
- Solr是传统搜索应用的解决方案,但ElasticSearch更适用于新兴的实时搜索应用。
- Solr比较成熟,有一个更大、更成熟的用户、开发和贡献者社区,而ElasticSearch相对开发维护者较少,更新太快,学习使用成本较高。
ElasticSearch安装及启动
声明:ElasticSearch要求安装环境必须是要jdk1.8以上才行。
1、下载安装包

2、解压安装包完成解压

解压完成即安装完成。
3、ElasticSearch目录环境说明

- bin:可执行文件
- config:配置文件
- elasticsearch.yml:项目配置文件
- jvm.options:jvm相关的配置文件
- log4j2.properties:日志相关配置文件
- jdk:相关的jdk环境
- lib:项目所使用的相关jar包
- logs:日志信息
- modules:模块信息
- plugins:插件信息
4、启动ElasticSearch
双击elasticsearch.bat运行。

5、访问

访问成功!
可视化界面的安装
声明:可视化界面的安装必须基于node.js的环境
1、下载可视化界面的项目压缩包

2、解压

3、启动可视化页面
因为是基于node.js的前端项目,所以我们先要进入到项目文件,在cmd窗口中使用npm install命令安装相关环境,然后使用npm run start运行项目:

启动完成,访问端口是9100。
解决可视化界面访问ElasticSearch产生的跨域问题

可视化界面的端口是9100,通过可视化界面去访问9200的ElasticSearch会产生跨域问题。
修改ElasticSearch.yml文件让其支持跨域请求

在yml文件的最后加上允许跨域的配置,并重启ElasticSearch。
重启之后再使用可视化界面进行访问:

连接成功!
Kibana
概述
Kibana是一个针对ElasticSearch的开源分析及可视化平台,用于搜索、查看交互存储在ElasticSearch索引中的数据。使用Kibana,可以通过各种图表进行高级数据分析及展示。Kibana让海量数据更容易理解,它操作简单,基于浏览器的用户界面可以快速创建仪表板实时显示ElasticSearch查询动态。设置Kibana非常简单,无需编码或者额外的基础架构,几分钟就可以完成安装并启动索引监测。
注意事项:Kibana的版本必须要与安装的es版本一致。
我们可以将es理解为一个处理海量数据的数据库,Kibana可以监测并分析数据库中的数据信息。
Kibana的安装和启动
1、下载安装包

2、解压安装包

3、启动Kibana


4、访问

访问成功!
Kibana的汉化
Kibana是支持汉化的,我们只需要在他的项目yml文件中进行相关配置即可:

配置保存之后重启Kibana:

汉化完成!
ES核心概念
ElasticSearch是一个面向文档的数据库,其中的所有数据都是json,以下是各种专用名词和关系型数据库的对比:

ElasticSearch中可以包含多个索引(数据库),每个索引中可以包含多个类型(表),每个类型下又包含多个文档,每个文档中又包含多个字段。
物理设计:
ElasticSearch在后台把每个索引划分为多个分片,每份分片可以在集群的不同服务器间迁移。ElasticSearch一启动就是一个集群,哪怕只有一个,默认的集群名称为:elasticsearch。

逻辑设计
在ES中,一个索引中包含多个文档,当我们索引一篇文档时,可以通过这样的顺序找到它:索引>类型>文档ID。通过这个组合我们就能索引到某个具体的文档。
文档
文档的概念换算到关系型数据库中就类似于一条数据。
ES是面向文档的,也就意味着索引和搜索数据的最小单位是文档,在ElasticSearch中,文档有几个重要属性:
- 自我包含:一片文档同时包含字段和对应的值,也就是同时包含key-value;
- 可以是层次型的:一个文档包含另一个文档;
- 灵活的结构:文档不依赖预先定义的模式,我们知道关系型数据库中,要提前定义字段才能使用。在ElasticSearch中,对于字段是非常灵活的,有时候我们可以忽略该字段,或者动态的添加一个新的字段。
类型
类型是文档的逻辑容器,就像关系型数据库中表格是行的容器一样,类型对于字段的定义称之为映射,比如说name映射为字符串类型。
我们说文档是无模式的,我们不需要对我们新增的每一个字段的类型进行映射,在没有进行映射的时候Elasticsearch会对数据的类型进行猜测,但是也有可能会猜不对,所以最安全的方式提前定义好所需要的映射,这一部分就跟关系型数据库差不多了。
索引
索引就类似于关系型数据库中的数据库。
索引是映射类型的容器,ElasticSearch中的索引是一个非常大的文档集合。索引存储了映射类型的字段和其他设置,然后他们被保存到了各个分片上。
物理设计:节点和分片如何工作
一个集群至少有一个节点,就是最基本的elasticsearch进程,每个节点可以有多个索引,如果你创建索引,则,默认会创建5个分片(又称主分片),每一个分片都会有一个副本(又称复制分片)。

例如上图是一个有三个节点的集群,可以看到主分片对应的复制分片都不会在同一个节点内,这样就有利于如果某个节点挂掉了,数据也不至于丢失,
实际上,一个分片是一个lucene索引,一个包含倒排索引的文件目录,倒排索引的结构使得ElasticSearch在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字。
等等,倒排索引是什么????
倒排索引
Lucene采用倒排索引作为底层,这种设计适用于快速的全文搜索。
在ElasticSearch中,倒排索引的做法是对索引中的每个单词都进行重构为一个索引列表, 这样就可以清楚的反应每个单词在文档中的位置,当我们想要查找某个数据的时候,根据倒排索引生成的索引列表就可以最大限度的避免不符合数据的重复查询,只会在包含该数据的文档中进行查询。
例如下图数据:

在以上数据中可以得知:python这个词条,在1,2,3号文档中都有出现,linux这个词条在3,4号文档中出现,当我们想要查询linux这个词条的时候,根据倒排索引生成的索引列表,就不会再去查询1,2这两个文档,最大限度的避免了无用数据的查询。
ElasticSearch索引和Lucene索引的关系
在ElasticSearch中,每创建一个索引就会生成多个分片,其实每个分片就是一个Lucene索引,所以一个ElasticSearch索引本质就是用多个Lucene索引构成的。
ik分词器插件
什么是分词器?
分词的意思就是把一段文字分成一个个的关键字,我们在搜索的时候会把自己的信息进行分词,会把数据库中的数据进行分词,然后进行一个匹配操作。
例如,我搜索”奥特曼打小怪兽“,在搜索结果中你可能看到只包含”奥特曼“的信息,也有可能看到只包含"小怪兽"的信息,这就是程序对我们的搜索信息进行了分词。
而默认的中文分词器是将每一个字分成一个词,例如:”奥特曼“分解成”奥“”特“”曼“。这种粒度的分词显然是不太方便的,所以在此我们使用ik分词器插件。
ik分词器提供了两个分词算法:ik_smart和ik_max_word,其中ik_smart为最少切分,ik_max_word为最细粒度切分。
安装ik分词器
1、下载
2、将压缩包解压到ElsticSearch的插件包中

3、重启ElasticSearch

重启可以在日志中观察到ik分词器插件被加载。
4、使用ElasticSearch的命令查看插件是否安装成功
在ElasticSearch的bin目录中打开cmd窗口,输入命令elasticsearch-plugin list即可查看安装的插件列表:

使用Kibana发送请求展示ik分词器效果
json代码:
GET _analyze //请求分词器
{"analyzer": "ik_smart", //选择分词算法"text": "奥特曼打小怪兽"
}
分词效果:

由上可以看到,分词器会根据语句中的词语进行分割,但是他们怎么认使什么字连起来是一个词呢?这是因为在分词器的内部有一个自己的字典,可以识别常用的正常词语,当我们输入一个人名或者自己捏造的词语的时候就无法达到想要的效果,例如:

明显:梅雪是一个可爱鬼的名字,但是分词器却没法进行分词,因为内部的字典无法识别梅雪这两个字的组合。
此时,我们就需要给ik分词器的词典进行自定义。
自定义ik分词器词典信息
我们打开ik分词器的配置文件,发现可以在配置文件中自定义词典配置:
所以,我们先需要创建一个自己的词典:

如图,自定义了一个love.dic词典,并在其中保存了梅雪这个词条,然后将这个词典配置到xml节点中即可。

配置完成之后,重启es,查看效果:

自定义词典成功!
注意:自定义词典的文件编码格式必须是UTF-8,不然的话会无效。
ElasticSearch基本操作
操作ElasticSearch的命令都是通过RestFul风格的请求命令去完成的,大致如下图:

使用Kibana演示基础操作
创建一个索引
语法:
PUT /索引名/类型名/文档id
{请求体
}

在head页面上查看数据:

由以上示例可知,我们通过put命令创建了一个索引并添加了文档数据,但是我们并没有给这个索引映射类型,在ElasticSearch中数据有多少的数据类型呢?
ElasticSearch相关的数据类型:
- 字符串类型:text、keyword
- 数值类型:long、integer、short、byte、doule、float、half float、scaled float
- 日期类型:date
- 布尔值类型:boolean
- 二进制类型:binary
- 等等…
创建一个索引不赋值并指定类型

以上json命令只创建了一个test2索引并映射类型
查看索引信息

通过GET命令就可以查看到索引的信息,后面的目标准确到索引就查看索引信息,准确到文档就查看文档信息。
修改文档信息
修改文档信息有两种方式,第一种是通过PUT命令在原来的文档上添加数据进行覆盖,第二种是通过POST进行修改。
1)PUT覆盖修改
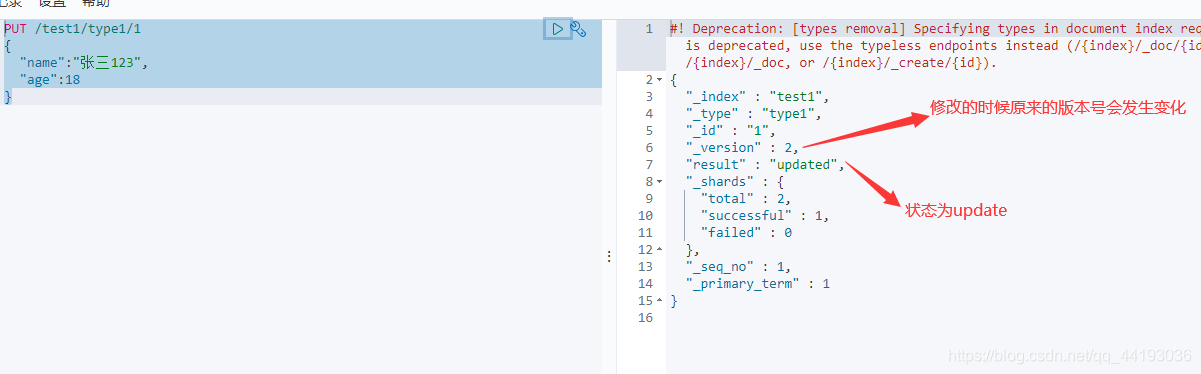
使用PUT进行修改有一个弊端,就是他会将所有的数据都进行覆盖,如果你修改的字段有缺漏,则缺漏的部分会被覆盖为空,造成数据的丢失。
2)POST方式修改

