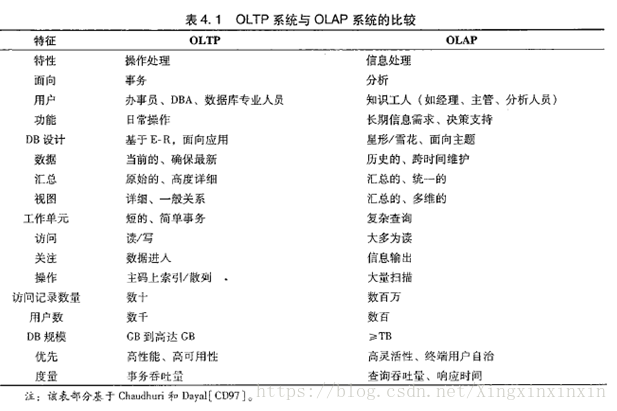
一句话区别
- OLTP:基于行存储的关系数据库,写入速度极快,用于数据记录修改场景,MySQL、Oracle
- OLAP:基于列存储,查询速度极快,用于海量数据分析,Clickhouse、Vertica、 Amazon Redshift、 Sybase IQ、 Exasol、 Infobright、 InfiniDB、 LucidDB、 SAP HANA、 Google Dremel
- 列族:使用k-v + 时间戳存储,用于大表大数据存储,分布式存储,带版本时序操作等场景,HBase、Cassandra、BigTable(google)
区别
1.在数据写入上的对比
1)行存储的写入是一次完成。如果这种写入建立在操作系统的文件系统上,可以保证写入过程的成功或者失败,数据的完整性因此可以确定。
2)列存储由于需要把一行记录拆分成单列保存,写入次数明显比行存储多(意味着磁头调度次数多,而磁头调度是需要时间的,一般在1ms~10ms),再加上磁头需要在盘片上移动和定位花费的时间,实际时间消耗会更大。所以,行存储在写入上占有很大的优势。
3)还有数据修改,这实际也是一次写入过程。不同的是,数据修改是对磁盘上的记录做删除标记。行存储是在指定位置写入一次,列存储是将磁盘定位到多个列上分别写入,这个过程仍是行存储的列数倍。所以,数据修改也是以行存储占优。
2.在数据读取上的对比
1)数据读取时,行存储通常将一行数据完全读出,如果只需要其中几列数据的情况,就会存在冗余列,出于缩短处理时间的考量,消除冗余列的过程通常是在内存中进行的。
2)列存储每次读取的数据是集合的一段或者全部,不存在冗余性问题。
3) 两种存储的数据分布。由于列存储的每一列数据类型是同质的,不存在二义性问题。比如说某列数据类型为整型(int),那么它的数据集合一定是整型数据。这种情况使数据解析变得十分容易。相比之下,行存储则要复杂得多,因为在一行记录中保存了多种类型的数据,数据解析需要在多种数据类型之间频繁转换,这个操作很消耗CPU,增加了解析的时间。所以,列存储的解析过程更有利于分析大数据。
OLAP-OLTP 的查询性能对比
以OLAP ClickHouse为例,可以看出在1亿条数据情况下,MySQL和Hive比ClickHouse慢289倍和831倍
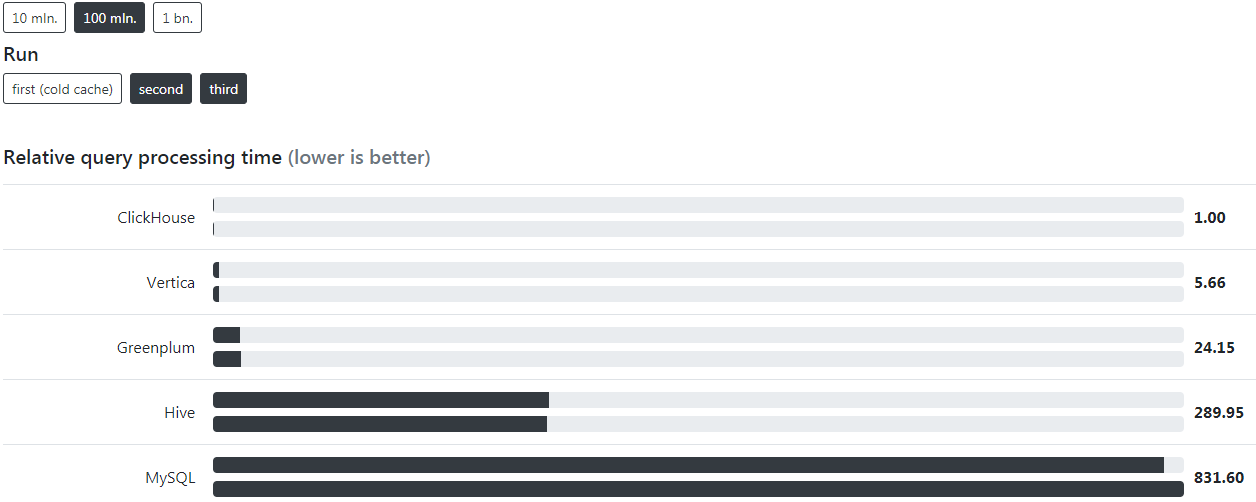
