本文主要是介绍DARPA TC-e3/e5数据集bin转json,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
关于这个数据集的一些基本信息就不赘述了,参考我之前的博客。DARPA TC-engagement5数据集官方工具可视化
两个方法:修改ELK可视化工具或直接使用自带的工具。前者相对灵活,因为losgstash可以通过配置过滤器来修改字段;可以通过output选项设置文件名参数直接对日志进行分类,比如按事件类型写到相应的文件。但是目前有点小问题,每次json文件超过4.3G就会自动断掉,猜测应该是linux的文件大小有限制。这一点也可以在另一个自带的consumer工具中体现出来。后者更稳定,但是如果需要进一步研究其参数。
1. 修改可视化工具
官方给的工具是将解析的数据存到elasticsearch的,但是数据集的解压增长率非常恐怖,对空间要求很高。因此针对这个问题,我对工具主要进行了两个修改:
- 利用logstash的插件直接将json输出到本地文件,删掉了grafana
- 参考engagement3的数据格式重写logstash过滤器,对字段进行了删减和修改,剔除不必要字段。
修改之后的工具包放到了我的github-TC_Tool_modified,开源不易,记得star一下,感激不尽!
1.1 文件树介绍

| 文件 | 内容 |
|---|---|
| theia | 存放原始数据的文件夹 |
| elasticsearch | 数据库,已经不需要了,但是logstash以来这个数据库,所以还是保留了 |
| logs | 存放json文件的地方 |
| logstash | 日志收集器,负责收集解压出来的log4j日志,然后输出到本地文件 |
| docker-compose.yml | 镜像的配置文件 |
| TCCDMDatum.avsc | 一个模式文件,用于规范化数据格式,负责从log到json的转换 |
| tc-das-importer-1.0-SNAPSHOT-jar-with-dependencies.jar | 官方的java包,用于解压、读取并参考上述数据规范生成标准格式的数据通过socket发送 |
1.2 可修改配置
1.2.1 elastic search的内存限制(非必要)
在docker-compose.yml中存在对于elasticsearch的内存限额,如果1G对于你的机器存在负担,可以尝试改为512、256等。

1.2.2 初始日志输出地址
我们可以通过命令java -Dlog4j.debug=true -cp .:tc-das-importer-1.0-SNAPSHOT-jar-with-dependencies.jar main.java.com.bbn.tc.DASImporter [原属数据路径] [模式文件路径] [输出IP] [输出端口] -v启动对于原始日志的解压和解析,启动前确保已有JAVA环境且logstash已成功启动。如果你采用C/S模式,这里的IP和端口可以修改为需要的地址。
1.2.3 初始日志接收地址
logstash负责接收Java包发送来的日志进行处理和输出到本地文件,可修改的的东西主要为4个:
-
docker-compose.yml中挂载的本地路径。

-
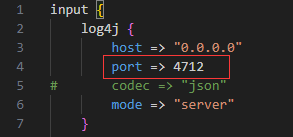
logstash/pipline/logstash.conf中的监听端口。如果有修改发送地址,此处也应该修改为对应的端口
-
logstash/pipline/logstash.conf中的过滤器。如果有额外需求,可以通过修改过滤器对字段进行调整
filter {json {source => "message"}mutate {//移除不必要字段remove_field=>["message","timestamp","file","@version","path","thread","host","method","priority","logger_name","class"]}//转换时间格式mutate {convert => {"[datum][com.bbn.tc.schema.avro.cdm20.Event][timestampNanos]" => "string"}}mutate {gsub => ["[datum][com.bbn.tc.schema.avro.cdm20.Event][timestampNanos]", "\d{6}$", ""]}date {match => ["[datum][com.bbn.tc.schema.avro.cdm20.Event][timestampNanos]", "UNIX_MS"]timezone => "America/New_York"locale => "en" target => "@timestamp"}
}
- logstash/pipline/logstash.conf中的输出文件的命名规则。为了避免单个文件过大,这里采用以小时为单位的时间格式命名。注释掉的输出方式为控制台输出,可以打开用以观察是否正常接收到数据,正式转换时再注释掉。

1.3 启动方式
在TC_Tool_modified/目录下使用docker-compose up -d启动日志接收器。需要docker环境和docker-compose包。
在任何目录下使用1.2.2中的命令格式启动日志解析器。如:
java -Dlog4j.debug=true -cp .:tc-das-importer-1.0-SNAPSHOT-jar-with-dependencies.jar main.java.com.bbn.tc.DASImporter ./theia/ ./TCCDMDatum.avsc 127.0.0.1 4712 -v
2. java-consumer
下载工具包ta3-java-consumer.tar.gz并解压。
参考根目录下的README进行安装。
在ta3-java-consumer\tc-bbn-kafka目录下新建一个python脚本,如bin2json.py,粘贴如下代码进去,修改其中的bin_path为.bin文件的绝对地址,注意一定要是绝对地址,然后运行该脚本等待转换完成即可。
import os
import time
# the path of .bin files
bin_path="/media/njust3001/disk/TC_e5/theia/"
dir_list=os.listdir(bin_path)
# print(len(dir_list))for cur_file in dir_list:# gets the absolute pathpath=os.path.join(bin_path,cur_file)# print(path)command="./json_consumer.sh "+pathos.system(command)time.sleep(10)print("susseful convert "+curfile)本质上是能够通过./json_consumer.sh [filepath]直接运行的,但是后面的参数不能是文件夹只能是具体文件,所以额外写了脚本。转换出来的json文件默认在ta3-java-consumer\tc-bbn-kafka目录下,该工具包是支持自定义路径的,有需要可以自行研究。
这篇关于DARPA TC-e3/e5数据集bin转json的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





