本文主要是介绍芒果tv数据采集与可视化实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘 要
一个爬虫从网上爬取数据的大致过程可以概括为:向特定的网站服务器发出请求,服务器返回请求的网页数据,爬虫程序收到服务器返回的网页数据并加以解析提取,最后把提取出的数据进行处理和存储。因此,一个爬虫程序可以主要分为三大部分:向服务器请求并获取网页数据、解析网页数据、数据处理和存储。课程设计中详细的介绍了网络爬虫的实现机制与理论基础。通过利用 Python 网络爬虫技术,抓取芒果tv的电影信息包括电影名称、播放量评分等数据。本课程设计使用 requests 库和 json库实现抓取了热门电影数据和电影评论,提取截止1400余条有效信息,进行了数据处理与数据分析,并使用matloplit库 、Wordcloud库实现数据可视化展示。
关键词:网络爬虫;电影评价分析;Python;requests;
Matloplit;Wordcloud;json
第1章 绪论
随着互联网时代的快速发展,人们对网络信息和数据的检索和提取的要求也逐渐提高。由于部分信息数据搜索过于复杂,而且访问Web检索工具又一般都是些传统的搜索引擎,它们则具有一定的局限性,往往不能满足用户的检索目的和需求。因而引入网络爬虫技术则具有重大意义,考虑到Python语言目前在市场上十分火热,而且在编写爬虫领域方面具有一定的优势,为此,本文将对基于Python的网络爬虫技术展开初步的研究。
1.1 本课题研究背景
现在的社会已经进入了信息时代,尤其是网络视频成为一种很普遍的休闲方式,大数据的获取和分析对于促进经济发展有着重要的意义。掌握观众的爱好和习惯,有助于电影发行发及时的调整有至关重要的意义。
网络电影在我们的日常休闲生活占据很大时间,为了更好的掌握观众对于电影口碑、电影热度的关注程度,我们选取芒果tv电影作为我们研究的目标,通过网络爬虫技术获取网站的数据,利用数据库技术存储数据,最后用可视化分析的形式给出我们最终的研究结果。
1.2 网络爬虫发展概述
在大数据时代,信息的采集是一项重要的工作,而互联网中的数据是海量的,如果单纯靠人力进行信息采集,不仅低效繁琐,搜集的成本也会提高。如何自动高效地获取互联网中我们感兴趣的信息并为我们所用是一个重要的问题,而爬虫技术就是为了解决这些问题而生的[1]。网络爬虫(Web crawler)也叫做网络机器人,可以代替人们自动地在互联网中进行数据信息的采集与整理[2]。它是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,可以自动采集所有其能够访问到的页面内容,以获取相关数据。从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分。爬虫从一个或若干初始网页的 URL 开始,获得初始网页上的 URL,在抓取网页的过程中,不断从当前页面上抽取新的 URL 放入队列,直到满足系统的一定停止条件。
1.2.1 网络爬虫技术的国内外发展现状
1.国内网络爬虫技术的发展现状