https://clickhouse.tech/benchmark/dbms/#[%22100000000%22,[%22ClickHouse%22,%22Vertica%22,%22Hive%22,%22MySQL%22,%22MemSQL%22,%22Greenplum%22],[%221%22,%222%22]]
ClickHouse有个在线的domo,可以试试查询它1亿行的表(hits_100m_obfuscated)复杂查询的速度,挺惊人。
https://play.clickhouse.tech/?file=welcome
存储方式
行式数据库OLTP
在传统的行式数据库系统中,数据按如下顺序存储:
| row | watchID | JavaEnable | title | GoodEvent | EventTime |
|---|---|---|---|---|---|
| #0 | 89354350662 | 1 | 投资者关系 | 1 | 2016-05-18 05:19:20 |
| #1 | 90329509958 | 0 | 联系我们 | 1 | 2016-05-18 08:10:20 |
| #2 | 89953706054 | 1 | 任务 | 1 | 2016-05-18 07:38:00 |
| #N | … | … | … | … | … |
处于同一行中的数据总是被物理的存储在一起。mysql innodb数据还和索引放在一起。
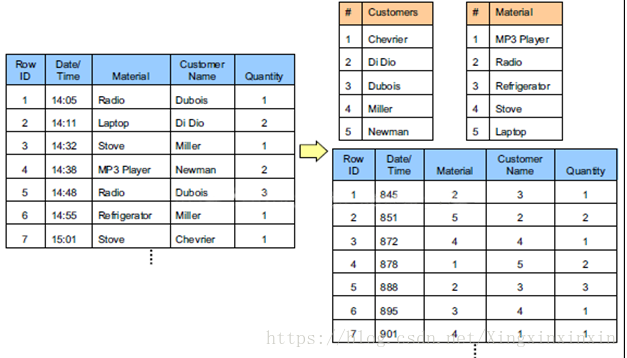
列式数据库OLAP
在列式数据库系统中,数据按如下的顺序存储:
| row: | #0 | #1 | #2 | #N |
|---|---|---|---|---|
| watchID: | 89354350662 | 90329509958 | 89953706054 | … |
| JavaEnable: | 1 | 0 | 1 | … |
| title: | 投资者关系 | 联系我们 | 任务 | … |
| GoodEvent: | 1 | 1 | 1 | … |
| EventTime: | 2016-05-18 05:19:20 | 2016-05-18 08:10:20 | 2016-05-18 07:38:00 | … |
该示例中只展示了数据在列式数据库中数据的排列方式。
实际上列式数据库还应该有一个内部索引,左边是行数据库,右边是列数据库
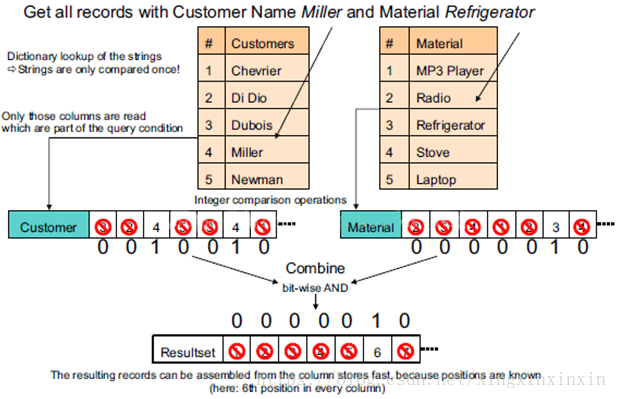
将Customes Name列及Material列做逻辑化索引标识,查询时分别匹配Materia=Refrigerator及Customes Name=Miller的数据,然后做交叉匹配。
列族数据库的存储模型