删除索引
删除索引信息通过DELETE命令来完成。
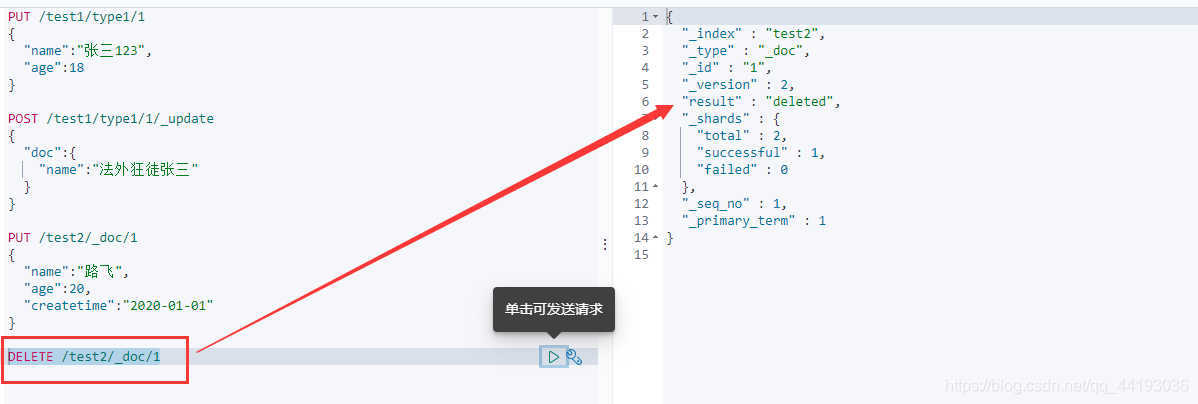
DELETE操作和GET操作一样,后面的目标精确到文档就删除文档信息,精确到索引就删除索引信息。
复杂查询操作
条件查询
语法:
GET 索引名/类型名/_search?q=字段名:字段值
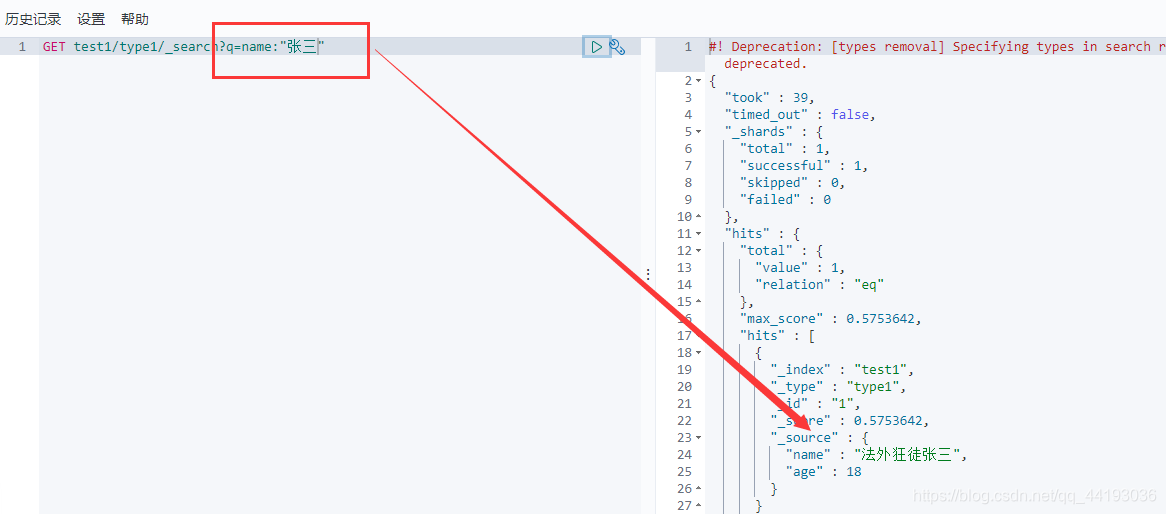
关于基础条件查询语句的解析:
其中_search后面的q的意思是query,在语法中是一个对象,完整的写法应该如下:
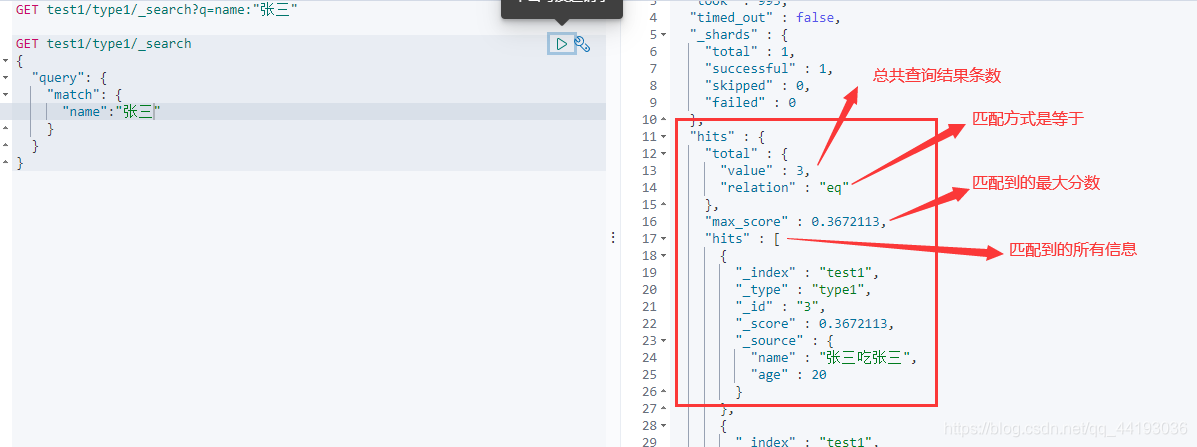
如上图所示,我们可以在query对象中设置很多的参数来完成各种情况下的查询方式。查询的结果中包含一个hits对象,这个对象的参数就包含了所有具体的查询结果。
条件查询_只显示某几个字段
默认情况下的条件查询会将文档的所有字段都查询出来,但是我们可以通过一个_source属性去指定想要查询出来的字段:
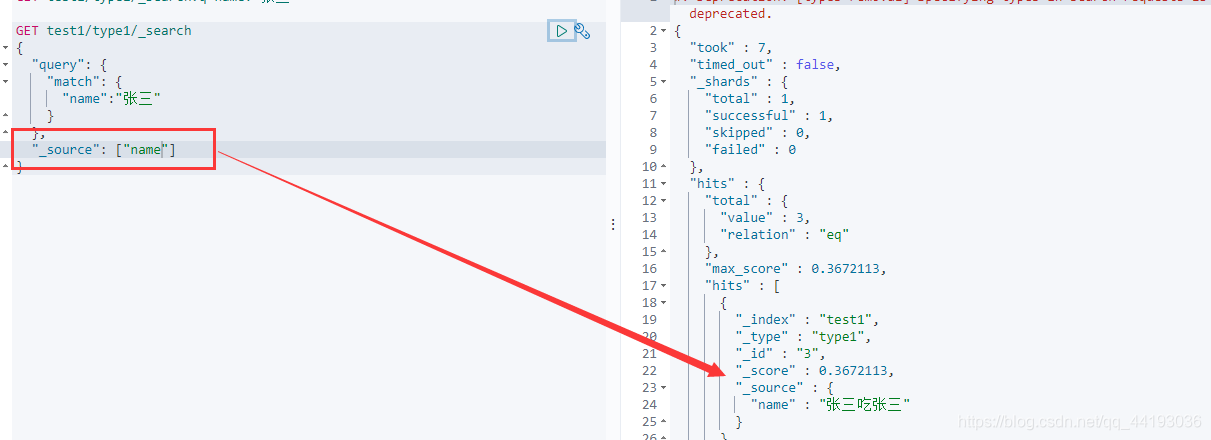
由上图可以看到,当我们指定了只查询"name"字段的时候,后面查询出来的信息中就只包含了"name"字段信息。
根据指定字段排序查询