1)网络爬虫技术概述
网络爬虫技术作为搜索引擎的重要组成部分,可以自动地对相关页面和内容进行爬虫和保存。网络爬虫又被称为网络蜘蛛,所以可以看出爬虫就是一只蜘蛛,而互联网其实就是一张巨大的蜘蛛网,爬虫的目的就是将蜘蛛网上的猎物全部抓取起来[3]。 2)国内外研究现状
随着互联网的快速发展,全球互联网网站和网页的数量也在迅速增长,互联网的信息量也呈指数级的增长。互联网是一个巨大的高度开放,缺乏管理的信息空间。虽然信息量十分巨大,但是对于用户来说,真正有价值的信息就变得非常有限。如果用户想要从互联网上获取有用的信息,他们需要搜素引擎的帮助,如信息检索系统。搜索引擎是根据一定的策略和特定的计算机程序从互联网进行搜索的软件系统,在处理和处理信息后为用户提供检索服务。目前市场上比较流行的搜索引擎有百度、Google 等。搜索引擎的发展伴随着信息检索技术的发展[4]。1972 年,APPNET 实验网络的成功标志着互联网的诞生。1993 年浏览器的发展更是促进了搜索引擎的快速发展。1994 年由美籍华人杨致远和 DavidFilo 共同创建了世界上第一个网络检索工具 Web Crawler,也就是大家所熟悉的 Yahoo[5]。
1.3 本课题研究意义
通过爬虫技术收集了芒果tv播放页热门电影名称,链接,主演,评分,评价人家与评价内容等电影信息,将这些数据进行处理,获得了评价词云图、热门电影前10播放量等数据可视化分析图表。希望通过这些数据让观众们了解电影真实评价和口碑。
1.4 课题的研究主要内容
本课程设计针对爬虫技术中 requests 模块的应用进行了深入的研究,全文共分 3 章,主要内容分别是:
绪论。主要介绍了本课程设计的主要内容与主要目的;
第一部分:讲了一些常见的爬虫分类,并且简单介绍了这些爬虫背景与其适用场景;第二部分:系统框架,各框架的功能介绍,以及存储数据的属性;第三部分:代码的储存以及数据的展示。
课题的创新点在于整合芒果tv电影评论1000多条评论的信息数据与结构,整合、筛
选、分组进入数据库,利用 SQL 语句进行关键词的查找,即可获取相关信息,并制作词云图进行真实口碑分析。
第2章 系统设计
2.1 系统构架
项目设计主要分为几个步骤:根据需求,确定我们需要爬取的网站和数据类型;通过Python爬虫技术对网页进行解析;将数据持久化,存储到数据库中,以便于随时提取、查询、添加数据;通过获取的数据进行可视化分析,得到我们的结论。整个过程如图所示:

图2.1 系统架构图
2.2 系统构架介绍
芒果tv热门电影信息采集器:包含对电影名称,链接,评分,播放数据与评价内容。
数据爬取模块:主要是用
Request获取响应的网页信息,在利用json做相应的信息抽取,获取所需要的 HTML 标签内的文本新息。
数据存储模块:利用 MySQL 数据库存储爬取到的评价内容。
数据可视化分析模块:对读取出的数据进行可视化分析,展示评价词云图、热门电影前10播放量评分排名等图表等。
2.3 技术模块
表 2.1 项目所使用模块
| 库名 | 项目中作用 |
|---|---|
| Requests | 网页数据采集 |
