本文主要是介绍SpringCloudAlibaba组件总结笔记(如Nacos、SpringCloudGateway、OpenFeign,Ribbon,RabbitMQ),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这目录
- 1.Ribbon负载均衡
- 1负载均衡原理
- 2.负载均衡策略
- 1.负载均衡策略
- 2.自定义负载均衡策略
- 3.饥饿加载
- 2.Nacos注册中心与Eureka的区别
- 3.Nacos配置中心
- 1.从微服务拉取配置
- 2.配置热更新
- 1.2.1.方式一
- 1.2.2.方式二
- 3.配置共享
- 1.配置共享的优先级
- 4.Feign
- 1.Feign使用优化
- 2.配置连接池参数
- 5.Gateway服务网关
- 1.网关的**核心功能特性**:
- 2.过滤器执行顺序
- 6.Docker
- 7.RabbitMQ
- 1.RabbitMQ介绍
- 1.同步调用
- 2.异步调用
- 3.几种常见MQ的对比:
- 4.RabbitMQ中的一些角色:
- 2.RabbitMQ 5个消息模型
- a.SpringAMQP
- 1.Basic Queue 简单队列模型
- 2.WorkQueue
- 3.4.5发布/订阅的三个模型
- 3.Fanout:广播
- 4.Direct:路由(定向)
- 5.Topic:话题(通配符)
1.Ribbon负载均衡
配置Nacos或者Eureka是,我们添加了@LoadBalanced注解,即可实现负载均衡功能,这是什么原理呢?
1负载均衡原理
SpringCloud底层其实是利用了一个名为Ribbon的组件,来实现负载均衡功能的。

那么我们发出的请求明明是http://userservice/user/1,怎么变成了http://localhost:8081的呢?
SpringCloudRibbon的底层采用了一个拦截器,拦截了RestTemplate发出的请求,对地址做了修改。用一幅图来总结一下:
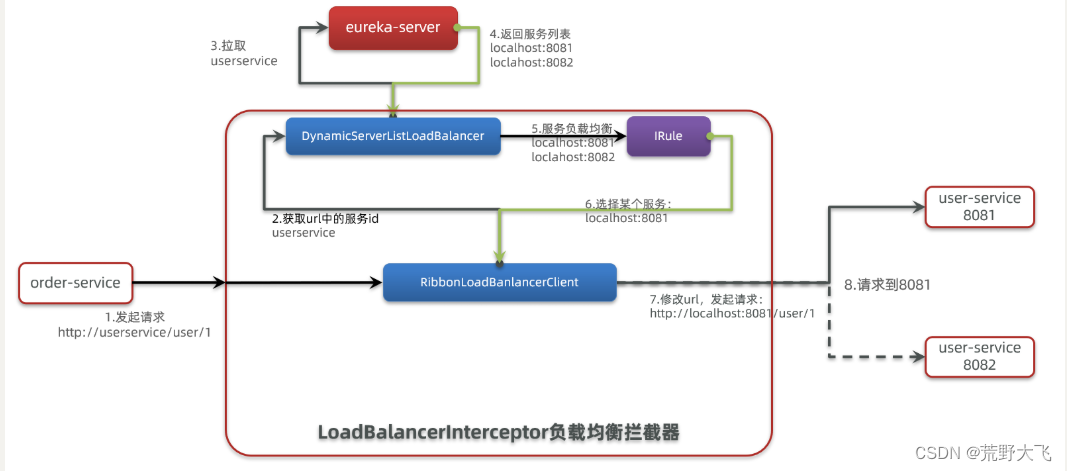
基本流程如下:
- 拦截我们的RestTemplate请求http://userservice/user/1
- RibbonLoadBalancerClient会从请求url中获取服务名称,也就是user-service
- DynamicServerListLoadBalancer根据user-service到eureka拉取服务列表
