这里先要补充一下,Python3自带两个用于和HTTP web 服务交互的标准库(内置模块):
- http.client 是HTTP协议的底层库
- urllib.request 建立在http.client之上一个抽象层,它为访问HTTP和FTP服务器提供一个标准的API,可以自动跟随HTTP重定向并处理一些常见形式的HTTP 认证
httplib2
1.简介
httplib2是一个第三方的开源库。它比python3中的http.client更完整的实现了HTTP协议,同时比urllib.request提供了更好的抽象。
前面说的httplib,功能已经够全够实用了对吧,为什么还要用httplib2或者说为什么还要有httplib2?这个问题,我想你会立即联想到urllib和urllib2模块的关系。
答案也和urllib和urllib2一样,功能有补充,有提升。
httplib2是第三方模块,所以需要先安装再使用
有哪些很显著的特点呢?
1).支持HTTP 1.1的 Keep-Alive特性,能够在同一个socket连接里使用并发的httprequest
2).支持的认证方式
- Basic(基础)
- Digest(摘要)
- WSSE(WS-Security,Web服务安全)
- HMAC Digest(Hash-based message authentication code,利用哈希算法,以一个密钥和一个消息为输入,生成一个消息摘要作为输出)
- Google Account Authentication(谷歌式账户认证)
当然一般Basic和Digest就够用了。
如果觉得保密性不够,那最好用HTTPS,这个防火墙也无法根据内容过滤
3).支持Cache(缓存)
是的,缓存是很多机制都必有的功能,如果http的库没有包含http本身支持的缓存就太可惜了。
如下就能创建一个带有缓存的HTTP对象test,缓存则存储在当前环境的“.cache"目录下:
注意httplib2.Http,Http,首字母大写
import httplib2
test = httplib2.Http(".cache") 4).支持所有HTTP请求方法:即在GET和POST基础上,还支持DELETE和CONNECT
5).自动通过”GET“方法,重定向状态码为3XX的返回值
6).支持deflate和gzip的压缩格式
很多网页其实都用的gzip的压缩格式压缩网页源代码,减少浏览器加载时间,这样可以更加快速的打开网页,相对来说,deflate倒是很少见
7).支持最后修改时间检查
8).支持ETag(实体标签)
9).支持永久重定向。不仅会告诉你永久重定向,还会在本地记录,并且在发送请求前自动重写为重定向后的URL
2.方法/属性

其实你有没有发现,httplib2和httplib模块等的都会带有其他标准库,比如上面截图里的urllib,time,copy等,还带有模块httplib,所以它的功能才那么多,可以简单的测试一下:

发现urllib的路径正好就是默认的urllib标准库,还有sys,time等的显示的都属于built-in,这个单词不用多说,我想你应该知道这就是内置模块的意思。
所以像这种第三方库,因为代码已经设置好了可以直接用标准库的方法,所以功能才那么强大,完全可以替代标准库
3.常用方法/属性解析
httplib2模块和urllib3的地位一样尴尬,虽然它也是第三方库,但是用的其实也不多,网上的资料也少,而其方法和属性,上面的截取你应该看到了,基本链接的python自己的标准库。
httplib2.Http()会创建一个类对象,同前面的一样,自己去联想了。
httplib2.Http()
1.httplib2.Http()的常用实例:
1)首先httplib2.Http()最常用例:
# -*- coding:gb2312 -*-
import httplib2
html=httplib2.Http() print html.request('http://www.baidu.com')
结果是报文头部信息+百度首页源代码组合成的元组,所以你也可以把上面的第四行改为【headers,content = html.request('http://www.baidu.com/') 】分别把头部和百度首页源代码取出来。
2):带cache的访问:
# -*- coding:gb2312 -*-
import httplib2