| json | 转化提取网页数据 |
| PyMySQL | 储存清洗后的数据信息 |
| matloplit | 可视化数据 |
2.3.1requests 模块
HTTP库中的Requests模块,作用是发送网络请求,获得响应数据。
Requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库。它比urllib更加方便,可以节约大量的工作,完全满足HTTP测试需求的。总之,Requests是一个Python代码编写的HTTP请求库,方便在代码中模拟浏览器发送http请求。
在Python中,一般爬虫主要是通过一个python的第三方库requests来实现这个过程的,requests库提供了两种发起请求的方法,分别为get()何post(),这也是大部分网站都会实现的两个接口。一般地,get()方法直接通过url参数(有时候还需要请求头参数)便可以发起有效请求;post()方法除此之外还需要一些额外的表单参数,才可以发起有效请求。在一个爬虫中具体用哪种方法取决于要爬取的网站实现了哪个接口,这个可以通过在浏览器(推荐chrome浏览器)的开发者工具(F12)查看。如下图,可以知道要获取芒果tv电影数据,要用get方法,在看到数据结构,字典类型的数据组合而成,可以利用json将网页字符串数据转化成字典结构提取。

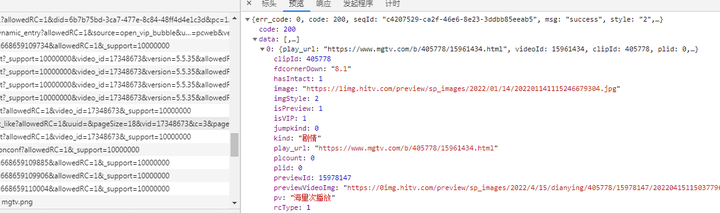
添加图片注释,不超过 140 字(可选)
2.3.2json 模块
json模块的主要功能是将序列化数据从文件里读取出来或者存入文件。其中dump()是将数据存入文件中,load()是用于读取文件。而dumps()和loads()是对python对象进行操作。dumps()是将python对象编码成json字符串。loads()是将json字符串解码成python对象。json.dumps() 是把python对象转换成json对象的一个过程,生成的是字符串。json.dump() 是把python对象转换成json对象生成一个fp的文件流,和文件相关。json.loads()和json.load()的区别同上类似,加上s的方法是用来处理字符串类型的,而不加s是用来处理文件类型的。所以本文使用的是json.loads处理字符串数据
2.3.3PyMySQL 模块
pymysql库是一个利用Python终端操作MySQL数据库的模块。通过pymysql,我们可以利用python语言实现对数据库及表的提取、读写、删除数据等基本操作。
2.4 数据库设计
表 2.2 mysql数据库表
| 字段名 | 类型 | 长度 | 小数点 | 是否为空 | 注释 |
|---|---|---|---|---|---|
| 电影名 | char | 80 | 0 | 否 | 电影名 |
| 电影时长 | char | 200 | 0 | 否 | 时长 |
| 电影播放数据 | int | 20 | 0 | 否 | 电影播放数据 |
| 电影评分 | char | 20 | 0 | 否 | 电影评分 |