如上图所示,按照age字段进行降序排列,因为我们自定义了按照某种规则进行排序吗,所以之前的排序规则分数就会为Null。
分页查询

我们可以通过设置"from"和"size"参数来设置分页查询的相关信息。
布尔值查询
通过布尔值查询的方式我们可以实现类似于数据库的多条件查询:

例如通过这个must指令就可以实现多条件查询,在上图中,只有同时满足name中包含张三,并且年龄为18的数据才会被查询出。
简单的来说满足这两个条件就会返回true的布尔值然后被查询出来,所以被叫做布尔值查询,相当于sql语句中的where and条件语句。

而should命令则表示后方的两个条件只需要满足其中之一即可,就类似于sql语句中的where or条件语句。

同理,must_not表示查询出不满足条件的数据,例如上图查询出年龄不为18的信息,相当于sql中的not条件语句。
过滤查询操作
在满足多种条件查询的同时,es也支持我们对查询的数据进行进一步的筛选过滤。

通过上图的配置可以实现按照年龄大小进行进一步过滤的操作,gte是大于等于操作,lte是小于等于操作,gt只表示大于操作,lt只表示小于操作。
同时,也可以同时设置大于和小于来进行值的区间搜索操作,相当于sql中的between and条件。

匹配多个条件查询
匹配多个条件查询就有点类似于sql中的in关键字。
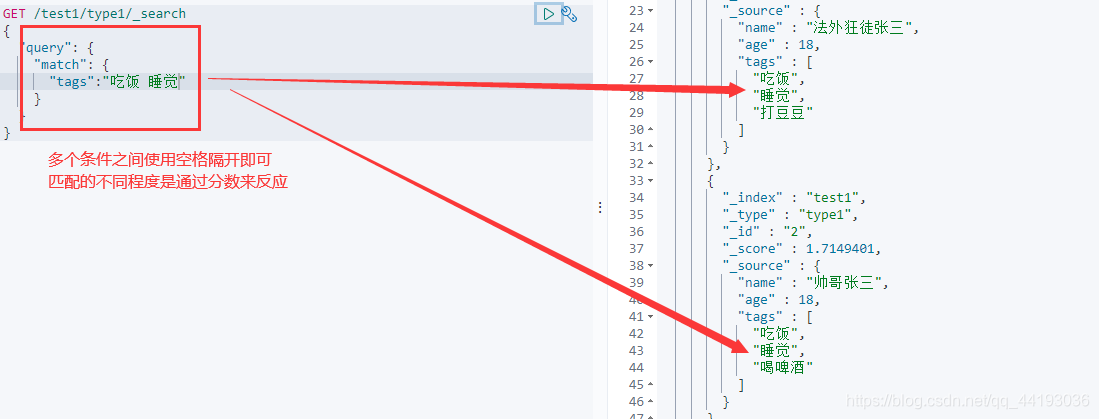
如图所示,tags是兴趣标签,在数据中是以数组的形式存在的,也就是说有多个值,通过这种方式就可以进行多个值的随意匹配。
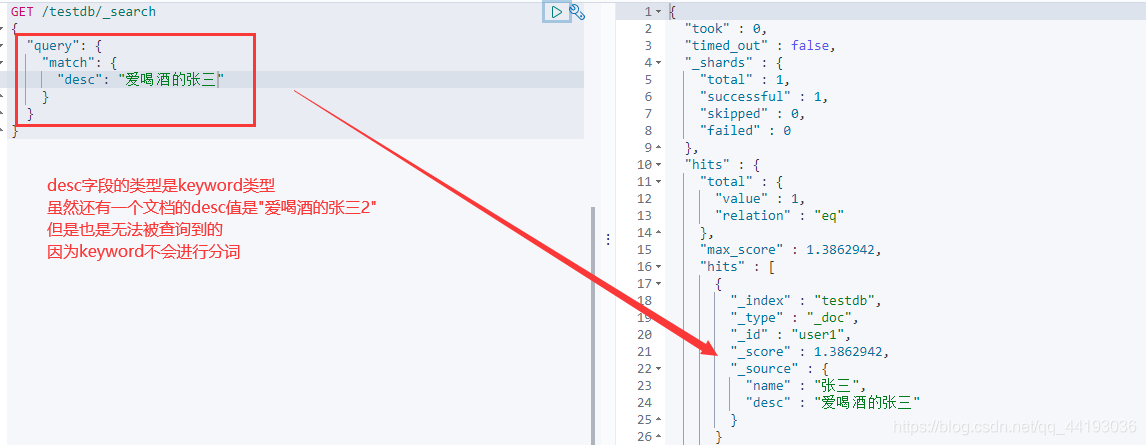
精确匹配term
term精确匹配和match的不同:
term会将条件依据倒排索引进行精确匹配,而match则会将查询条件进行分词然后再匹配。简单的来说,match会产生类似与模糊查询的效果,而term不会,条件匹配不上即使数据包含查询条件也不会被查询出来。
关于text和keyword类型:
text类型和keyword的不同之处在于,text会被分词器进行分词,而keyword不会被分词器分词。