- eureka返回列表,localhost:8081、localhost:8082
- IRule利用内置负载均衡规则,从列表中选择一个,例如localhost:8081
- RibbonLoadBalancerClient修改请求地址,用localhost:8081替代userservice,得到http://localhost:8081/user/1,发起真实请求
2.负载均衡策略
1.负载均衡策略
负载均衡的规则都定义在IRule接口中,而IRule有很多不同的实现类:
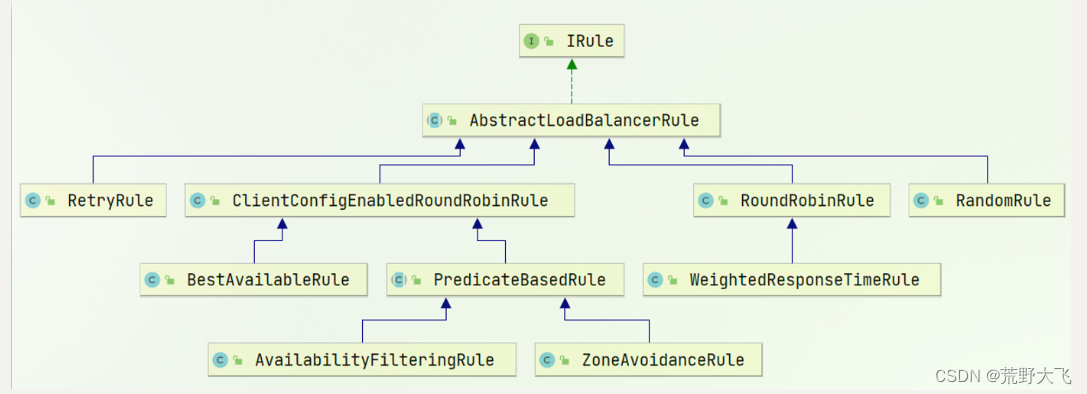
不同规则的含义如下:
| 内置负载均衡规则类 | 规则描述 |
|---|---|
| RoundRobinRule | 简单轮询服务列表来选择服务器。它是Ribbon默认的负载均衡规则。 |
| AvailabilityFilteringRule | 对以下两种服务器进行忽略: (1)在默认情况下,这台服务器如果3次连接失败,这台服务器就会被设置为“短路”状态。短路状态将持续30秒,如果再次连接失败,短路的持续时间就会几何级地增加。 (2)并发数过高的服务器。如果一个服务器的并发连接数过高,配置了AvailabilityFilteringRule规则的客户端也会将其忽略。并发连接数的上限,可以由客户端的..ActiveConnectionsLimit属性进行配置。 |
| WeightedResponseTimeRule | 为每一个服务器赋予一个权重值。服务器响应时间越长,这个服务器的权重就越小。这个规则会随机选择服务器,这个权重值会影响服务器的选择。 |
| ZoneAvoidanceRule | 以区域可用的服务器为基础进行服务器的选择。使用Zone对服务器进行分类,这个Zone可以理解为一个机房、一个机架等。而后再对Zone内的多个服务做轮询。 |
| BestAvailableRule | 忽略那些短路的服务器,并选择并发数较低的服务器。 |
| RandomRule | 随机选择一个可用的服务器。 |
| RetryRule | 重试机制的选择逻辑 |
默认的实现就是ZoneAvoidanceRule,是一种轮询方案
2.自定义负载均衡策略
通过定义IRule实现可以修改负载均衡规则,有两种方式:
- 代码方式:在order-service中的OrderApplication类中,定义一个新的IRule:
@Bean
public IRule randomRule(){return new RandomRule();