html=httplib2.Http('.cache') #默认在当前主py目录下创建名为.cache的文件夹 print html.request('http://www.baidu.com')
结果,我电脑里当前目录下多了个.cache目录
打开目录:
发现这就是刚才访问百度网页得到的缓存,用记事本打开:
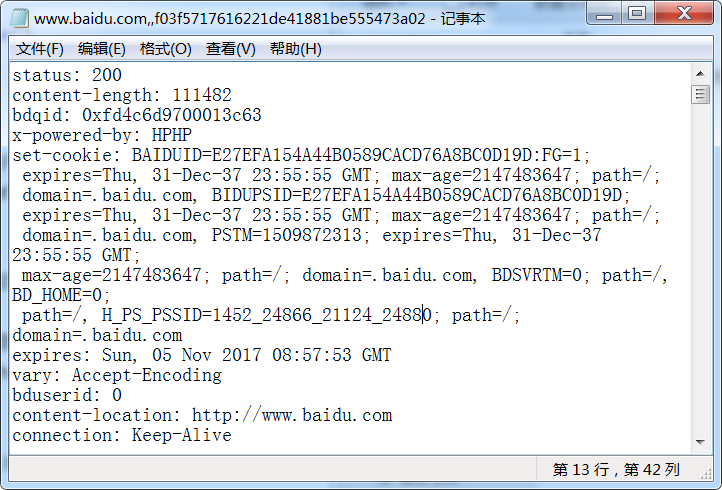
发现里面的内容就同前面的一样,是http头部信息和百度首页的源代码。
2.httplib2.Http()的常用方法
1).Http.add_credentials:
- 增加授权用户名和密码,httplib2自动会通过解析repond:Http.add_credentials(name, password[, domain=None])
- 增加ssl的证书信息
2).Http.request(url[, method="GET", body=None, headers=None, redirections=DEFAULT_MAX_REDIRECTS, connection_type=None])
- method:默认是"GET"
- redirections:指定其他header和最大自动重定向次数(默认是5),并不能无限重定向
- connection_type:连接类型
- (其他参数相信你通过前面的学习都很清楚了,不用再说了)
例1:测试httplib2是否能支持https
# -*- coding:gb2312 -*- import httplib2 html=httplib2.Http('.cache') html.add_credentials('name','password') reponse,cont=html.request('https://www.baidu.com','GET',headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0','content-type':'text/plain','Accept': 'text/plain'}) print reponse print '---------------------------------------------------' print cont
结果是,程序还是正常的的运行并爬取到百度首页的代码以及报文头部信息。
例2:域名重定向
注意:这里说个题外话,也是必须要说的。下面这个网站是我好不容易找到的,是一个私人网站,没有百度企业网站服务器那么经搞,大家尽量不要去测试,看我给的测试和结果就好了,毕竟是一个私人网站,如果你把别人网站服务器搞崩了就不太好了(我测试的前后这网站可是可以正常登录的,并没有给人搞崩),你知道httplib2模块可以实现域名重定向就可以了。还有我们现在写的爬虫都算一般的,别以为你用代理ip或者隐藏头部信息就真的匿名了,真要找你是找得到的。
# -*- coding:gb2312 -*- import httplib2 html=httplib2.Http('.cache') html.add_credentials('name','password') reponse,cont=html.request('http://www.freedom1024.com','GET',headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0','content-type':'text/plain','Accept': 'text/plain'}) print reponse print '---------------------------------------------------' print cont
结果:
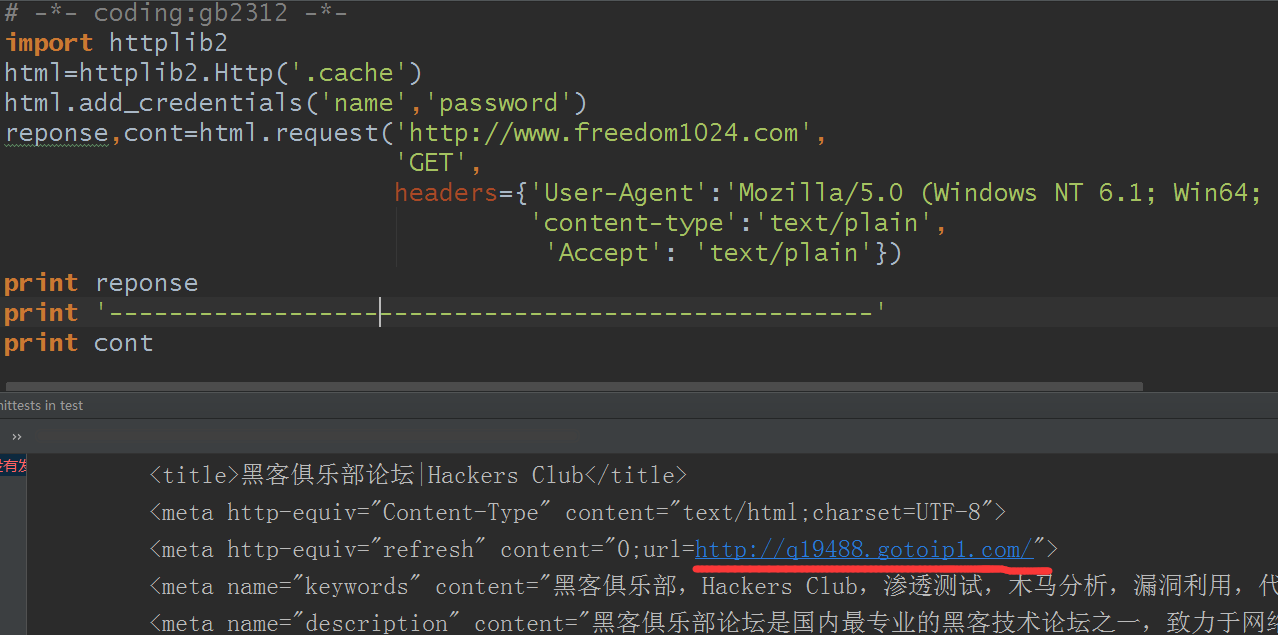
用浏览器打开测试看看:
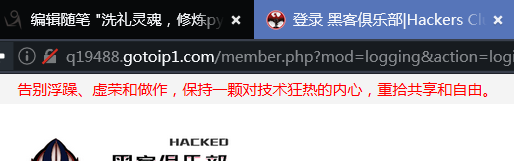
确实是这个链接,完美(/斜眼笑)
更多的相关功能就你自己去发现吧,我看到还有人用httplib2登录网页版的QQ等的。自己下去研究了。
免责声明
本博文只是为了分享技术和共同学习为目的,并不出于商业目的和用途,也不希望用于商业用途,特此声明。如果内容中测试的贵站的站长有异议,请联系我立即删除