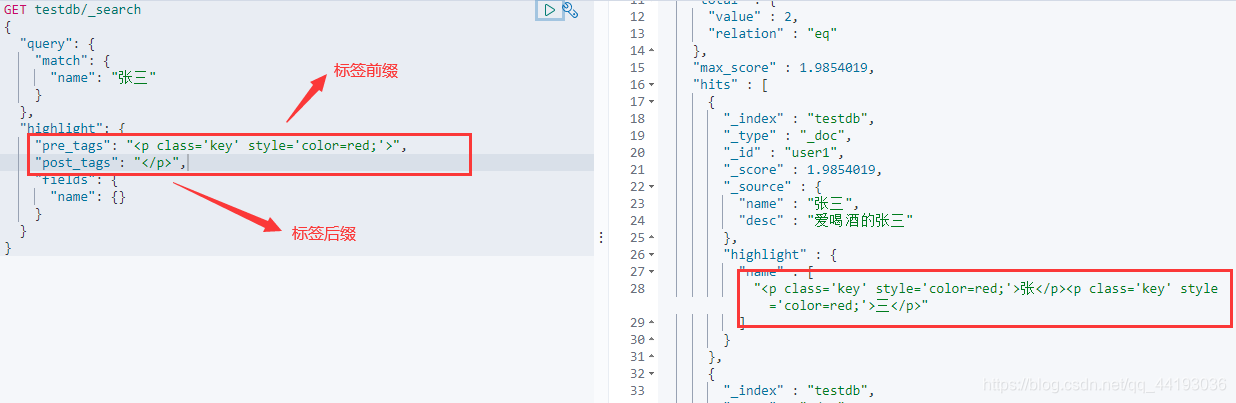
高亮查询
ElasticSearch同时也支持高亮查询,他会将查询结果中的查询条件关键字进行自动的高亮显示。
SpringBoot集成ElasticSearch
此次SpringBoot集成ElasticSearch采用SpringBoot脚手架来进行学习。
1、勾选引入ElasticSearch依赖
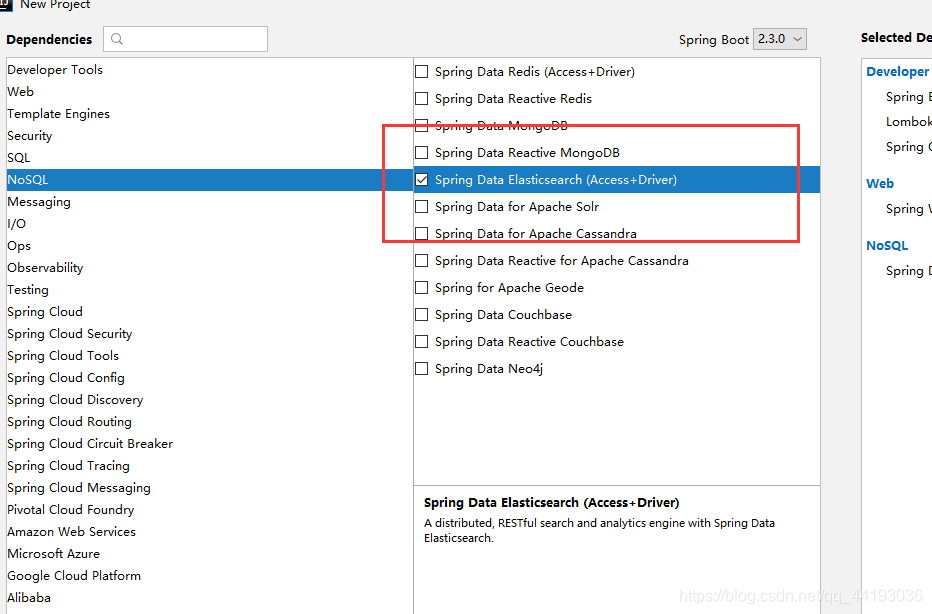
勾选之后需要注意的是,我们在此使用的SpringBoot版本为2.2.5,此版本的ES客户端并不是本地安装的7.6.1版本:
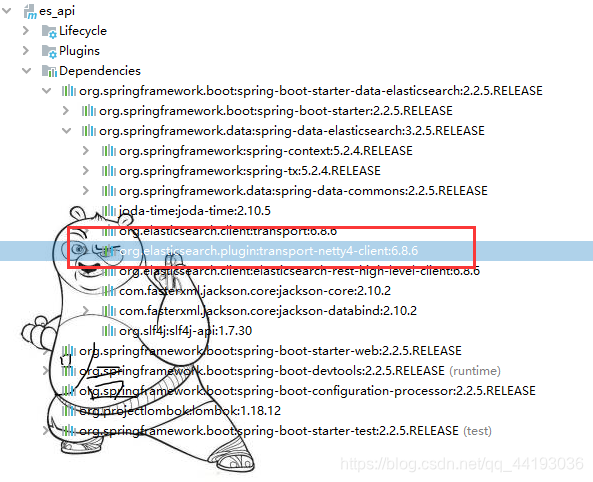
因此,我们需要在pom.xml进行ES客户端版本的自定义配置:

完成配置之后刷新项目,查看依赖版本:
版本依赖导入完成!
2、书写配置类将ES对象注入到Spring容器之中
package com.xsh.es_api.config;import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class ElasticSearchClientConfig {@Beanpublic RestHighLevelClient restHighLevelClient(){RestHighLevelClient client=new RestHighLevelClient(RestClient.builder(//ES集群的相关信息,如果有多个就配置多个new HttpHost("localhost",9200,"http")));return client;}
}
至此,SpringBoot集成ElasticSearch就完成了。
关于java操作ES索引的API
关于java API的学习都会在测试类中进行完成。
创建索引
@AutowiredRestHighLevelClient restHighLevelClient;//测试索引的创建@Testvoid createIndex() throws IOException {//创建索引请求CreateIndexRequest java_index = new CreateIndexRequest("java_index");//客户端执行请求创建索引CreateIndexResponse createIndexResponse = restHighLevelClient.indices().create(java_index, RequestOptions.DEFAULT);}
创建成功!

判断索引是否存在
@AutowiredRestHighLevelClient restHighLevelClient;//测试判断索引是否存在@Testvoid existIndex() throws IOException {GetIndexRequest java_index = new GetIndexRequest("java_index");boolean flag = restHighLevelClient.indices().exists(java_index, RequestOptions.DEFAULT);System.out.println(flag); //返回布尔值表示索引是否存在}
代码效果:

索引存在!
删除索引
@AutowiredRestHighLevelClient restHighLevelClient;//测试删除索引@Testvoid deleteIndex() throws IOException {DeleteIndexRequest java_index = new DeleteIndexRequest("java_index");AcknowledgedResponse delete = restHighLevelClient.indices().delete(java_index, RequestOptions.DEFAULT);System.out.println(delete.isAcknowledged()); //获取删除成功与否的提示信息}
代码效果:

删除成功!
关于java操作ES文档的API
添加文档
@AutowiredRestHighLevelClient restHighLevelClient;//测试添加文档@Testvoid addDocument() throws IOException {//创建对象User user=new User();user.setName("张三");user.setAge(18);//创建请求IndexRequest java_index = new IndexRequest("java_index");//填充规则java_index.id("1"); //文档编号//将对象放入请求中java_index.source(JSON.toJSONString(user), XContentType.JSON);//客户端发送请求,接收响应结果IndexResponse index = restHighLevelClient.index(java_index, RequestOptions.DEFAULT);//打印响应结果System.out.println(index.toString()); //查看返回的具体json信息System.out.println(index.status()); //查看操作的状态);}
因为ES只支持json格式的数据流通,所以在将对象放入请求的过程中需要将对象序列化为josn字符串,在此需要阿里巴巴的fastjson支持:
<dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.62</version></dependency>
查看添加文档结果:

添加成功!
判断文档是否存在
@AutowiredRestHighLevelClient restHighLevelClient;//测试判断文档是否存在@Testvoid ExistDocument() throws IOException {GetRequest java_index = new GetRequest("java_index", "1");boolean exists = restHighLevelClient.exists(java_index, RequestOptions.DEFAULT);System.out.println(exists); //返回布尔值表示是否存在}
代码结果:

一号文档存在!
获取文档信息
@AutowiredRestHighLevelClient restHighLevelClient;//测试获取文档信息@Testvoid getDocument() throws IOException {GetRequest java_index = new GetRequest("java_index", "1");GetResponse getResponse = restHighLevelClient.get(java_index, RequestOptions.DEFAULT);System.out.println(getResponse.getSourceAsString()); //打印文档的内容System.out.println(getResponse); //getResponse对象就包含ES的所有查询信息}
代码效果:
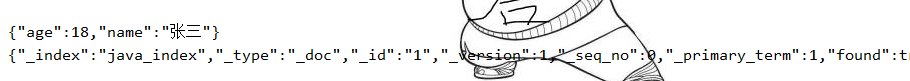
修改文档记录
@AutowiredRestHighLevelClient restHighLevelClient;//测试修改文档信息@Testvoid updateDocument() throws IOException {UpdateRequest java_index = new UpdateRequest("java_index", "1");User user=new User();user.setName("法外狂徒张三");user.setAge(20);java_index.doc(JSON.toJSONString(user),XContentType.JSON);UpdateResponse update = restHighLevelClient.update(java_index, RequestOptions.DEFAULT);System.out.println(update.status()); //查看更新状态}
查看结果:
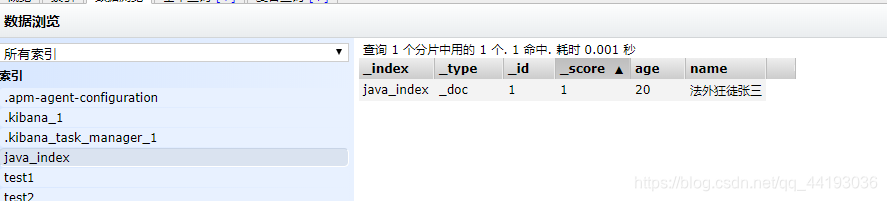
修改成功!
删除文档信息
@AutowiredRestHighLevelClient restHighLevelClient;//删除文档信息@Testvoid deleteDocument() throws IOException {DeleteRequest java_index = new DeleteRequest("java_index", "1");DeleteResponse delete = restHighLevelClient.delete(java_index,RequestOptions.DEFAULT);System.out.println(delete.status()); //查看删除状态}
查看结果:
删除成功!
批量操作
ES同时也支持批量增删改的操作,在此只演示批量添加操作:
@AutowiredRestHighLevelClient restHighLevelClient;//测试批量添加文档下信息@Testvoid bulkDocument() throws IOException {//创建批量操作对象BulkRequest bulkRequest = new BulkRequest();ArrayList<User> list = new ArrayList<>();list.add(new User("张三1",12));list.add(new User("张三2",12));list.add(new User("张三3",12));list.add(new User("张三4",12));list.add(new User("张三5",12));for (int i=0;i<list.size();i++){bulkRequest.add(new IndexRequest("java_index").id(""+(i+1)).source(JSON.toJSONString(list.get(i)),XContentType.JSON));}//发送请求BulkResponse bulk = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);System.out.println(bulk.hasFailures()); //查看状态,是否失败,返回false代表成功}
查看结果:

查询文档信息
@AutowiredRestHighLevelClient restHighLevelClient;//测试查询文档信息@Testvoid search() throws IOException {//创建请求对象SearchRequest java_index = new SearchRequest("java_index");//构造搜索条件SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();//使用工具类构造搜索信息MatchQueryBuilder query = QueryBuilders.matchQuery("name", "张三1");searchSourceBuilder.query(query);java_index.source(searchSourceBuilder);//发送请求SearchResponse search = restHighLevelClient.search(java_index, RequestOptions.DEFAULT);System.out.println(JSON.toJSONString(search.getHits())); //Hits对象就包含查询的各种信息}
查询结果:

Hits对象中包含的是所有的查询结果信息,我们可以通过遍历想要的参数获得具体的信息。
对于复杂查询的各种操作都可以在searchSourceBuilder对象的方法中找到对应的方法:

ElasticSeatch项目实战:京东搜索
此次项目实战采用java爬虫爬取京东的数据放在es数据源中,然后通过页面来模拟京东搜索。
1、项目搭建
创建项目并引入相关pom依赖
相关pom文件:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.2.5.RELEASE</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>com.xsh</groupId><artifactId>es_jdsearch</artifactId><version>0.0.1-SNAPSHOT</version><name>es_jdsearch</name><description>Demo project for Spring Boot</description><properties><java.version>1.8</java.version><elasticsearch.version>7.6.1</elasticsearch.version></properties><dependencies><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.62</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-thymeleaf</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-configuration-processor</artifactId><optional>true</optional></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope><exclusions><exclusion><groupId>org.junit.vintage</groupId><artifactId>junit-vintage-engine</artifactId></exclusion></exclusions></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build></project>
yml相关配置
server:port: 8080#关闭thymeleaf缓存
spring:thymeleaf:cache: false
引入静态资源

编写控制器访问index.html页面
package com.xsh.es_jdsearch.controller;import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;@Controller
public class IndexController {@RequestMapping("/")public String toIndex(){return "index";}
}
访问页面
2、使用jsoup爬取京东相关的数据
引入jsoup依赖
<dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.10.2</version></dependency>
编写工具类解析网页爬取数据
package com.xsh.es_jdsearch.utils;import com.xsh.es_jdsearch.pojo.Content;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;import java.io.IOException;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;public class HtmlParseUtils {public static void main(String[] args) throws IOException {parseJD("java").forEach(System.out::println);}public static List<Content> parseJD(String keyWord) throws IOException {//获取请求 https://search.jd.com/Search?keyword=javaString url="https://search.jd.com/Search?keyword="+keyWord;//根据url解析网页 Jsoup返回的document对象就是javascript中的页面对象,所有在javascript中能够使用的方法在这里都能使用Document document = Jsoup.parse(new URL(url), 30000); //第二个参数为最大连接时间,超时即报错//通过document对象获取页面上的一部分元素Element element = document.getElementById("J_goodsList"); //element是获取的商品列表的主要信息//获取到所有的li元素,商品信息部分是用ul来装载的,所以要先获取到所有的li元素Elements elements = element.getElementsByTag("li");//通过li标签我们可以获取到每一个li标签中的商品信息,在此我们主要获取三个部分:图片地址,标题,价格ArrayList<Content> contentList = new ArrayList<>();for (Element el: elements) { //每一个el都是一个li//获取图片地址,在此获取的并不是img的src属性,而是source-data-lazy-img属性//原因是因为京东为了追求网页渲染的速度,会在图片渲染之前先渲染一个默认的页面,而真实的图片路径会放在source-data-lazy-img中进行懒加载String img = el.getElementsByTag("img").eq(0).attr("src");String title = el.getElementsByClass("p-name").eq(0).text();String price = el.getElementsByClass("p-price").eq(0).text();Content content = new Content(img, title, price);contentList.add(content);}return contentList;}
}
注意:该类可以通过jsoup爬取页面上的相关信息,在爬取图片的时候狂神使用的是source-data-lazy-img属性,但是我在写的时候这个属性是无效的,还是使用的src属性才获取到的图片地址。
3、书写接口使用工具类将解析到的数据插入到ElasticSearch中
创建jd_index索引
在此通过图形化界面快速创建索引:

注入ElasticSearch客户端对象
要实现对ES数据进行操作,首先肯定要通过配置类来注入客户端对象:
package com.xsh.es_jdsearch.config;import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class ElasticSearchClientConfig {@Beanpublic RestHighLevelClient restHighLevelClient(){RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));return client;}
}
Controller代码展示
//添加数据到es接口@GetMapping("/insert/{keyword}")public Boolean insertToEs(@PathVariable("keyword") String keyword) throws IOException {return jdService.insertToEs(keyword);}
ServiceImpl代码展示
//批量插入使用jsoup查询到的数据@Overridepublic Boolean insertToEs(String keyword) throws IOException {List<Content> contents = HtmlParseUtils.parseJD(keyword);//创建批量插入对象BulkRequest bulkRequest = new BulkRequest();//封装数据for (int i=0;i<contents.size();i++){bulkRequest.add(new IndexRequest("jd_index").source(JSON.toJSONString(contents.get(i)), XContentType.JSON));}//发送请求进行数据插入BulkResponse bulk = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);return !bulk.hasFailures(); //返回结果是是否出现错误,插入成功则返回false,所以在此要取反}
访问接口就可以调用jsoup工具类将解析到的网页数据插入到es索引中,结果如下:
4、书写接口分页带条件查询信息
数据有了之后,就是做数据展示,在此接口接收查询的关键字和分页的信息进行分页并带条件的查询:
Controller接口代码展示
//分页查询数据接口@GetMapping("/search/{keyword}/{pageNo}/{pageSize}")public List<Map<String,Object>> search(@PathVariable("keyword") String keyword,@PathVariable("pageNo") int pageNo,@PathVariable("pageSize") int pageSize) throws IOException {return jdService.search(keyword,pageNo,pageSize);}
ServiceImpl代码展示
//分页查询public List<Map<String,Object>> search(String keyword,int pageNo,int pageSize) throws IOException {if(pageNo==0){pageNo=1;}//创建搜索对象SearchRequest jd_index = new SearchRequest("jd_index");//构造搜索条件SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();//配置分页信息sourceBuilder.from(pageNo);sourceBuilder.size(pageSize);//构造搜索条件TermQueryBuilder query = QueryBuilders.termQuery("title", keyword);//封装搜索条件sourceBuilder.query(query);//封装搜索对象jd_index.source(sourceBuilder);//发送请求SearchResponse response = restHighLevelClient.search(jd_index, RequestOptions.DEFAULT);List<Map<String,Object>> list=new ArrayList<>();for (SearchHit hit : response.getHits().getHits()) {list.add(hit.getSourceAsMap());}return list;}
5、采用Vue+axios进行前后端分离数据展示
使用npm下载vue.js和axios.js的相关文件
首先我们随便创建一个英文名称的文件夹,在其中使用cmd命令行npm init来初始化,使用npm install vue和npm install axios来下载依赖。

下载结果:
在项目中引入vue.min.js和axios.min.js文件:


修改页面信息,动态绑定搜索框的数据和搜索按钮的单击事件,实现单击搜索按钮就发送请求进行ES库的查询,并且使用v-for将查询结果进行遍历显示,以下仅展示vue对象的相关代码:
<script>new Vue({el : "#app",data : {keyword : "", //搜索条件results : [] //返回结果集},methods :{searchKey(){let key=this.keyword;console.log(key);axios.get("/JD/search/"+key+"/1/10").then(result=>{console.log(result);this.results=result.data;})}}})
</script>
查看页面查询效果

以上,我们就通过代码完成了es数据库的查询操作,可以用来做页面的搜索功能。
但是如上图所示,我们不仅实现了搜索功能,还实现了关键字结果的高亮,这是因为接口的不同:
6、分页待条件且关键字高亮查询
ServiceImpl代码展示
//高亮分页查询public List<Map<String,Object>> searchHighLight(String keyword,int pageNo,int pageSize) throws IOException {if(pageNo==0){pageNo=1;}//创建搜索对象SearchRequest jd_index = new SearchRequest("jd_index");//构造搜索条件SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();//配置分页信息sourceBuilder.from(pageNo);sourceBuilder.size(pageSize);//封装高亮显示条件HighlightBuilder highlightBuilder = new HighlightBuilder();highlightBuilder.field("title"); //对哪个字段进行高亮highlightBuilder.preTags("<span style='color:red'>"); //设置高亮前缀highlightBuilder.postTags("</span>"); //高亮后缀//构造搜索条件TermQueryBuilder query = QueryBuilders.termQuery("title", keyword);//封装搜索条件sourceBuilder.query(query);sourceBuilder.highlighter(highlightBuilder); //封装高亮搜索条件//封装搜索对象jd_index.source(sourceBuilder);//发送请求SearchResponse response = restHighLevelClient.search(jd_index, RequestOptions.DEFAULT);List<Map<String,Object>> list=new ArrayList<>();for (SearchHit hit : response.getHits().getHits()) {Map<String, HighlightField> highlightFields = hit.getHighlightFields();HighlightField title = highlightFields.get("title"); //高亮之后的titleMap<String, Object> sourceAsMap = hit.getSourceAsMap(); //未高亮之前的结果集//接下来就是将高亮的title与结果集中未高亮的title进行替换if(title!=null){Text[] fragments = title.fragments();String newTitle="";for (Text text : fragments) {newTitle+=text;}sourceAsMap.put("title",newTitle); //替换掉未高亮的title}list.add(sourceAsMap);}return list;}
欢迎关注博主的微信公众号,以后也会在微信公众号分享个人精品文章笔记:

这篇关于小白必看_从入门到实战的ElasticSearch7.6.1的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






