本文主要是介绍Python读取并执行本地文件中的链接,打开搜狐浏览器,循环执行,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
关注公众号《行走的java》,最下方有二维码!一定有你想要的!回复004 有demo代码。
公司为了不断地给一个浏览器地址刷浏览量,,于是写了个小脚本,,循环读取本地文件中的链接,然后打开浏览器去执行它。
1:用Pycharm 创建项目命名Test,然后在空的工程中创建我们的py文件,,,不会创建工程移步百度一下
2:创建txt文件,因为需要读取本地文件链接,所以创建文件里面写上我们需要读取的链接地址 例如:www.baidu.com
如下图
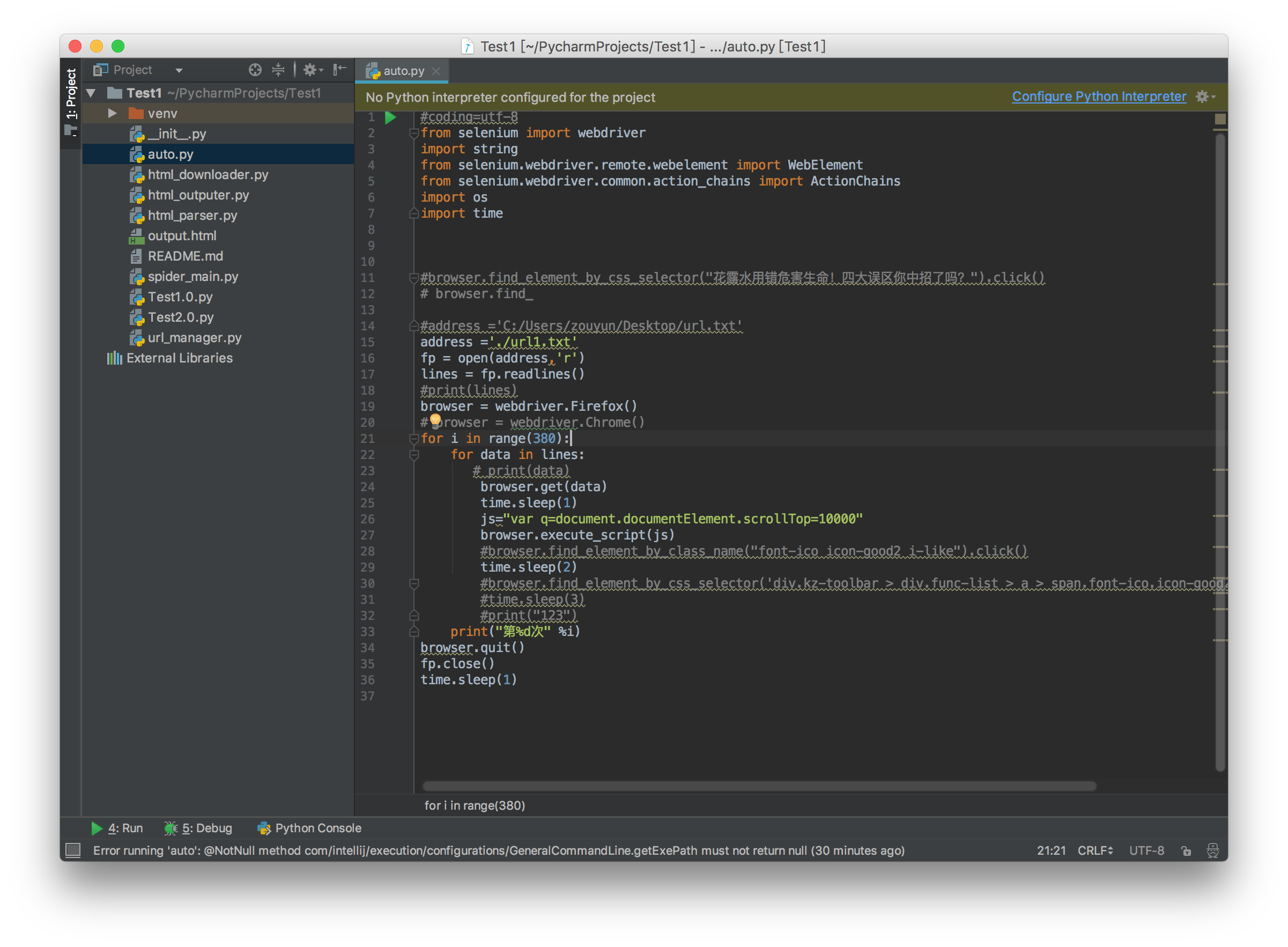
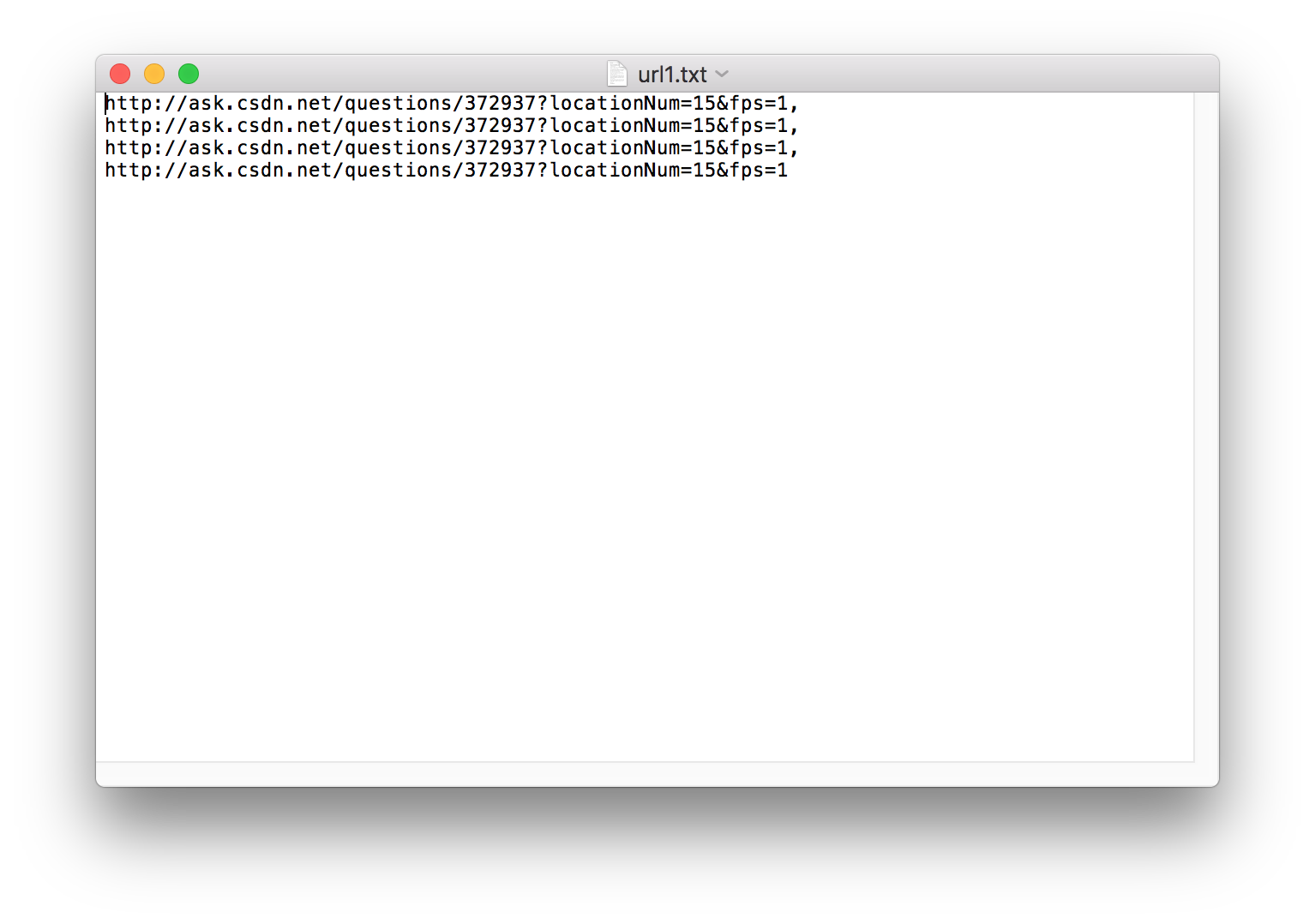
其中只需要看auto.py文件和url1.txt即可,
其中我们可能会出现下面的报错