}
- 配置文件方式:在order-service的application.yml文件中,添加新的配置也可以修改规则:
userservice: # 给某个微服务配置负载均衡规则,这里是userservice服务ribbon:NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule # 负载均衡规则
注意,一般用默认的负载均衡规则,不做修改。
3.饥饿加载
Ribbon默认是采用懒加载,即第一次访问时才会去创建LoadBalanceClient,请求时间会很长。
而饥饿加载则会在项目启动时创建,降低第一次访问的耗时,通过下面配置开启饥饿加载:
ribbon:eager-load:enabled: trueclients: userservice
2.Nacos注册中心与Eureka的区别
Nacos的服务实例分为两种l类型:
-
临时实例:如果实例宕机超过一定时间,会从服务列表剔除,默认的类型。
-
非临时实例:如果实例宕机,不会从服务列表剔除,也可以叫永久实例。
配置一个服务实例为永久实例:
spring:cloud:nacos:discovery:ephemeral: false # 设置为非临时实例
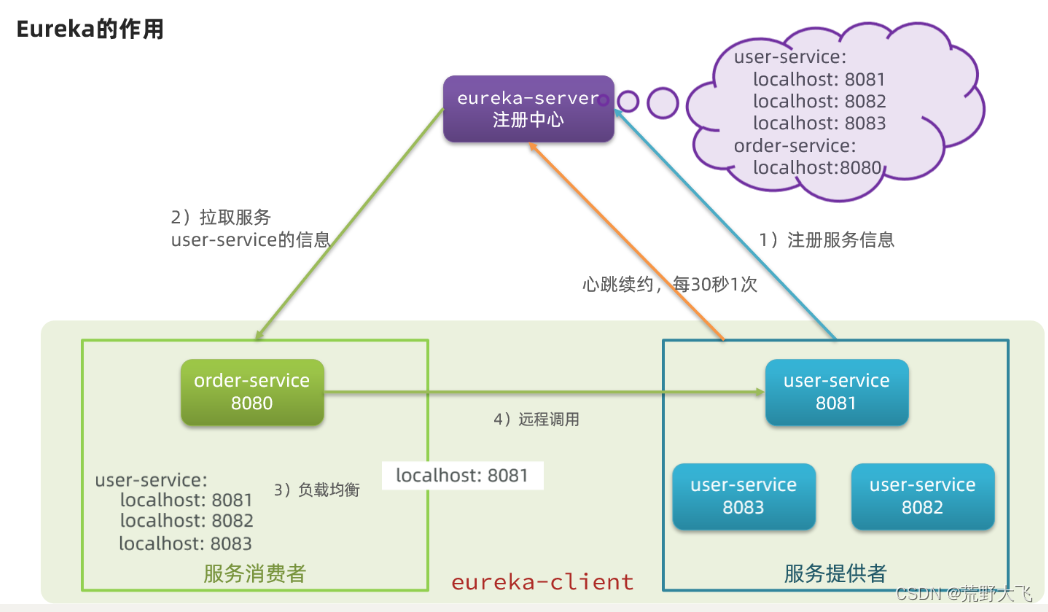
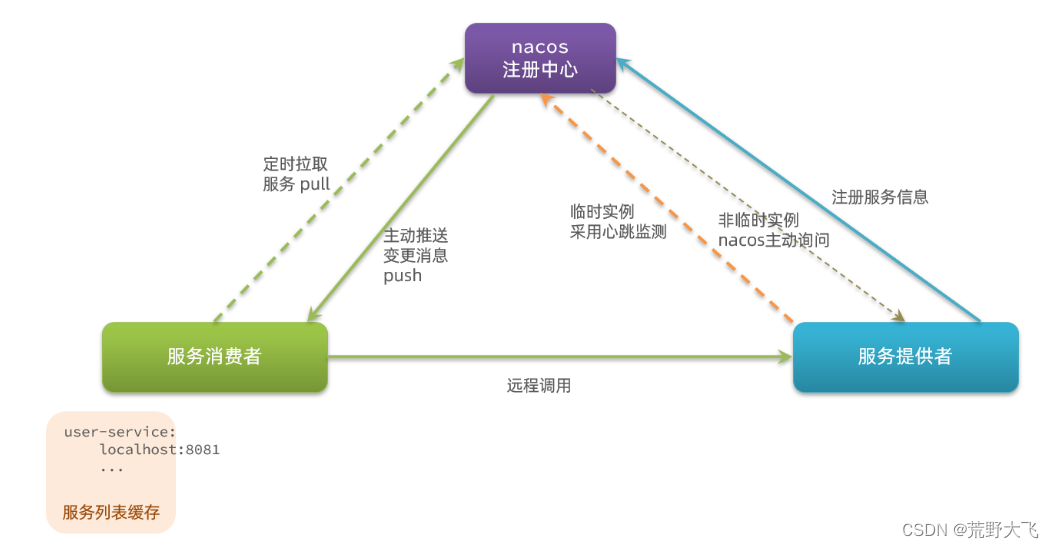
Nacos和Eureka整体结构类似,服务注册、服务拉取、心跳等待,但是也存在一些差异:
-
Nacos与eureka的共同点
- 都支持服务注册和服务拉取
- 都支持服务提供者心跳方式做健康检测
-
Nacos与Eureka的区别
- Nacos支持服务端主动检测提供者状态:临时实例采用心跳模式,非临时实例采用主动检测模式
- 临时实例心跳不正常会被剔除,非临时实例则不会被剔除
- Nacos支持服务列表变更的消息推送模式,服务列表更新更及时
- Nacos集群默认采用AP方式,当集群中存在非临时实例时,采用CP模式;Eureka采用AP方式
3.Nacos配置中心
注意:项目的核心配置,需要热更新的配置才有放到nacos管理的必要。基本不会变更的一些配置还是保存在微服务本地比较好。
1.从微服务拉取配置
微服务要拉取nacos中管理的配置,并且与本地的application.yml配置合并,才能完成项目启动。
但如果尚未读取application.yml,又如何得知nacos地址呢?