核心是k-v 加 时间戳存储。

场景
行式存储的适用场景:
1、适合随机的增删改查操作;
2、需要在行中选取所有属性的查询操作;
3、需要频繁插入或更新的操作,其操作与索引和行的大小更为相关。
列式存储的适用场景:
一般来说,一个OLAP类型的查询可能需要访问几百万甚至几十亿个数据行,且该查询往往只关心少数几个数据列。例如,查询今年销量最高的前20个商品,这个查询只关心三个数据列:时间(date)、商品(item)以及销售量(sales amount)
列族存储的适用场景:
列族是一种K-V方式的行列混合存储模式,这种模式能够同时满足OLTP和OLAP的查询需求。
但写效率不如行式,读效率不如列式
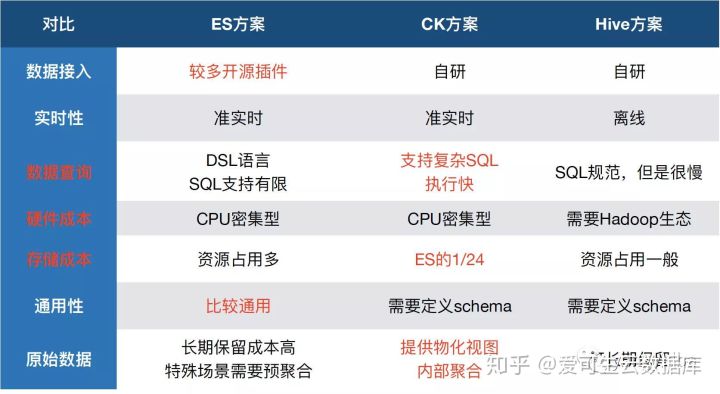
OLAP-ClickHouse应用场景分析
新近极热门的ClickHouse大有干掉ES、Hodoop生态链如Hive、HBase的趋势的可能。
使用ClickHouse作为OLAP服务的常见的应用场景包括:监控系统、ABtest、用户行为分析、BI报表,特征分析等。
hadoop VS OLAP ClickHouse
- Hadoop 体系是一种离线系统,一般很难支持即席查询。ClickHouse 可以支持即席查询。
- Hadoop 体系一般不支持实时更新,都采用批量更新和写入。ClickHouse 支持实时数据更新。
- Hadoop 体系一般采用行记录存储,数据查询需要扫描所有列,当表很宽时会扫描很多用不到的列。ClickHouse 是列式存储,查询只需要加载相关的列。
目前大量使用 ClickHouse 的互联网公司:
1. 今日头条内部用 ClickHouse 来做用户行为分析,内部一共几千个 ClickHouse 节点,单集群最大 1200 节点,总数据量几十 PB,日增原始数据 300TB 左右。
2. 腾讯内部用 ClickHouse 做游戏数据分析,并且为之建立了一整套监控运维体系。
3. 携程内部从 18 年 7 月份开始接入试用,目前 80% 的业务都跑在 ClickHouse 上。每天数据增量十多亿,近百万次查询请求。
4. 快手内部也在使用 ClickHouse,存储总量大约 10PB, 每天新增 200TB, 90% 查询小于 3S。
5. 在国外,Yandex 内部有数百节点用于做用户点击行为分析,CloudFlare、Spotify 等头部公司也在使用。
ClickHouse 高性能的背后
建议读这篇:
https://mp.weixin.qq.com/s/Exod626T4Q27tajyxQi4iQ