| 电影评论 | varchar | 500 | 0 | 否 | 电影评论 |
表 2 中 电影名 为电影片名。电影时长为电影名对应的播放时长。电影播放数据 为电影名总观看人数,电影评分 为电影名对应的评分。电影评论为人事大事的电影评论。
2.5 数据可视化分析
将存入 MySQL 的数据先利用 SQL 语句筛选处理,进行初步的数据分析,进行数据可视化分析,实现数据展示,后导出为 jpg或者png文件。
2.6 本章小结
本章主要介绍了本课程设计的系统框架,然后对各框架所涉及到的功能和所使用的技术进行了简单介绍,最后以表格的形式展示出需要存储数据的属性并介绍各个字段所存储数据的获取目的。
第3章 系统实现
本章以人事大事电影为例,对芒果tv播放页中热门电影(长津湖、我的姐姐。。。)和人事大事评论进行了数据的爬取,获得了超过1400余条的数据,包括电影名、电影时长、电影播放数据、电影评分、电影评论等信息,并将数据存储到MySQL数据库中。在数据分析阶段,我们对获取到的数据从多个角度进行了可视化分析,为我们的结论打下基础。
3.1 网页分析
3.1.1 URL地址构建
打开芒果tv人生大事电影发现,评论数据还有热门电影数据在网页上是不完全显示的,我们可以推断出这些信息应该就是在xhr里面才能找到。通过xhr寻找到播放数据在如下图链接中,并且发现只需要更换链接的影片ID就可以获取不同电影的播放数据
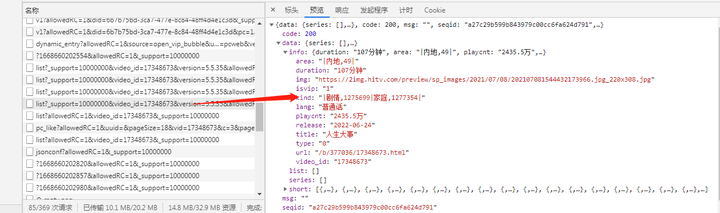
添加图片注释,不超过 140 字(可选)
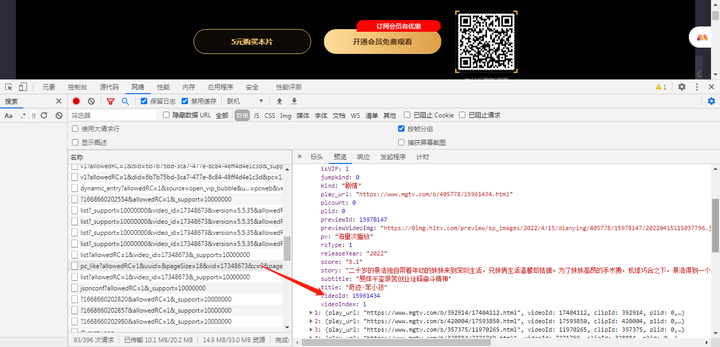
不同电影的ID和电影名称评分等也可以通过xhr寻找到,如下图
最后就是电影评论,通过js找到,如下图:
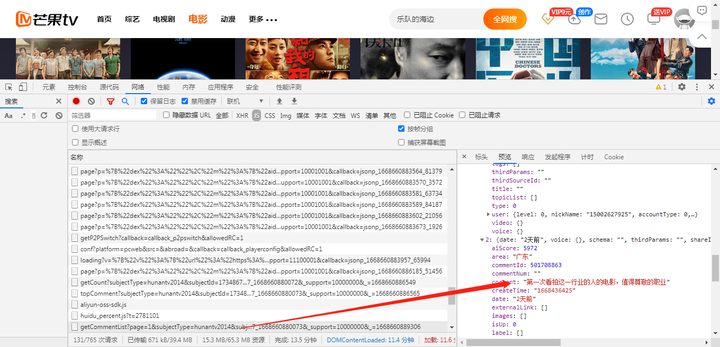
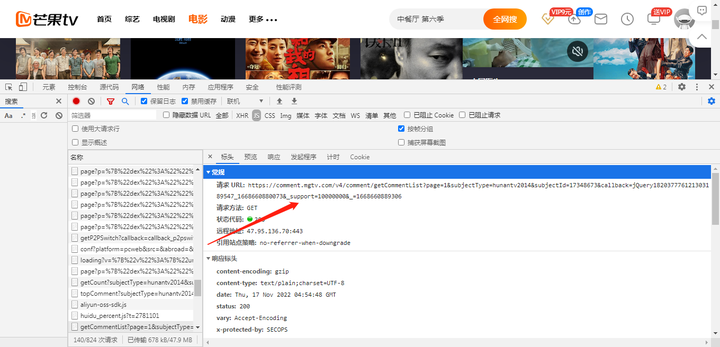
研究电影评论标头发现,其中page就是页数,我们可以通过修改页数获得全部电影评论,可以通过range函数提取所有电影评论,另外subjectID就是电影名ID,如果想获取不同的电影评论,只需要修改这ID即可,经过网页分析之后,我们就能构造好要爬取的链接,通过json.load方法获取我们想要爬取的数据。
3.2数据库存储
MySQL是一种关系型数据库,关系型数据库最重要的概念就是表,表具有固定的列数和任意的行数,在数学上称为“关系”二维表是同类实体的各种属性的集合,每个实体对应于表中的一行,在关系中称为元组,相当于通常的一条记录,表中的列属性,称为Field,相当于通常记录中的一个数据项,也叫做列、字段。
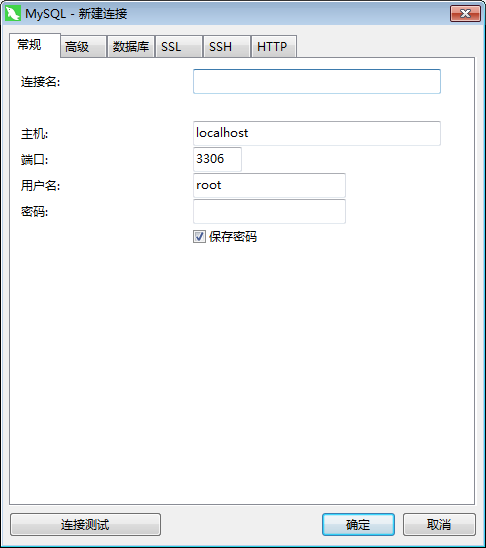
首先,打开数据库连接之前,一定保证打开MySQL服务,否则就会出现连接失败的情况。Navicat for MySQL是一款强大的MySQL数据库管理和开发工具,它为专业开发者提供了一套强大的足够尖端的工具,对于数据库的可视化是很方便简洁的。然后,我们要设置好数据库连接的相关配置,以便于我们可以在Python中成功连接数据库,包括数地址、端口号、用户名、密码,具体的配置信息如图所示