因此spring引入了一种新的配置文件:bootstrap.yaml文件,会在application.yml之前被读取,流程如下:
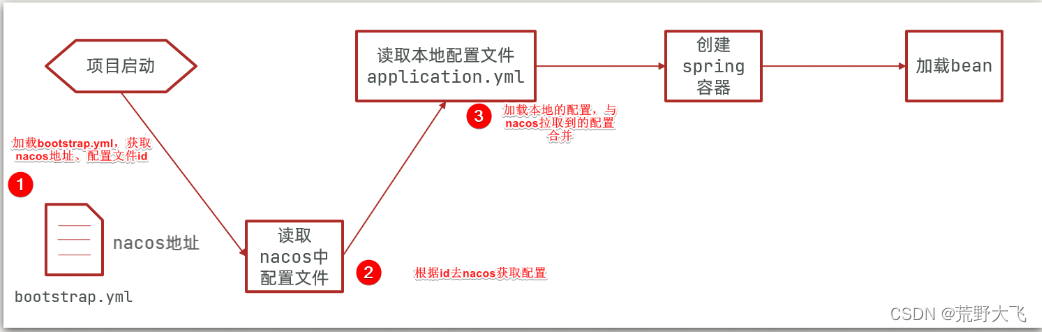
1)引入nacos-config依赖
2)添加bootstrap.yaml
然后,在user-service中添加一个bootstrap.yaml文件,内容如下:
spring:application:name: userservice # 服务名称profiles:active: dev #开发环境,这里是dev cloud:nacos:server-addr: localhost:8848 # Nacos地址config:file-extension: yaml # 文件后缀名
这里会根据spring.cloud.nacos.server-addr获取nacos地址,再根据
${spring.application.name}-${spring.profiles.active}.${spring.cloud.nacos.config.file-extension}作为文件id,来读取配置。
本例中,就是去读取userservice-dev.yaml:

2.配置热更新
我们最终的目的,是修改nacos中的配置后,微服务中无需重启即可让配置生效,也就是配置热更新。
要实现配置热更新,可以使用两种方式:
1.2.1.方式一
在@Value注入的变量所在类上添加注解@RefreshScope:
1.2.2.方式二
使用@ConfigurationProperties注解代替@Value注解。
在user-service服务中,添加一个类,读取patterrn.dateformat属性:
3.配置共享
其实微服务启动时,会去nacos读取多个配置文件,例如:
-
[spring.application.name]-[spring.profiles.active].yaml,例如:userservice-dev.yaml -
[spring.application.name].yaml,例如:userservice.yaml
而[spring.application.name].yaml不包含环境,因此可以被多个环境共享。
1.配置共享的优先级
当nacos、服务本地同时出现相同属性时,优先级有高低之分:

4.Feign
Feign客户端也集成了Ribbon负载均衡
1.Feign使用优化
Feign底层发起http请求,依赖于其它的框架。其底层客户端实现包括:
-
URLConnection:默认实现,不支持连接池
-
Apache HttpClient :支持连接池
-
OKHttp:支持连接池
