本文主要是介绍随机访问文件类的使用(RandomAccessFile)与流的使用规律,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、RandomAccessFile
RandomAccessFile是Java中输入,输出流体系中功能最丰富的文件内容访问类,它提供很多方法来操作文件,包括读写支持,与普通的IO流相比,它最大的特别之处就是支持任意访问的方式,程序可以直接跳到任意地方来读写数据。
如果我们只希望访问文件的部分内容,而不是把文件从头读到尾,使用RandomAccessFile将会带来更简洁的代码以及更好的性能。
1、继承关系
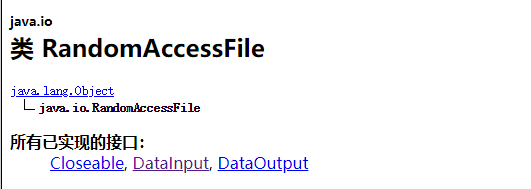
可以看到它的父类是Object,没有继承流中任何一个类。
并且它实现了DataInput、DataOutput这两个接口,也就意味着这个类既可以读也可以写。
2、构造方法
-
创建从中读取和向其中写入(可选)的随机访问文件流,该文件具有指定名称。

-
创建从中读取和向其中写入(可选)的随机访问文件流,该文件由 File 参数指定。

访问模式mode:
- r:(reader) 当前文件支持读操作
- rw:当前文件支持读写操作
- rws:支持读写操作,并且将文件内容和元数据同步到存储介质
- rwd:支持读写操作,并且将文件内容同步到存储介质
3、主要方法
-
long getFilePointer():返回文件记录指针的当前位置
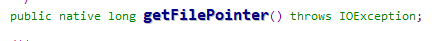
从源码中可以看到它是一个native方法
返回的是到此文件开头的偏移量(以字节为单位),在该位置发生下一个读取或写入操作。 -
void seek(long pos):将文件指针定位到pos位置

设置到此文件开头测量到的文件指针偏移量,在该位置发生下一个读取或写入操作。偏移量的设置可能会超出文件末尾。
偏移量的设置超出文件末尾不会改变文件的长度,只有在偏移量的设置超出文件末尾的情况下对文件进行写入才会更改其长度。
pos: 从文件开头以字节为单位测量的偏移量位置,在该位置设置文件指针。
4、方法使用示例
- 随机位置进行读取数据
public static String seek(String path,long n) throws IOException {//创建流RandomAccessFile randomAccessFile = new RandomAccessFile(path,"rw");//将文件指针定位到指定位置randomAccessFile.seek(n);byte[] bytes = new byte[50];int read = randomAccessFile.read(bytes);//关闭流randomAccessFile.close();return new String(bytes,0,read);}
- 在文件尾进行追加数据
思路:RandomAccessFile先获取文件的长度,再将指针移到文件的末尾,然后将要插入的内容插入到文件
public static void append(String path,String s) throws IOException {RandomAccessFile randomAccessFile = new RandomAccessFile(path,"rw");randomAccessFile.seek(randomAccessFile.length()); //将指针调到文件尾randomAccessFile.write(s.getBytes()); //写入要追加的字符串randomAccessFile.seek(0);//将指针挪到开始进行读取文件数据byte[] bytes = new byte[100];int read = randomAccessFile.read(bytes);System.out.println(new String(bytes,0, read));randomAccessFile.close();}
- 指定位置插入数据
思路:RandomAccessFile如果向文件的指定的位置插入内容,则新输出的内容会覆盖文件中原有的内容。
如果需要向指定位置插入内容,程序需要先把插入点后面的内容读入缓冲区,
等把需要的插入数据写入文件后,再将缓冲区的内容追加到文件后面
/*** 任意位置插入数据* @param path 路径* @param dos 插入位置* @param content 要插入的数据*/public static void randomWrite(String path, int dos, String content) {try {RandomAccessFile accessFile = new RandomAccessFile(path, "rw");if (dos < 0 ) return;File tempFile = File.createTempFile("tmp", null);tempFile.deleteOnExit();FileOutputStream outputStream = new FileOutputStream(tempFile);FileInputStream inputStream = new FileInputStream(tempFile);//定位到指定位置,将指定位置之后的内容读到零时文件里accessFile.seek(dos);int i ;//将accessFile内容读到零时文件while ((i = accessFile.read()) != -1) {outputStream.write(i);}//重新定位到指定位置,将要插入的内容直接写入accessFile文件accessFile.seek(dos);//写内容accessFile.write(content.getBytes());//指针移动到最后位置,进行内容追加accessFile.seek(accessFile.length());//将零时文件内容写回到accessFile文件while ((i=inputStream.read()) != -1) {accessFile.write(i);}accessFile.close();inputStream.close();outputStream.close();} catch (IOException e) {e.printStackTrace();}}
二、流的使用规律
这几天我差不多将常用的流的方法与使用都研究完了,发现它们的使用规律都是一样的,再使用时有一定的规律,为了以后方便回忆,就总结一下啦
1、明确是读操作还是写操作(数据源是当前程序或者数据目的地是当前程序)
- 读:InputStream/Reader
- 写:OutputStream/Writer
2、明确是操作字节还是字符 - 读:
- 字节:InputStream
- 字符:Reader
- 写:
- 字节:OutputStream
- 字符:Writer
(明确操作基类)
3、操作的具体介质
- 读:
- 文件:File
- 内存:char、array、double
- 网络:Socket
- 键盘:System.in
- 写:
- 文件:File
- 内存:char、array
- 网络:Socket
- 屏幕:System.out
(明确操作的具体类)
4、明确是否需要额外操作 - 缓冲区:BufferXXX
- 转换流:InputStreamReader、OutputStreamWriter
这篇关于随机访问文件类的使用(RandomAccessFile)与流的使用规律的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