另外存储为SQL时也把评论存储为txt格式,方便后期去做评论分析的词云图,而不用在经过数据库转换,节省不必要的麻烦。
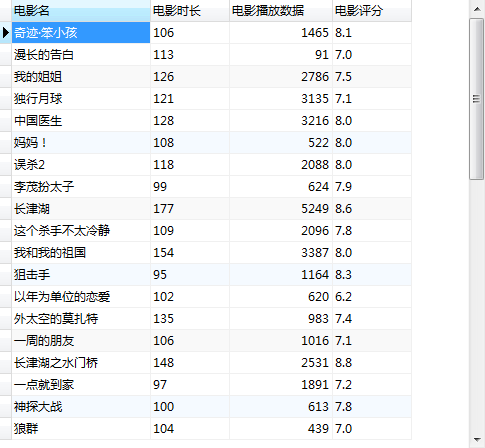
在完成上述工作及配置之后,我们就可以正式的编写代码来爬取数据了。将我们的爬虫伪装成浏览器去获取网页,然后对网页解析,得到我们需要的数据,最后将数据存储到MySQL数据库中。为了保证报告的美观和质量,在此部分将不再展示代码,全部的源代码见附录。最终得到的数据如图所示:

3.3 数据展示
在得到数据之后,我们对数据进行了全方面多维度的分析,通过matloplit库、wordcloud库,将MySQL 文件导入,实现 数据可视化。我们主要从三个大角度对数据进行可视化分析:时长分析、播放数据分析、评分分析、词云图。
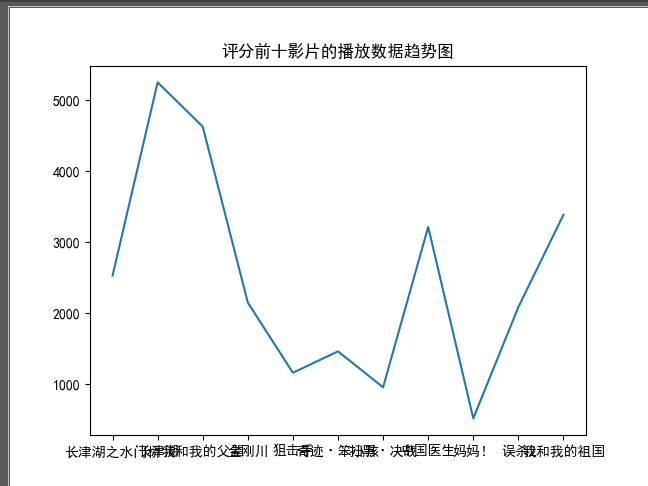
该图为排名前10电影时长分析。
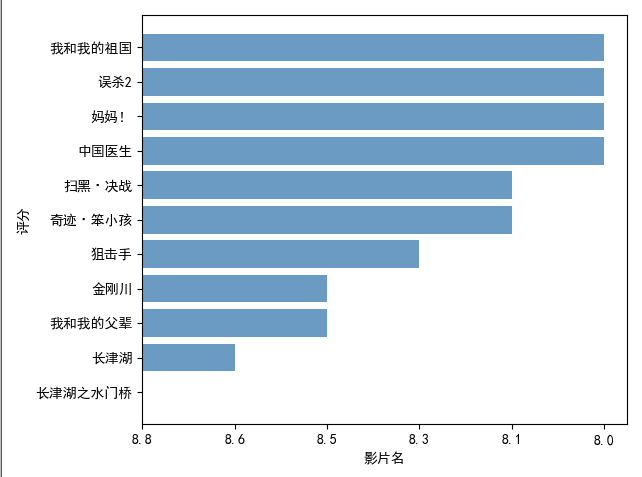
该图 电影评分前十排名图
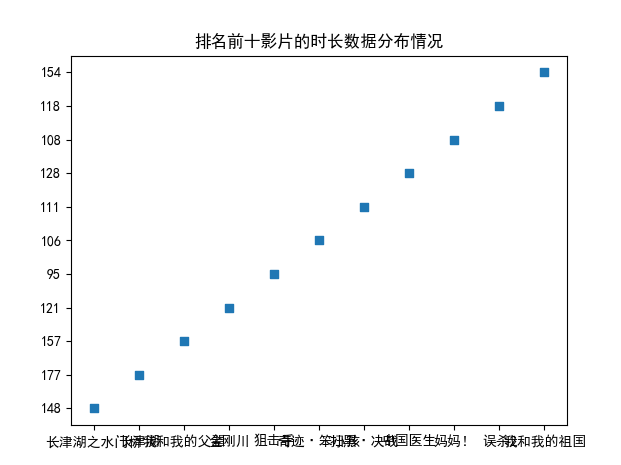
该图为电影排名前十的时长数据分布

电影人生大事的评论词云图
该图为人生大事电影的评论词云图,展示了所获取的 1400条 评论的词云频率,字体越大和颜色越深的代表该词的出现的频率越高,能反映观众的主要评价。
第4章 全文总结
通过Python爬虫以及数据可视化分析的学习,我们在这过程中查阅了大量的资料,经过多次实验分析,最终形成我们的项目报告。主要实现了对芒果tv中热门电影数据的爬取以及数据分析工作,掌握了Python常用库以及数据库的使用方法。总体而言,这门课让我们学到了很多的东西,网络在我们身边无处不在,学会编程对于我们日常的学习和工作都有很大的帮助。
由于时间有限,我们的项目还有一定的不足,后续有机会将会继续改进。
参考文献
参考文献
[1] 成文莹,李秀敏 . 基于Python的电影数据爬取与数据可视化分析研究[J].电脑知识与技术,2019(15):8-10.
[2] 方芳. 基于Scrapy框架京东网站笔记本电脑评论数据爬取和分析[J].电脑知识与技术,2020(6):7-9.
[3] 严家馨.基于Python对资讯信息的网络爬虫设计[J].科学技术创新,2020(05):57-58.
[4] 张艳.基于Python的网络数据爬虫程序设计[J]. 电脑编程技巧与维护 2020,(04),26-27
作者简介:周萍(1977年12月—)、女、汉族、籍贯四川省德阳市、现供职单位解放军78102部队高级工程师、硕士研究生、研究方向指挥自动化;
李歌(1985年1月—)、男、汉族、籍贯河北省霸州市、现供职单位解放军78102部队工程师、本科、研究方向计算机应用。
这篇关于芒果tv数据采集与可视化实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