因此提高Feign的性能主要手段就是使用连接池代替默认的URLConnection。
2.配置连接池参数
在order-service的application.yml中添加配置:
feign:client:config:default: # default全局的配置loggerLevel: BASIC # 日志级别,BASIC就是基本的请求和响应信息httpclient:enabled: true # 开启feign对HttpClient的支持max-connections: 200 # 最大的连接数max-connections-per-route: 50 # 每个路径的最大连接数
5.Gateway服务网关
1.网关的核心功能特性:
- 身份验证,权限控制
- 服务路由,负载均衡
- 请求限流
权限控制:网关作为微服务入口,需要校验用户是是否有请求资格,如果没有则进行拦截。
路由和负载均衡:一切请求都必须先经过gateway,但网关不处理业务,而是根据某种规则,把请求转发到某个微服务,这个过程叫做路由。当然路由的目标服务有多个时,还需要做负载均衡。
限流:当请求流量过高时,在网关中按照下流的微服务能够接受的速度来放行请求,避免服务压力过大。
网关搭建步骤:
-
创建项目,引入nacos服务发现和gateway依赖
-
配置application.yml,包括服务基本信息、nacos地址、路由
路由配置包括:
- 路由id:路由的唯一标示
- 路由目标(uri):路由的目标地址,http代表固定地址,lb代表根据服务名负载均衡
- 路由断言(predicates):判断路由的规则,
- 路由过滤器(filters):对请求或响应做处理
2.过滤器执行顺序
请求进入网关会碰到三类过滤器:当前路由的过滤器、DefaultFilter、GlobalFilter
请求路由后,会将当前路由过滤器和DefaultFilter、GlobalFilter,合并到一个过滤器链(集合)中,排序后依次执行每个过滤器:
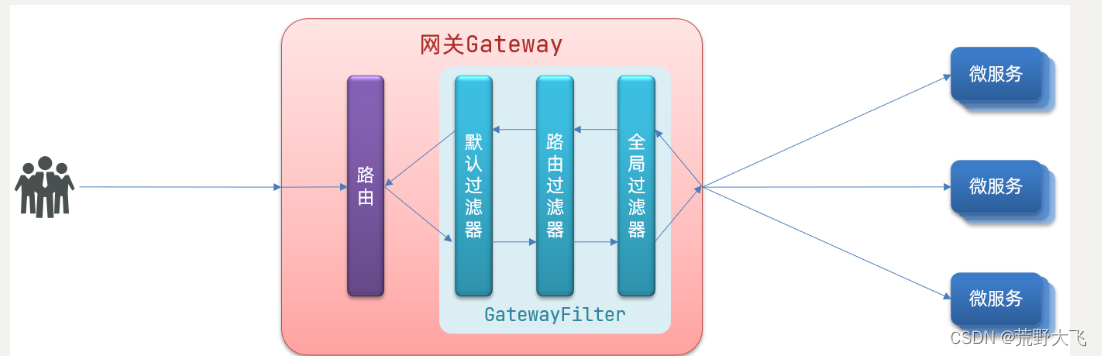
排序的规则是什么呢?
- 每一个过滤器都必须指定一个int类型的order值,order值越小,优先级越高,执行顺序越靠前。
- GlobalFilter通过实现Ordered接口,或者添加@Order注解来指定order值,由我们自己指定
- 路由过滤器和defaultFilter的order由Spring指定,默认是按照声明顺序从1递增。
- 当过滤器的order值一样时,会按照 defaultFilter > 路由过滤器 > GlobalFilter的顺序执行。
6.Docker
过
7.RabbitMQ
1.RabbitMQ介绍