from selenium import webdriver
这是因为我们没有添加selenium
下图就是详细步骤
点击第二张图中间左下角的+号,然后搜索selenium,点击左下角的install即可
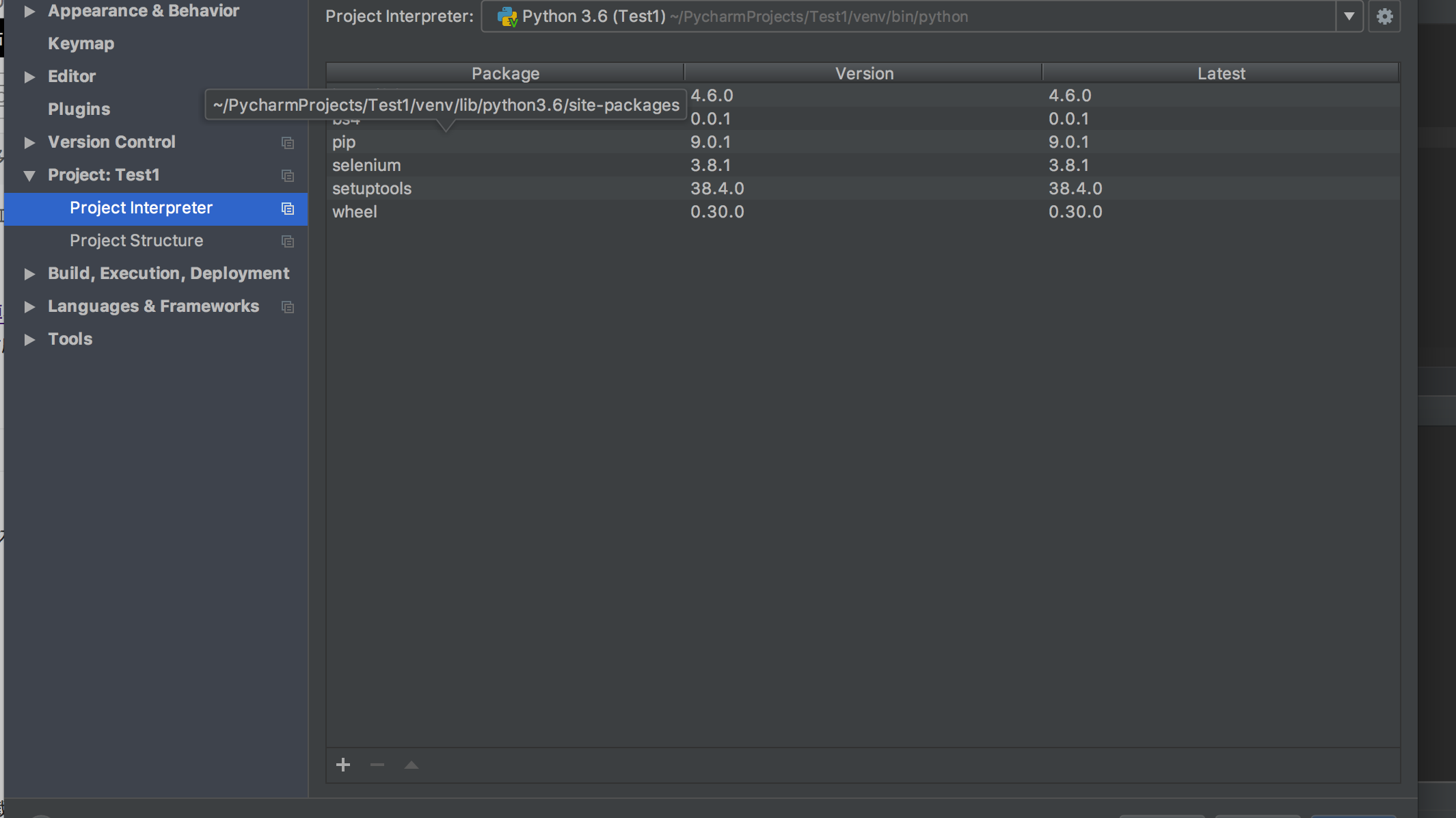
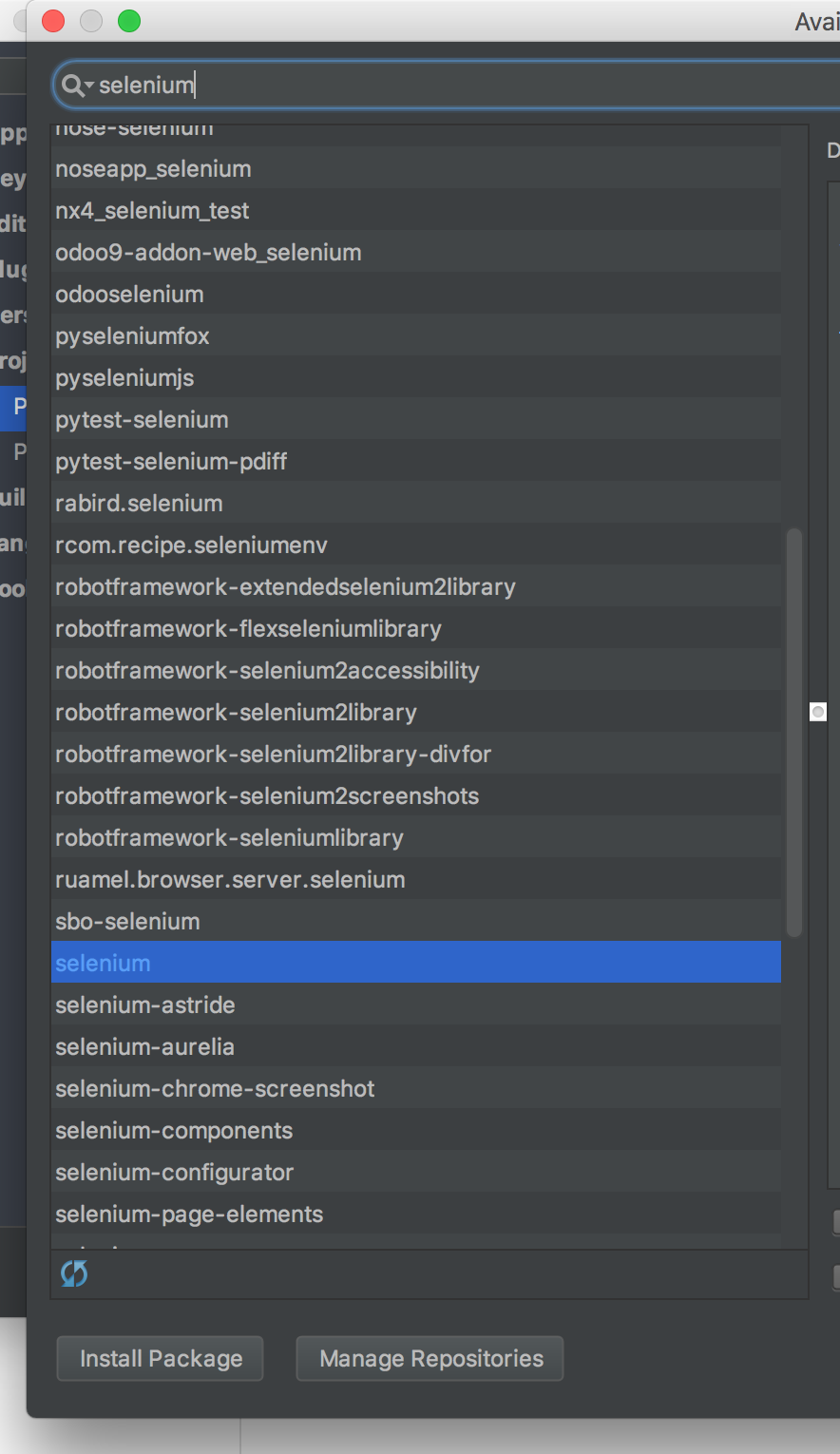
这样再回头看下我们的错误就好了,这是一个含简单的读取文件,主要难点就是如何配置selenium和浏览器的运行文件,,搜狐 和谷歌要分别下载,然后放到python的bin路径下。链接移步http://blog.csdn.net/hw140701/article/details/59109649。

这篇关于Python读取并执行本地文件中的链接,打开搜狐浏览器,循环执行的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