1.同步调用
同步调用的优点:
- 时效性较强,可以立即得到结果
同步调用的问题:
- 耦合度高
- 性能和吞吐能力下降
- 有额外的资源消耗
- 有级联失败问题
2.异步调用
好处:
-
吞吐量提升:无需等待订阅者处理完成,响应更快速
-
故障隔离:服务没有直接调用,不存在级联失败问题
-
调用间没有阻塞,不会造成无效的资源占用
-
耦合度极低,每个服务都可以灵活插拔,可替换
-
流量削峰:不管发布事件的流量波动多大,都由Broker接收,订阅者可以按照自己的速度去处理事件
缺点:
- 架构复杂了,业务没有明显的流程线,不好管理
- 需要依赖于Broker的可靠、安全、性能
3.几种常见MQ的对比:
| RabbitMQ | ActiveMQ | RocketMQ | Kafka | |
|---|---|---|---|---|
| 公司/社区 | Rabbit | Apache | 阿里 | Apache |
| 开发语言 | Erlang | Java | Java | Scala&Java |
| 协议支持 | AMQP,XMPP,SMTP,STOMP | OpenWire,STOMP,REST,XMPP,AMQP | 自定义协议 | 自定义协议 |
| 可用性 | 高 | 一般 | 高 | 高 |
| 单机吞吐量 | 一般 | 差 | 高 | 非常高 |
| 消息延迟 | 微秒级 | 毫秒级 | 毫秒级 | 毫秒以内 |
| 消息可靠性 | 高 | 一般 | 高 | 一般 |
追求可用性:Kafka、 RocketMQ 、RabbitMQ
追求可靠性:RabbitMQ、RocketMQ
追求吞吐能力:RocketMQ、Kafka
追求消息低延迟:RabbitMQ、Kafka
4.RabbitMQ中的一些角色:
- publisher:生产者
- consumer:消费者
- exchange个:交换机,负责消息路由
- queue:队列,存储消息
- virtualHost:虚拟主机,隔离不同租户的exchange、queue、消息的隔离
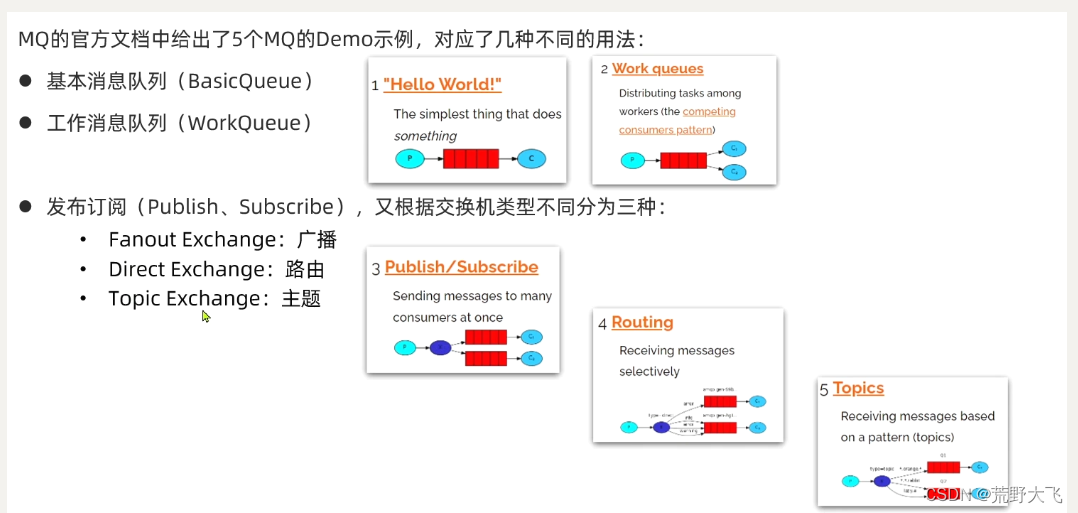
2.RabbitMQ 5个消息模型
RabbitMQ官方提供了5个不同的Demo示例,对应了不同的消息模型:
a.SpringAMQP
SpringAMQP是基于RabbitMQ封装的一套模板,并且还利用SpringBoot对其实现了自动装配,使用起来非常方便。
SpringAMQP提供了三个功能:
- 自动声明队列、交换机及其绑定关系
- 基于注解的监听器模式,异步接收消息
- 封装了RabbitTemplate工具,用于发送消息
1.Basic Queue 简单队列模型
2.WorkQueue
Work queues,也被称为(Task queues),任务模型。简单来说就是让多个消费者绑定到一个队列,共同消费队列中的消息。
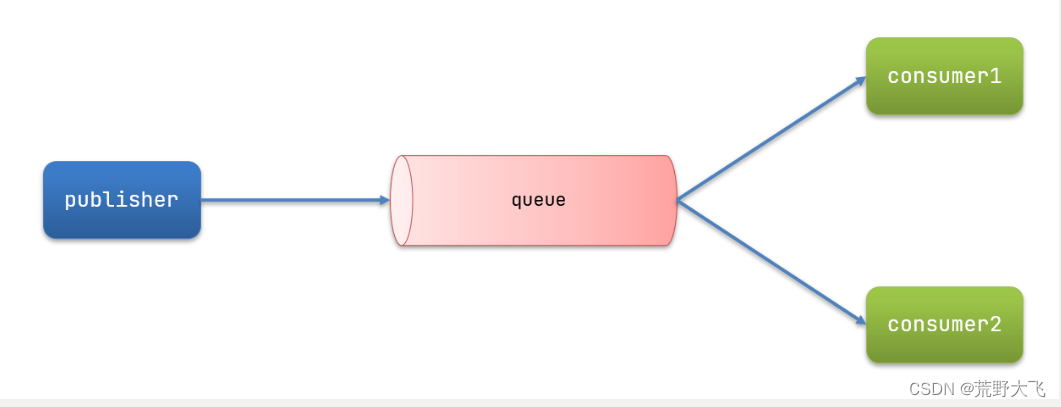
当消息处理比较耗时的时候,可能生产消息的速度会远远大于消息的消费速度。长此以往,消息就会堆积越来越多,无法及时处理。
此时就可以使用work 模型,多个消费者共同处理消息处理,速度就能大大提高了。
Work模型的使用:
- 多个消费者绑定到一个队列,同一条消息只会被一个消费者处理
- 通过设置prefetch消息预取来控制消费者预取的消息数量
3.4.5发布/订阅的三个模型
发布订阅的模型如图:
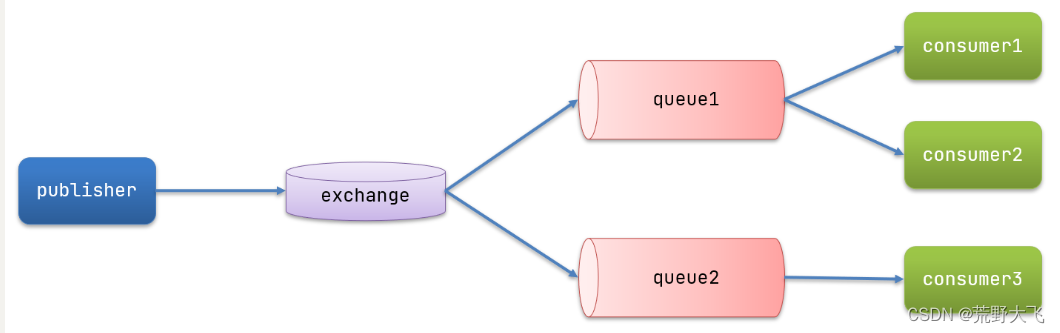
可以看到,在订阅模型中,多了一个exchange角色,而且过程略有变化:
- Publisher:生产者,也就是要发送消息的程序,但是不再发送到队列中,而是发给X(交换机)
- Exchange:交换机,图中的X。一方面,接收生产者发送的消息。另一方面,知道如何处理消息,例如递交给某个特别队列、递交给所有队列、或是将消息丢弃。到底如何操作,取决于Exchange的类型。Exchange有以下3种类型:
- Fanout:广播,将消息交给所有绑定到交换机的队列
- Direct:定向,把消息交给符合指定routing key 的队列
- Topic:通配符,把消息交给符合routing pattern(路由模式) 的队列
- Consumer:消费者,与以前一样,订阅队列,没有变化
- Queue:消息队列也与以前一样,接收消息、缓存消息。
Exchange(交换机)只负责转发消息,不具备存储消息的能力,因此如果没有任何队列与Exchange绑定,或者没有符合路由规则的队列,那么消息会丢失!
3.Fanout:广播
Fanout,英文翻译是扇出,我觉得在MQ中叫广播更合适。
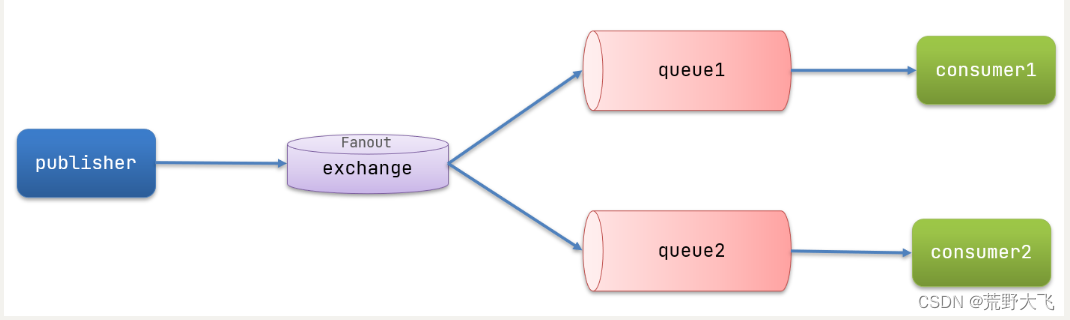
在广播模式下,消息发送流程是这样的:
- 1) 可以有多个队列
- 2) 每个队列都要绑定到Exchange(交换机)
- 3) 生产者发送的消息,只能发送到交换机,交换机来决定要发给哪个队列,生产者无法决定
- 4) 交换机把消息发送给绑定过的所有队列
- 5) 订阅队列的消费者都能拿到消息
交换机的作用是什么?
- 接收publisher发送的消息
- 将消息按照规则路由到与之绑定的队列
- 不能缓存消息,路由失败,消息丢失
- FanoutExchange的会将消息路由到每个绑定的队列
声明队列、交换机、绑定关系的Bean是什么?
- Queue
- FanoutExchange
- Binding
4.Direct:路由(定向)
在Fanout模式中,一条消息,会被所有订阅的队列都消费。但是,在某些场景下,我们希望不同的消息被不同的队列消费。这时就要用到Direct类型的Exchange。
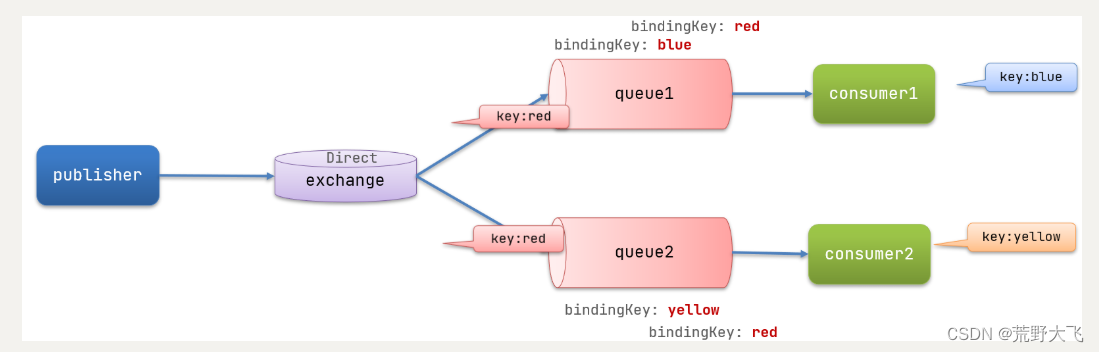
在Direct模型下:
- 队列与交换机的绑定,不能是任意绑定了,而是要指定一个
RoutingKey(路由key) - 消息的发送方在 向 Exchange发送消息时,也必须指定消息的
RoutingKey。 - Exchange不再把消息交给每一个绑定的队列,而是根据消息的
Routing Key进行判断,只有队列的Routingkey与消息的Routing key完全一致,才会接收到消息
描述下Direct交换机与Fanout交换机的差异?
- Fanout交换机将消息路由给每一个与之绑定的队列
- Direct交换机根据RoutingKey判断路由给哪个队列
- 如果多个队列具有相同的RoutingKey,则与Fanout功能类似
基于@RabbitListener注解声明队列和交换机有哪些常见注解?
- @Queue
- @Exchange
5.Topic:话题(通配符)
Topic类型的Exchange与Direct相比,都是可以根据RoutingKey把消息路由到不同的队列。只不过Topic类型Exchange可以让队列在绑定Routing key 的时候使用通配符!
Routingkey 一般都是有一个或多个单词组成,多个单词之间以”.”分割,例如: item.insert
通配符规则:
#:匹配一个或多个词
*:匹配不多不少恰好1个词
举例:
item.#:能够匹配item.spu.insert 或者 item.spu
item.*:只能匹配item.spu
图示:
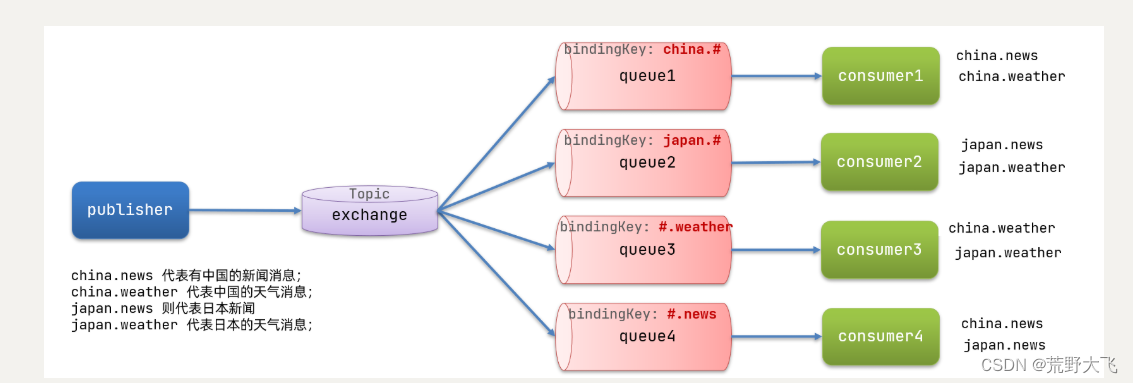
解释:
- Queue1:绑定的是
china.#,因此凡是以china.开头的routing key都会被匹配到。包括china.news和china.weather - Queue2:绑定的是
#.news,因此凡是以.news结尾的routing key都会被匹配。包括china.news和japan.news
描述下Direct交换机与Topic交换机的差异?
- Topic交换机接收的消息RoutingKey必须是多个单词,以
**.**分割 - Topic交换机与队列绑定时的bindingKey可以指定通配符
#:代表0个或多个词*:代表1个词
这篇关于SpringCloudAlibaba组件总结笔记(如Nacos、SpringCloudGateway、OpenFeign,Ribbon,RabbitMQ)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








